云HBase X-Pack是基于Apache HBase、Phoenix、Spark深度扩展,融合Solr检索等技术,支持海量数据的一站式存储、检索与分析。融合云Kafka+云HBase X-Pack能够构建一体化的数据处理平台,支持风控、推荐、检索、画像、社交、物联网、时空、表单查询、离线数仓等场景,助力企业数据智能化。
方案架构
下图是业界广泛应用的大数据中台架构。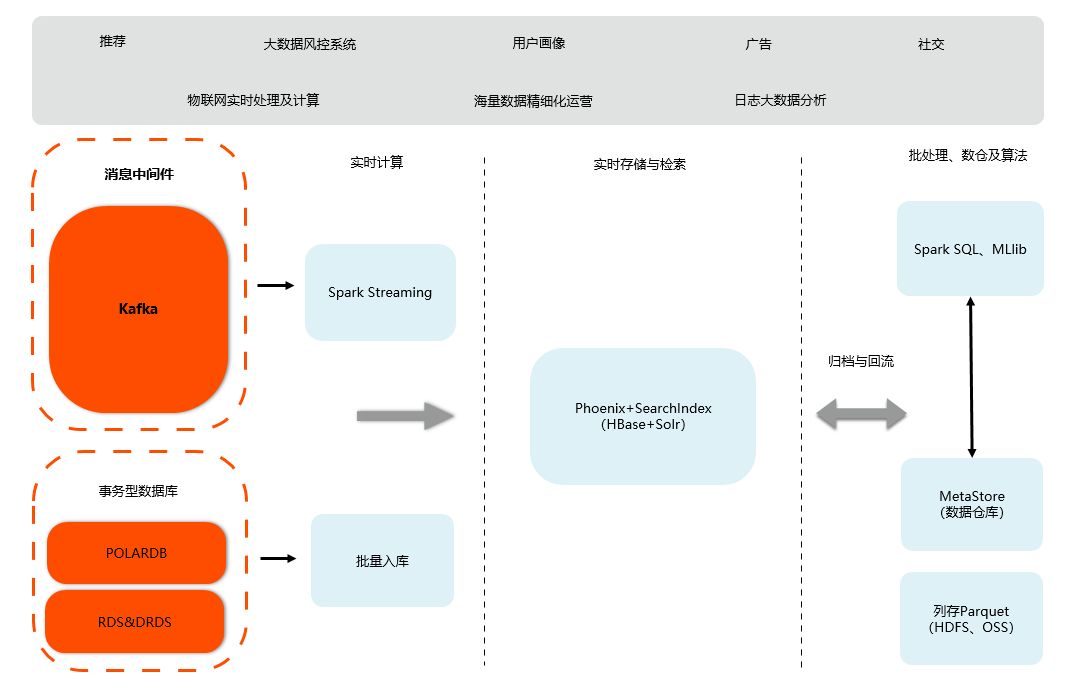
说明 其中HBase和Spark选择云HBase X-Pack。详情请参见X-pack Spark分析引擎。
- 消息流入:Flume、Logstash或者在线库的Binlog流入云消息队列 Kafka 版。
- 实时计算:通过X-Pack Spark Streaming实时地消费云消息队列 Kafka 版的消息,写入到云HBase中对外提供在线查询。
- 实时存储与检索:云HBase融合Solr以及Phoenix SQL层能够提供海量的实时存储,以及在线查询检索。
- 批处理、数仓及算法:在线存储HBase的数据可以自动归档到X-Pack Spark数仓。全量数据沉淀到Spark数仓(HiveMeta),做批处理、算法分析等复杂计算,结果回流到在线库对外提供查询。
更多信息
- 该套方案的实践操作,请参见Spark对接Kafka快速入门。
- 公有云HBase和Spark的示例代码,请参见Demo。