在当今的互联网业内,很多大型互联网系统,比如淘宝、支付宝、网商银行等,都已经实现了单元化架构,并从中获益匪浅,更多企业正加入其中。为什么要做单元化,单元化架构能给系统带来什么样的能力。本文结合蚂蚁集团支付宝系统的单元化架构建设实践,阐释单元化的原理与实现。
单点瓶颈
任何一个互联网系统,不论是支付宝、淘宝,还是 Google、Facebook,当发展到一定规模时,都会不可避免地触及到单点瓶颈。这里所说的“单点”,在系统的不同发展阶段表现不同。
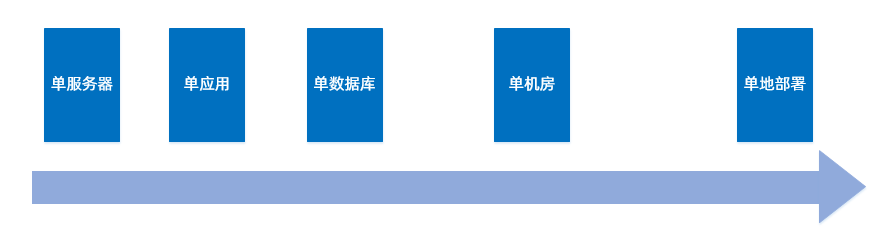
服务器和应用单点
在系统发展初期,服务器和应用单点最先成为瓶颈,解决的方法也很简单,加机器、拆应用。
数据库单点
紧接着数据库单点,解决起来就开始不那么容易了,典型的做法是先垂直拆分,再水平拆分,在这个过程中需要解决多数据源、数据分片、透明访问等问题。
机房单点
当应用越来越多、服务器越来越多、数据库越来越多,单个机房的容量开始捉襟见肘,装不下这么多服务器。而且业务量的增长也让系统单机房运行的风险激增,一旦发生机房断电或是其他灾害导致机房故障,就会让整个系统完全瘫痪。机房不能放在一个篮子里,必须让系统在两个或更多 IDC 内运行。
多机房部署通常有以下两种模式:
垂直模式:将全站应用、数据库等划分为几个部分,分别放在不同的机房中,完成一个业务可能需要不同机房中的不同应用提供服务。这就相当于在逻辑层面将一个物理机房放大了,机房容量不足的问题得以解决。
水平模式:每个机房中部署的应用都是相同的,每个机房都有完成全站所有业务的能力,在运行时每个机房都只承担整站的一部分业务流量。
从具体实现角度来看,垂直模式更容易些,能够突破机房容量瓶颈,但不具备容灾能力。而容灾,是一个发展到一定规模的互联网系统的重要诉求,更是金融场景和金融业务必不可少的基础能力,因此在具体实践中,大多数大型系统都采用多机房水平扩展的模式。
单地部署
上面所说的容灾问题,对于一个有着亿级用户的系统,或一个数据系统来说尤为重要,仅仅是机房级容灾还不够,必须要考虑部署地容灾,也就是说不能把所有机房部署在地理上临近的地区,以防发生地震、海啸、核爆等剧烈灾害而导致系统被毁灭性破坏。这类系统的典型代表是银行、第三方支付等金融类系统,比如银行就对机房部署有着经典的“两地三中心”要求。于是,单地部署开始成为制约业务发展的瓶颈。
将系统的某个部分部署到距离较远的另外一个地区(城市)的能力,是大型互联网系统走向成熟的标志。多地部署本质上和多机房部署是一样的,面临的问题也几乎一样,除了距离问题。表象上是距离,下面隐藏着的是延时,更远的距离意味着更长的延时,个位数毫秒的延时不会给系统带来什么麻烦,但一旦这个数值变成几十毫秒,量变就引发了质变,很多业务开始不能忍受和忽略延时带来的影响。
单元化
多地多机房部署,是互联网系统的必然发展方向,一个系统要走到这一步,也就必然要解决上面提到的问题:流量调配、数据拆分、延时等。业界有很多技术方案可以用来解决这些问题,而承载这些方案的,是一个部署架构。尽管可采用的部署架构不止一个,但不论是纯理论研究,还是一些先行系统的架构实践,都把“单元化部署”推崇为最佳方案。
单元(即单元化应用服务产品层的部署单元),是指一个能完成所有业务操作的自包含集合,在这个集合中包含了所有业务所需的所有服务,以及分配给这个单元的数据。单元化架构就是将单元作为部署的基本单位,在全站所有机房中部署多个单元,每个机房内单元数目不固定,任一单元均部署系统所需的全部应用,数据则是全量数据按照某种维度划分后的一部分。
传统意义上的 SOA 化(服务化)架构,服务是分层的,每层的节点数量不尽相同,上层调用下层时,随机选择节点。
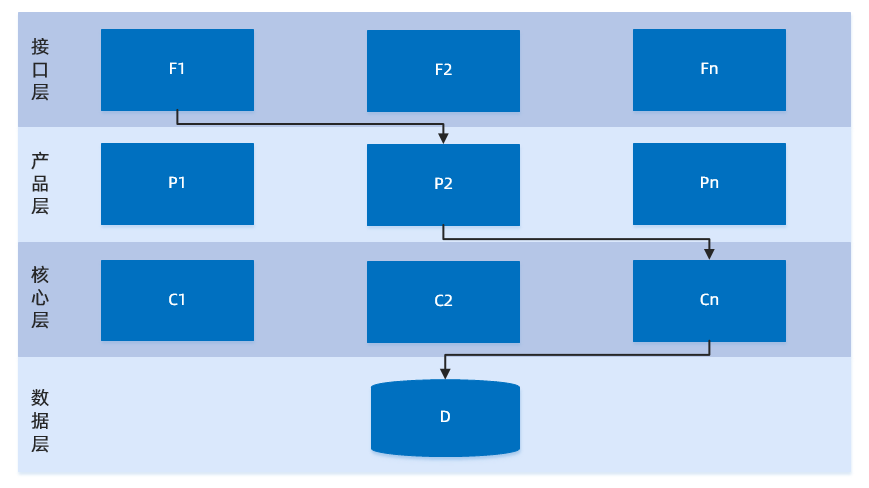
单元化架构下,服务仍然是分层的,不同的是每一层中的任意一个节点都属于且仅属于某一个单元,上层调用下层时,仅会选择本单元内的节点。
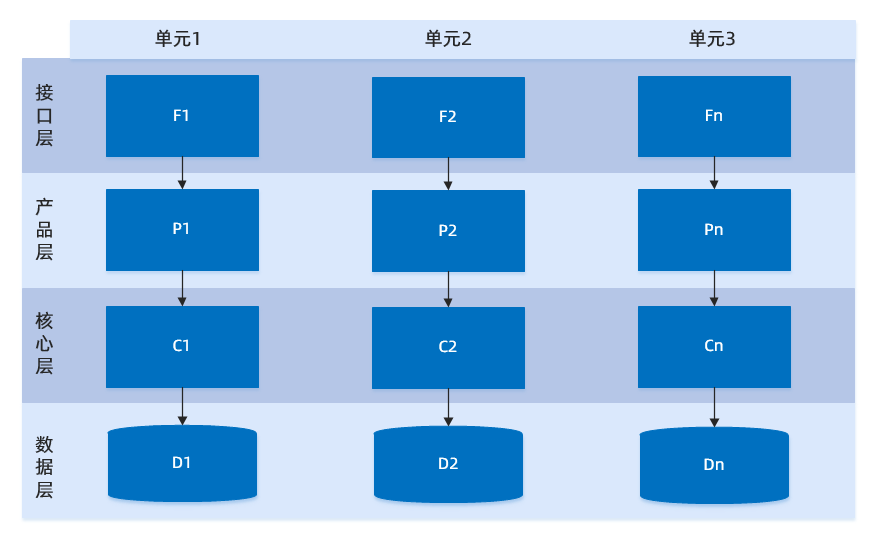
一个单元,是一个五脏俱全的缩小版整站,它是全能的,因为部署了所有应用;但它不是全量的,因为只能操作一部分数据。能够单元化的系统,很容易在多机房中部署,因为可以轻松将多个单元部署在一个机房内,而将另外几个单元部署在其他机房内。通过在业务入口处设置一个流量调配器,可以调整业务流量在单元之间的比例。
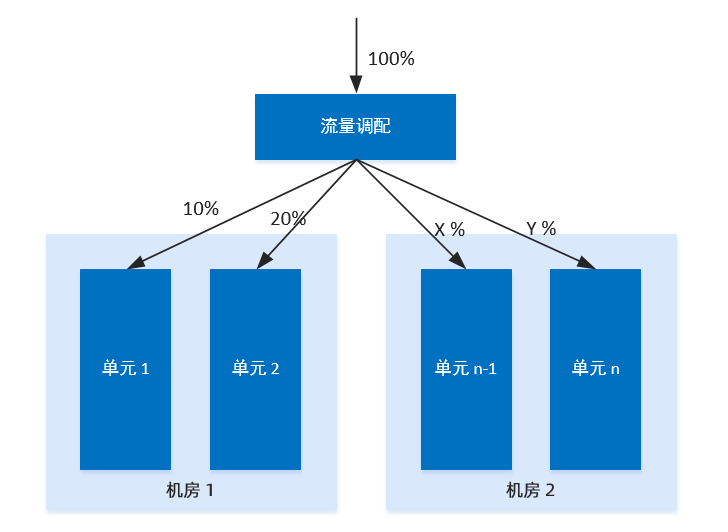
从上述对单元的定义和特性描述中,可以推导出单元化架构要求系统必须具备的一项能力:数据分区,实际上正是数据分区决定了各个单元可承担的业务流量比例。数据分区(shard),即是将全局数据按照某一个维度水平划分开来,每个分区的数据内容互不重叠,这也就是数据库水平拆分所做的事情。
仅把数据分区了还不够,单元化的另外一个必要条件是,全站所有业务数据分区所用的拆分维度和拆分规则都必须一样。若是以用户分区数据,那交易、收单、微贷、支付、账务等全链路业务都应该基于用户维度拆分数据,并且采用一样的规则拆分出同样的分区数。比如,以用户 id 末 2 位作为标识,将每个业务的全量数据都划分为 100 个分区(00-99)。
有了以上两个基础,单元化才可能成为现实。把一个或几个数据分区,部署在某个单元内,这些数据分区占总量数据的比例,就是这个单元能够承担的业务流量比例。 执行数据分区时一个很重要的问题是分区维度的选择,一个好的维度,应该:
粒度合适:粒度过大,会丧失流量调配的灵活性和精细度;粒度过小,会给数据的支撑资源,访问逻辑带来负担。
足够平均:按这个分区维度划分后,每个部署单元的数据量应该是几乎一致的。
以用户为服务主体的系统(很多面向用户的系统,比如支付宝)通常可以按用户维度对数据分区,这是一个最佳实践。
逻辑单元
逻辑单元是单元化架构的基础,一个单元被称为一个 Zone。根据业务特点不同,您可以将系统部署在不同类型的逻辑单元中。更多信息,请参考 创建逻辑单元。
- 本页导读 (0)