除了通过JSON文件来创建数据集的方式,如果您暂时没有标注数据,也可以通过我们的标注平台来标注数据。
接下来,通过一个例子来演示标注平台的使用。在第一步创建刚刚创建好的项目中,选择创建标注任务
注意:目前仅支持UTF-8编码方式的数据文件
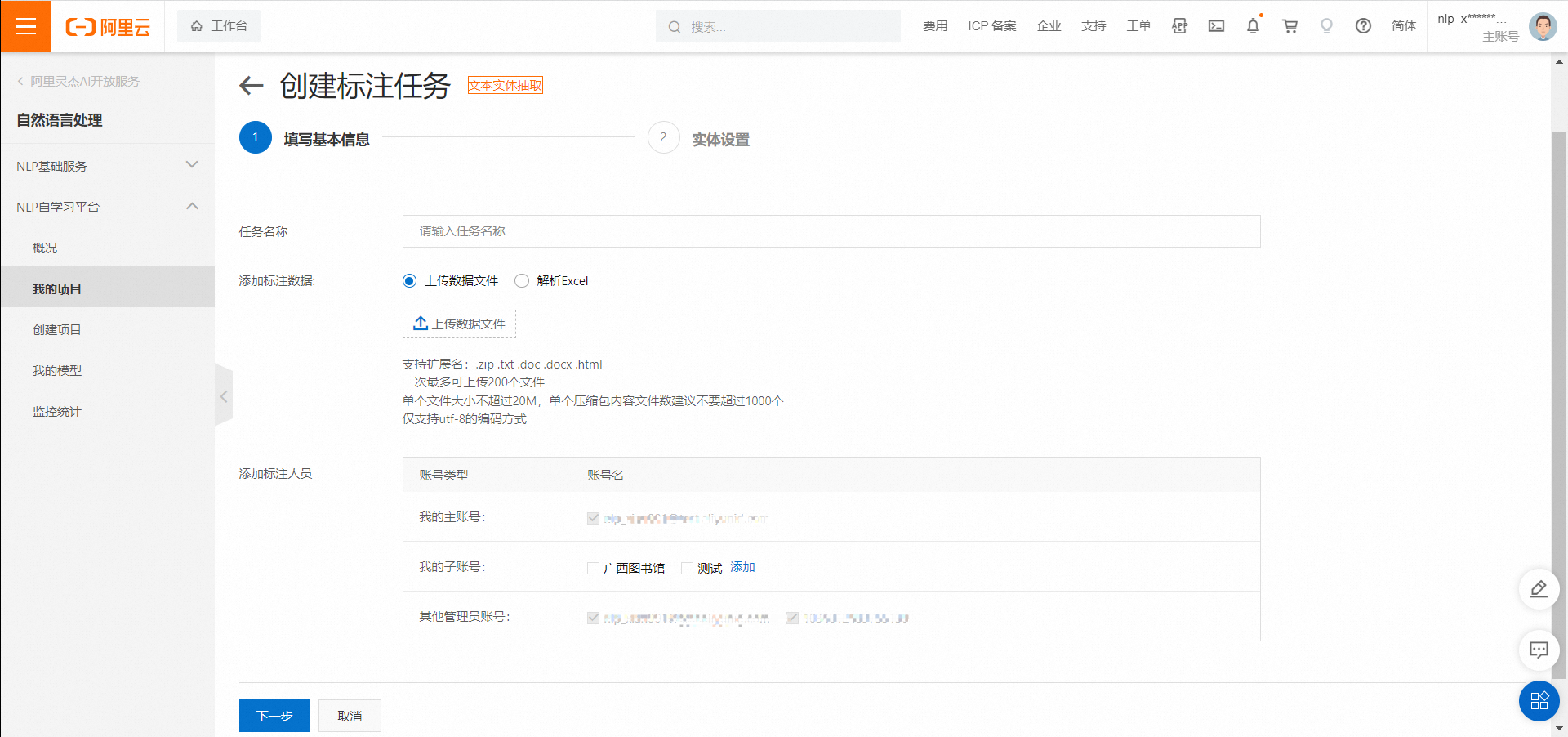
填写数据集的名称后,您需要上传待标注的原始数据文件。上传完成后点击下一步,进入实体名称的设置页面,点击添加实体,输入您需要抽取的实体的名称,如下:
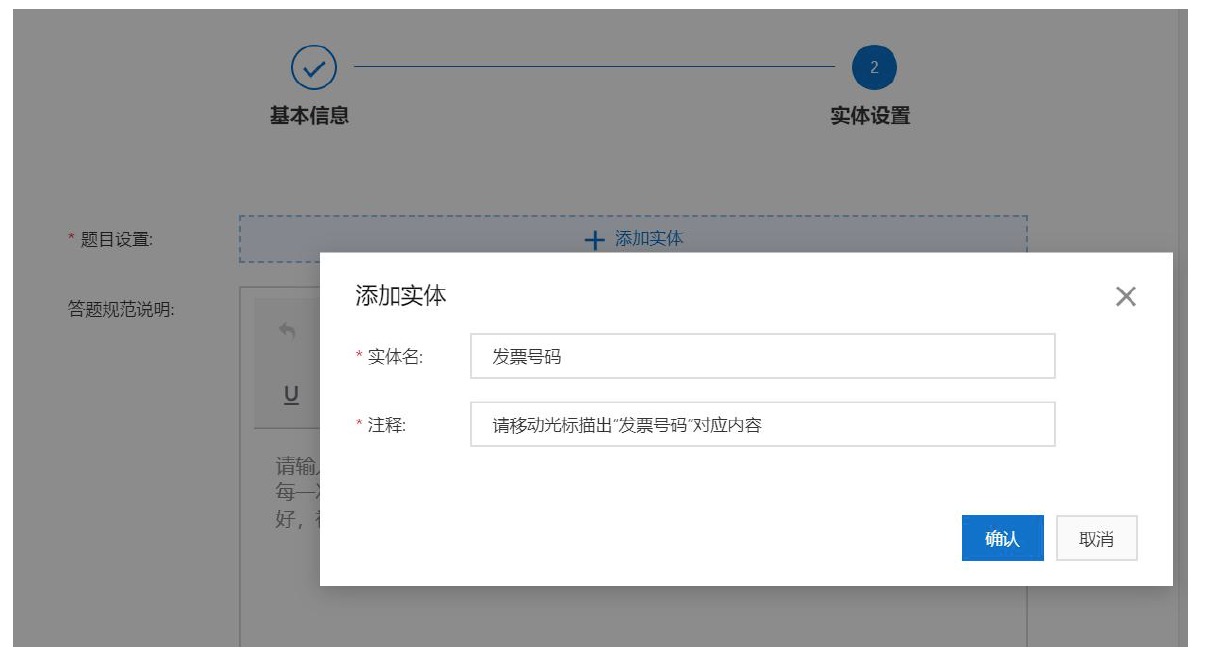
多次点击“添加实体”按钮,直至所有需要抽取的实体都显示在右边栏,点击提交即可。待上传的数据集解析完毕后即可标注,之后按照页面提示进行数据的标注即可。
标注规范
需要对待标注文档中所有出现的实体予以标注。(建议打开左上角的“同值标注” 功能)
某文档中对某个实体已经有过标注了,在另一篇文档中还需要对相同实体进行标注吗?答:需要。
被标注的实体中不能出现换行符“\n”或句号“。”,否则将不能识别,但不会影响训练。
常见问题
当构建好数据集后,模型就可以开始学习。需要知道的是模型所有的知识都来源于您输入的这个数据集,它不具备任何的先验知识。模型做出的所有判断都是依据从这个训练数据集中学到的知识,因此它不可能做出它认知外的判断。
常见的用户遇到的问题如:
我需要从一句话中抽出一个金额,于是我标注了500句包含这个金额的句子。但是我测试模型效果时可以使用一整篇文章吗?文章中有一句话包含待抽取的实体。
答:不可以。测试文本和训练文本需要保持一致,因此,测试时也要用一句话去测试。或者构造训练数据时也选用完整的文章。
我有一整段裁判文书,需要从某一句话推理得到审判结果,可以通过标出这些话抽取推理得到答案吗?
答:实体抽取目前支持的是内容较短的完整文本,并且不做推理。如果标注的内容是成多句或是成段的,建议您选择其它的项目/解决方案看看能否解决您的问题。
标注太累了,我需要抽取的文本有好几种格式,能不能只标一种,能不能先标几条测测效果?
答:标注的数据越多且越多样,模型的泛化性能就会越好,如果您希望模型具备好的性能,标注数据这一关是必不可少的。我们不建议标几条数据试试效果,因为极少的样本模型是学不到规律的,因此不会有好的效果。另外,如果您有多个类型的样本,建议您每个类型都标一些,而不是只标一个类型。这样也能提升模型的稳定性和准确率。
- 本页导读 (0)