使用Spark计算引擎访问表格存储时,您可以通过E-MapReduce SQL或者DataFrame编程方式对表格存储中数据进行复杂的计算和高效的分析。
应用场景

功能特性
对于批计算,除了基础功能外,Tablestore On Spark提供了如下核心优化功能:
索引选择:数据查询效率的关键在于选择合适的索引方式,根据过滤条件选择最匹配的索引方式增加查询效率。表格存储的索引方式可选全局二级索引或者多元索引。
说明全局二级索引和多元索引的更多信息请参见海量结构化数据存储技术揭秘:Tablestore存储和索引引擎详解。
表分区裁剪:根据过滤条件进行逻辑分区(Split)的细化匹配,提前筛选出无效的Split,降低服务端的数据出口量。
Projection和Filter下推:将Projection列和Filter条件下推到服务端,降低每个分区的数据出口量。
动态指定Split大小:支持调整每个逻辑分区(Split)中的数据量和分区数,每个Split会和RDD(Resilient Distributed DataSet)的Partition绑定,可用于加速Spark任务的执行。
说明通过ComputeSplitsBySize接口可以获取逻辑分区(Split),该接口将全表数据在逻辑上划分成若干接近指定大小的分片,并返回这些分片之间的分割点以及分片所在机器的提示。一般用于计算引擎规划并发度等执行计划。
对于流计算,基于通道服务,利用CDC(数据变更捕获)技术完成Spark的mini batch流式消费和计算,同时提供了at-least-once一致性语义。在流计算中每个分区和RDD的Partition一一绑定,通过扩展表的分区,可以完成数据吞吐量的线性扩展。
场景案例
使用方式
根据业务场景可以选择通过E-MapReduce SQL或者DataFrame编程方式使用Spark访问表格存储。
E-MapReduce SQL方式
此方式使用标准的SQL语句进行业务数据操作和访问,操作便捷,可以将已有的业务逻辑进行无缝迁移。
DataFrame方式
此方式需要一定的编程基础,但可以组合实现复杂的业务逻辑,适用于比较复杂和灵活的场景。
数据访问方式
表格存储为Spark批计算提供KV查询(数据表或全局二级索引)和多元索引查询两种数据访问方式,以支持海量结构化数据快速读写和丰富的查询分析能力。
两种数据访问方式的区别如下:
KV查询方式在过滤字段是主键的场景下效率较高,但不适合过滤字段变动较大且过滤字段中非主键列较多的场景,KV查询方式也不支持地理位置查询。
多元索引查询方式适用于如下数据访问场景中:
说明多元索引基于倒排索引和列式存储,可以解决大数据的复杂查询难题,提供类似于ElasticSearch的全文检索、模糊查询、地理位置查询、统计聚合等查询和分析功能。
少量且对延时要求较高的实时数据分析场景。
非主键的过滤字段较多,过滤字段无法被全局二级索引主键或者数据表主键包含。
过滤字段的筛选效率较高,可以通过某一字段条件过滤掉大部分数据。
例如
select * from table where col = 1000;中,col是非主键列,且col = 1000字段条件可以过滤掉大部分数据。查询条件中包含地理位置查询。
结合下图以select * from table where col1 like '阿%' or col2 = 'a';SQL语句为例介绍两种查询方式的使用样例。
通过多元索引方式访问数据时,在多元索引的col1中可以获取col1的值为'阿%'的一行数据pk1 = 1,在多元索引的col2中可以获取col2的值为'a'的两行数据pk1 = 1和pk1 = 2,然后将两次中间结果的数据进行union,即可得到满足条件的数据
pk1 = 1,col1 = '阿里云',col2 = 'a'。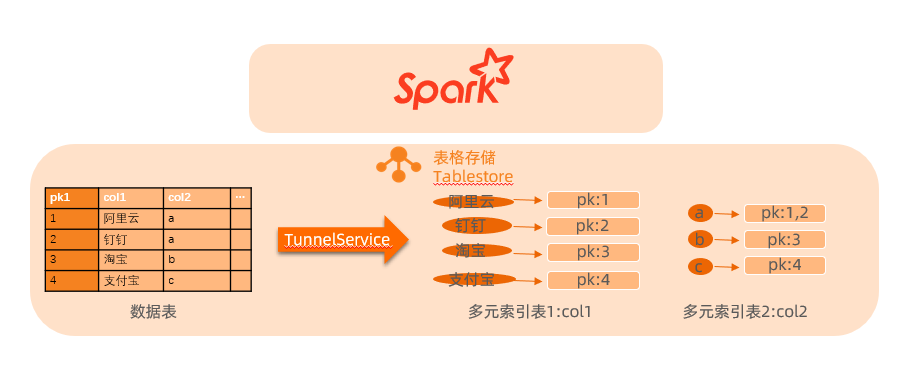
通过KV查询方式访问数据时,查询主体是表格存储的数据表,数据表只能通过主键查询。如果查询的SQL语句中的过滤字段不是数据表的主键,则需要进行全表扫描。
由于col1不是数据表的主键,表格存储会进行全表扫描找到col1的值为'阿%'的一行数据;由于col2不是数据表的主键,表格存储会再次进行全表扫描找到col2的值为'a'的两行数据,然后将两次中间结果的数据进行union。
此时也可以通过构建一个主键为col1、col2的索引表支持该查询,但此种方式的灵活性较低。
- 本页导读 (1)