本文对Multi-Master架构的关键技术点进行介绍,包括分布式事务处理、全局死锁处理、DDL支持、分布式表锁支持、集群容错和高可用能力。
分布式事务管理
- AnalyticDB PostgreSQL版分布式事务
AnalyticDB PostgreSQL版通过二阶段提交协议(2PC)来实现分布式事务,同时使用了分布式快照来保证Master和不同Segment间的数据一致性。
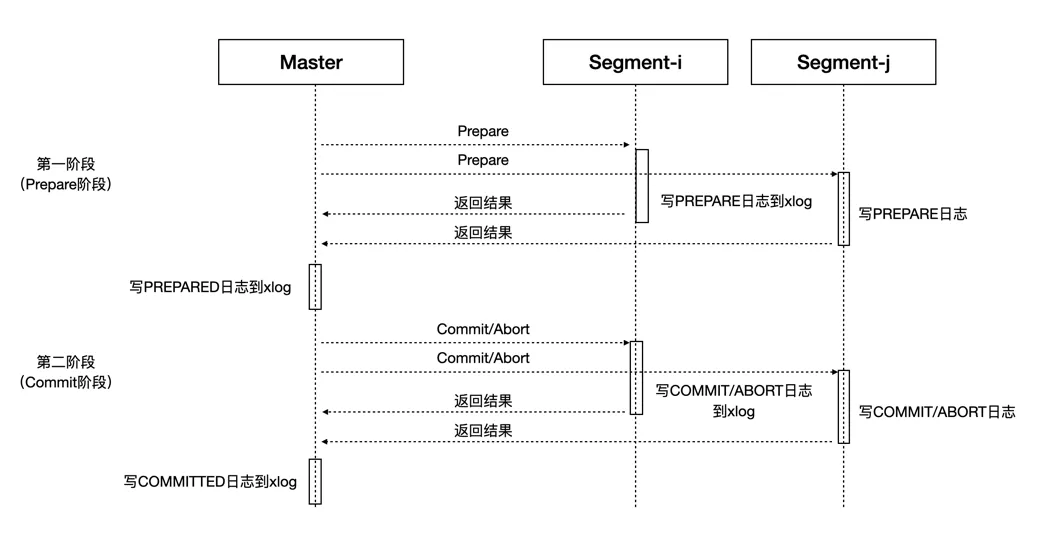
分布式事务由Main Master发起,通过2PC协议提交到Segment。2PC协议将整体事务的提交过程拆分成了Prepare和Commit/Abort两个阶段,如上图所示,只有参与事务的所有Segment都成功提交整体事务才会成功提交。如果在第一阶段有存在Prepare失败的Segment,则整个事务会终止;如果在第二阶段有Commit失败的Segment,而且Master已经成功记录了PREPARED日志,则会发起重试。如果一个事务仅牵涉1个Segment,系统会按照1PC的方式来提交事务从而提升性能。1PC协议中Master参与协调的Prepare和Commit两个阶段将合二为一,最终由唯一参与的Segment来保证事务执行的原子性。
Main Master上的GTM全局事务管理组件会维护全局的分布式事务状态,每一个事务都会产生一个新的分布式事务ID、设置时间戳及相应的状态信息,在获取快照时,创建分布式快照并保存在当前快照中。以下是分布式快照记录的核心信息:
typedef struct DistributedSnapshot { DistributedTransactionTimeStamp distribTransactionTimeStamp; DistributedTransactionId xminAllDistributedSnapshots; DistributedSnapshotId distribSnapshotId; DistributedTransactionId xmin; /* XID < xmin 则可见 */ DistributedTransactionId xmax; /* XID >= xmax 则不可见 */ int32count; /* inProgressXidArray 数组中分布式事务的个数 */ DistributedTransactionId *inProgressXidArray; /* 正在执行的分布式事务数组 */ } DistributedSnapshot;执行查询时,Main Master将分布式事务和快照等信息序列化,通过libpq协议发送到Segment执行。Segment反序列化后,获得对应分布式事务和快照信息,并以此为依据来判定查询到的元组的可见性。所有参与该查询的Segment都使用同一份分布式事务和快照信息判断元组的可见性,从而保证整个实例数据的一致性。同时,AnalyticDB PostgreSQL版提供了本地事务和分布式事务提交缓存,用以帮助快速查询本地事务ID(XID)和分布式全局事务ID(GXID)的映射关系。
说明 AnalyticDB PostgreSQL版会保存全局事务的提交日志,用以判断某个事务是否已经提交。
如上图所示,Txn A在插入一条数据后,Txn B对该数据进行了更新。基于PostgreSQL的MVCC机制,当前Heap表中会存在两条对应的记录,Txn B更新完数据后会将原来元组(Tuple)对应的xmax改为自身的本地XID值(由0改为4)。此后,Txn C和Txn D两个查询会结合自己的分布式快照信息来做可见性判断,具体规则如下:
- 如果GXID的值小于
distribedSnapshot->xmin,则元组可见。 - 如果GXID的值大于
distribedSnapshot->xmax,则元组不可见。 - 如果
distribedSnapshot->inProgressXidArray包含GXID的值,则元组不可见。 - 如果
distribedSnapshot->inProgressXidArray不包含GXID的值,则元组可见。
如果不能根据分布式快照判断可见性,或者不需要根据分布式快照判断可见性,则使用本地快照信息判断,判断逻辑与原生PostgreSQL的判断可见性逻辑一致。
基于上述规则,Txn C查到两条元组记录后,通过XID和GXID映射关系找到两条记录对应的GXID值(分别为100, 105),规则会限定Txn B的更新对Txn C不可见,所以Txn C查询到的结果是
foo;而Txn D基于规则则对Txn B更新后的Tuple可见,所以查询到的是bar。 - 如果GXID的值小于
- Multi-Master分布式事务
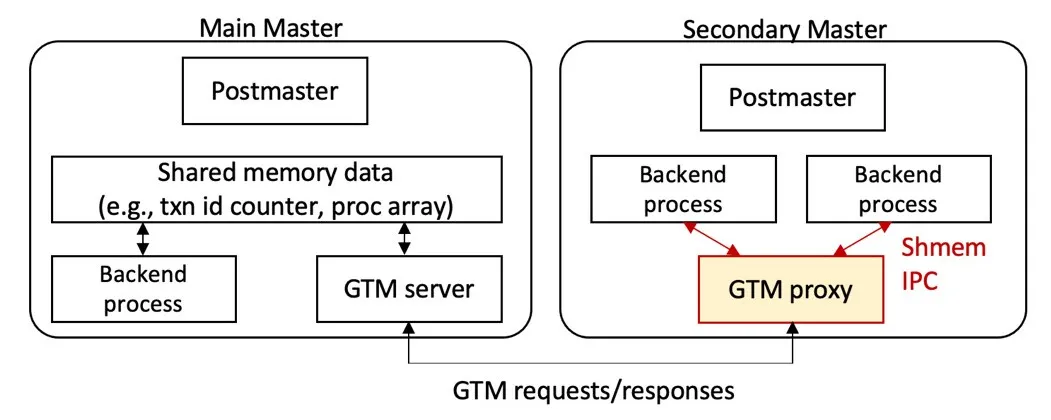
Multi-Master的分布式事务是在原有分布式事务基础之上进行了增强。如上图所示,Postmaster是守护进程,Main Master的Backend业务处理进程和GTM Server之间通过共享内存通信,但Secondary Master是无法直接通过共享内存与Main Master上的GTM Server通信的,为此,AnalyticDB PostgreSQL版在Secondary Master和Main Master之间新增了一条通道并实现了一套GTM交互协议。
为了减少Secondary Master和Main Master之间的连接并提升网络通信效率,AnalyticDB PostgreSQL版新增了GTM Proxy来处理同一个Secondary Master上多个Backend进程的GTM请求。以下内容将从GTM交互协议、GTM Proxy和分布事务恢复三个方面来介绍Multi-Master分布式事务实现的技术细节。
- GTM交互协议
GTM交互协议是Secondary Master和Main Master之间事务交互的核心协议,协议的核心消息以及说明如下所示。
协议核心消息 说明 GET_GXID 分配GXID。 SNAPSHOT_GET 获取分布式快照。 TXN_BEGIN 创建新事务。 TXN_BEGIN_GETGXID 创建新事务,并分配GXID。 TXN_PREPARE 指定的事务完成2PC的PREPARE阶段。 TXN_COMMIT 提交指定的事务。 TXN_ROLLBACK 回滚指定的事务。 TXN_GET_STATUS 获取属于指定Master的所有事务状态信息。 GET_GTM_READY 检查GTM SERVER是否可服务正常事务请求。 SET_GTM_READY 设置GTM SERVER可服务正常事务请求。 TXN_COMMIT_RECOVERY Master恢复阶段提交指定的事务。 TXN_ROLLBACK_RECOVERY Master恢复阶段回滚指定的事务。 CLEANUP_MASTER_TRANS 恢复完时清除Master的剩余事务。 通过上表可以看出,消息的核心依旧是交换GXID、SNAPSHOT等信息,同时进行BEGIN、PREPARE、COMMIT、ABORT等事务操作。由于跨节点消息交互成本较高,考虑到OLAP用户的特点和需求,AnalyticDB PostgreSQL版配合协议提供了不同的一致性选项,从而让您可以在性能和一致性上进行权衡和选择。
- 会话一致:同一个会话满足可预期的一致性要求,包括单调读,单调写,读自己所写,读后写的一致性。
- 强一致:线性一致性,一旦操作完成,所有会话可见。也基于不同的一致性模式进行了定制和精简。
模式 事务类型 事务策略 是否保证原子性(A) 隔离级别(I) 是否保证持久性(D) 会话一致(更高性能) 跨Segment 2PC,共享本地快照 是 RU/RC(会话内) 是 单Segment 1PC,共享本地快照 是 RC 是 强一致(更完善的ACID保证) 跨Segment 2PC,分布式快照 是 RC,RR 是 单Segment 1PC,分布式快照 是 RC,RR 是 如果您需要更高的性能而对于一致性可以做出一定妥协,则可以选择会话一致模式,相比强一致,会话一致对协议交互进行了大幅度精简,仅仅保留了GET_GXID和GET_GXID_MULTI核心消息。
在会话一致模式下,Secondary Master只需要从Main Master获取全局的GXID信息,然后结合本地快照并配合重试及全局死锁检测(GDD)来独立处理事务,大幅度简化与Master之间的消息交互从而提升性能。
协议核心消息 说明 GET_GXID 分配GXID。 GET_GXID_MULTI 批量分配GXID。 - GTM Proxy
在Multi-Master架构中,GTM Proxy作为Postmaster的子进程来进行管理,优点如下:
- 无需新增角色,配套管控更简单。
- GTM Proxy和Backend之间天然认证和互信。
- GTM Proxy可以通过共享内存和Backend进程通信,相比Tcp Loopback更高效,既可以减少内存拷贝,也没有Network Stack开销。
每个GTM Proxy进程会和GTM Server建立一个网络连接,并会服务多个本地的Backend进程,将它们的GTM请求转发给GTM Server。GTM Proxy还针对性的做一些请求优化处理,例如:
- 多个Backend间共享Snapshot,从而减少Snapshot请求数。
- 合并和批量处理Backend的并发GTM请求。
- 批量获取GXID(会话一致)。
GTM Proxy是减少Secondary Master和Main Master之间连接并提升网络通信效率的关键。在使用过程中,如果您开启了强一致模式,AnalyticDB PostgreSQL版在Main Master上会默认开启GTM Proxy来代理Main Master上多个Backend进程与GTM Server之间的请求,从而进一步降低GTM Server的压力。
- 分布事务恢复
在很多场景下系统都需要进行恢复分布式事务操作,例如系统或Master重启;Main Master与Standby Master切换等。当不考虑Multi-Master架构时,恢复分布式事务可以简单划分为如下步骤:
- Main Master回放XLOG,找出所有已经就绪(Prepared)但是尚未提交(Committed)的事务。
- 命令所有Segment提交所有需要Committed的事务。
- 收集所有Segment上未Committed而且不在Main Master需要提交的事务列表中的事务,终止这些事务。
如果引入Multi-Master架构,则会出现一些新的问题,核心问题如下:
- 如何恢复Secondary Master发起的事务。
- Segment和Secondary Master上残留Prepared阶段的事务在Secondary Master或者Master重启等情况下如何恢复或清理等。
为了解决上述问题,AnalyticDB PostgreSQL版对二阶段事务的提交和分布式事务的恢复流程都做了增强,下图为二阶段事务提交的增强和Secondary Master被删除及第一次启动时对应的清理流程。
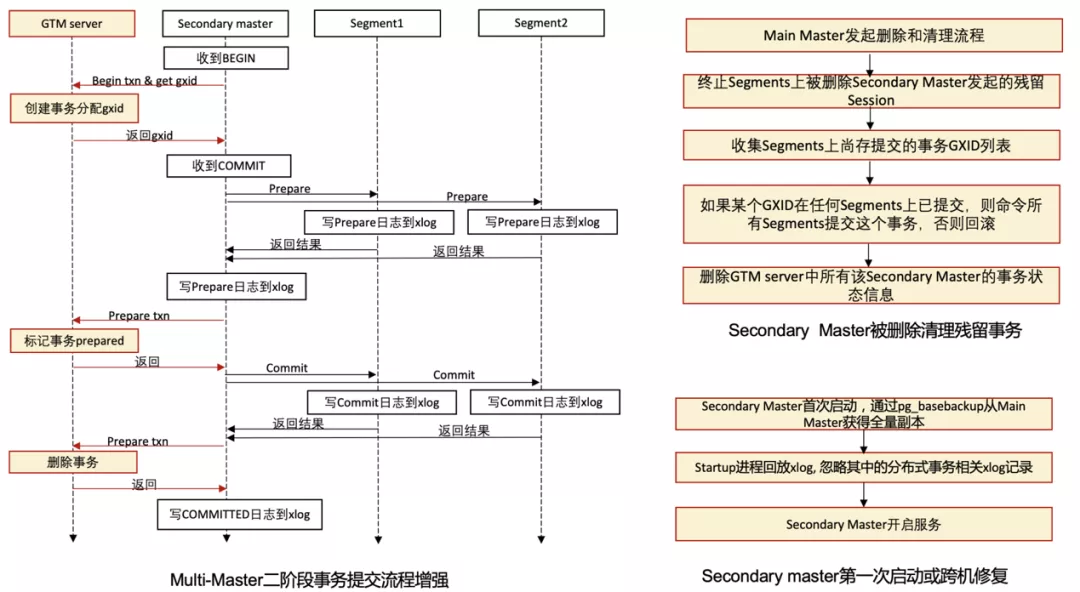
此外,AnalyticDB PostgreSQL版对Main Master和Secondary Master重启的流程也进行了增强,与单独Main Master重启恢复的差别在于需要区分出属于自己发起的分布式事务,区分方式通过增强GXID来实现。AnalyticDB PostgreSQL版在原本GXID的基本信息之上添加了MasterID信息,GXID和MasterID结合后,就可以基于GXID来区分出事务属于的Master。
- GTM交互协议
全局死锁检测
AnalyticDB PostgreSQL 4.3版是通过对表加写锁来避免执行UPDATE和DELETE时出现全局死锁,虽然这个方法避免了全局死锁,但是并发更新性能很差。AnalyticDB PostgreSQL 6.0版开始引入了全局死锁检测。该检测进程收集并分析集群中的锁等待信息,如果发现了死锁则结束造成死锁的进程来解除死锁,极大地提高了高并发情况下简单查询、插入、删除和更新操作的性能。
AnalyticDB PostgreSQL 6.0版实现全局死锁检测的特征如下:
- 全局死锁检测服务进程(GDD)运行在Main Master上。
- GDD会周期性获取所有Segment上的分布式事务的GXID及其等待关系。
- GDD会构造全局的事务等待关系图,检测是否成环。如果成环,则回滚环中一个事务,破解死锁。
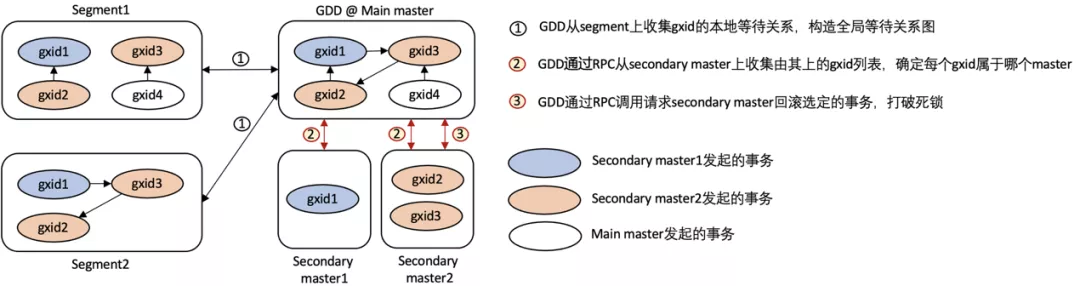
AnalyticDB PostgreSQL版Multi-Master新增了Get_gxids和Cancel_deadlock_txn的RPC调用,功能介绍如下:
- Get_gxids:从每个Secondary Master获取GXID列表,以判断导致死锁的事务属于哪些Master。
- Cancel_deadlock_txn:如果导致死锁的事务属于某个Secondary Master,则请求该Master回滚该事务。
DDL支持
在早期AnalyticDB PostgreSQL版中,是通过2PC的方式来实现Main Master的DDL支持以及与Segment上Catalog的修改同步。AnalyticDB PostgreSQL版Multi-Master扩展了这一功能来支持对Secondary Master上Catalog的同步。具体流程如下图所示。
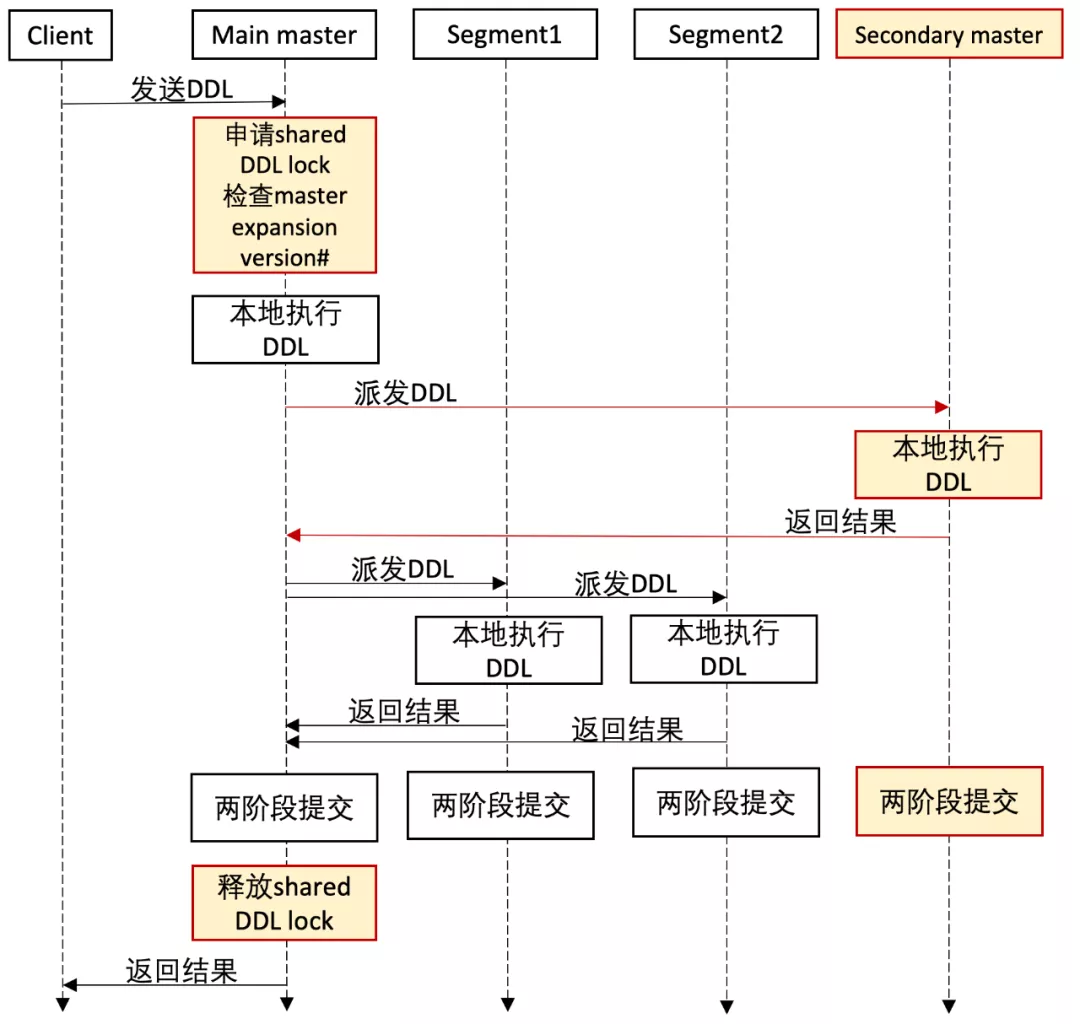
此外,Secondary Master也支持处理DDL,AnalyticDB PostgreSQL版在Secondary Master内部实现了一个简单的代理,Secondary Master如果收到DDL请求,会将请求转发给Main Master来处理。具体如下图所示。
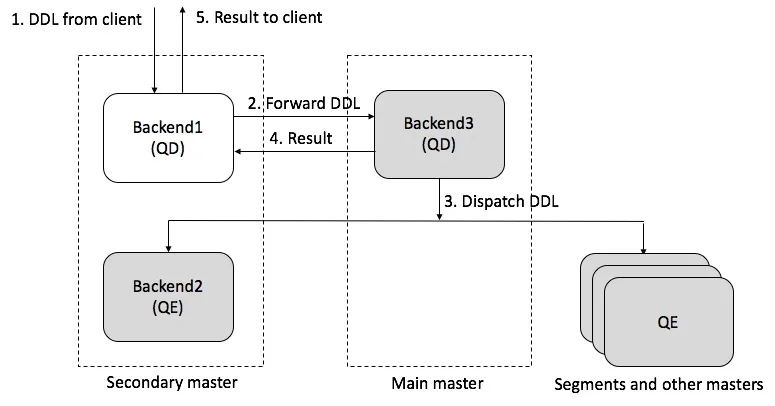
分布式表锁
在数据库中,并发访问表数据通常都是通过锁来实现的。AnalyticDB PostgreSQL版的锁模型与PostgreSQL锁模型相兼容,锁模型具体信息如下所示。
| 请求锁模型(Requested Lock Mode) | 当前锁模型(Current Lock Mode) | |||||||
|---|---|---|---|---|---|---|---|---|
| ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE | |
| ACCESS SHARE | √ | √ | √ | √ | √ | √ | √ | × |
| ROW SHARE | √ | √ | √ | √ | √ | √ | × | × |
| ROW EXCLUSIVE | √ | √ | √ | √ | × | × | × | × |
| SHARE UPDATE EXCLUSIVE | √ | √ | √ | × | × | × | × | × |
| SHARE | √ | √ | × | × | √ | × | × | × |
| SHARE ROW EXCLUSIVE | √ | √ | × | × | × | × | × | × |
| EXCLUSIVE | √ | × | × | × | × | × | × | × |
| ACCESS EXCLUSIVE | × | × | × | × | × | × | × | × |
- √表示可以同时持有锁。
- ×表示不能同时持有锁。
AnalyticDB PostgreSQL版对Multi-Master架构下的表锁协议进行了增强和适配,AnalyticDB PostgreSQL版定义了一套新的分布式表锁协议来规范Main Master及Secondary Master上加锁的顺序和规则:
- 任意Master上的进程请求1~3级锁规则如下:
- 本地请求该表锁。
- 在所有Segment上请求该表锁。
- 事务结束时所有节点释放锁。
- Main Mater上的进程请求4~8级锁规则如下:
- 本地请求该表锁。
- 在所有Secondary Master上请求该表锁。
- 在所有Segment上请求该表锁。
- 事务结束时所有节点释放锁。
- Secondary Master上的进程请求4~8级锁规则如下:
- 在Main Master上请求该表锁。
- 本地请求该表锁。
- 在所有其他Secondary Master上请求该表锁。
- 在所有Segment上请求该表锁。
- 事务结束时所有节点释放锁。
基于上述规则,AnalyticDB PostgreSQL版可以实现任何表锁请求会最终在某个Master或者Segment得到裁决,从而保证了对原表锁协议的兼容。
容错与高可用
AnalyticDB PostgreSQL版Multi-Master架构在原AnalyticDB PostgreSQL版的容错和高可用基础之上进行了增强,让系统能够进一步对Secondary Master进行兼容。如果Secondary Master故障,则会由管控系统看护并做实时修复。
AnalyticDB PostgreSQL版通过复制和监控来实现容错和高可用,具体如下:
- Standby Master和Mirror Segment分别为Main Master和Primary Segment提供副本(通过PG流复制实现)。
- FTS在后台负责监控与主备切换。
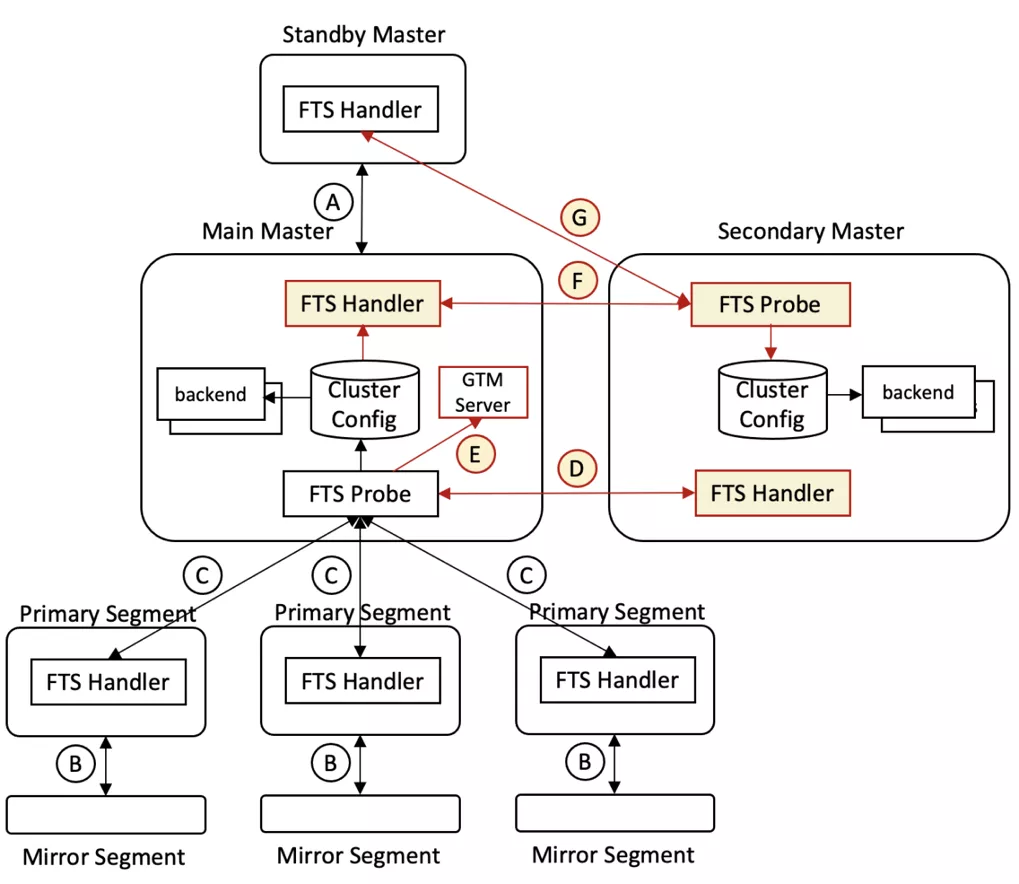
容错和高可用具体工作流程如下:
- 步骤A为Main Master到Standby Master的流复制。
- 步骤B为Primary Segment到Mirror segment的流复制。
- 步骤C为Main Master的FTS Probe进程发包探活Primary Segment。
- 步骤D为Main Master的FTS Probe进程发包探活Secondary Master。
- 步骤E为Main Master重启后,其FTS Probe进程向GTM Server通报所有Master。
- 步骤F为Secondary Master的FTS Probe发包探活Main Master,获取最新集群配置和状态信息并保存在本地。
- 步骤G为Secondary Master的FTS Probe无法连接Main Master后尝试探活Standby master,若成功则更新其为新的Main Master;否则继续探活原Main Master。