本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
OpenStore存储引擎是阿里云Elasticsearch团队针对日志场景自研的弹性、高效、低成本的日志存储引擎,支持根据实际存储数据量按量计费,无须提前预留集群存储容量,真正做到存储Serverless。OpenStore存储支持自定义冷热存储版本与智能混合存储版本,智能混合存储可突破传统冷热分离架构,大幅降低集群数据接入复杂度的同时,进一步降低云上海量数据的存储成本。本文主要介绍OpenStore智能混合存储引擎的适用场景、架构、优势以及性能指标。
背景信息
在日志全观测场景下,通常因为业务场景或监管需求,需要长时间存储数据或归档审计。在使用开源Elasticsearch的过程中,需要进行集群冷热数据分离,将30天或者更长时间的数据通过集群快照的方式存储在其他存储介质上,例如对象存储OSS等。该方式虽然能够实现长期日志数据归档,但是存储后不能直接进行查询,查询前需要调用相关API把快照信息恢复到集群中,等待快照中的索引初始化完成后再进行查询,面临着查询复杂度大、长时间存储成本高的问题。
OpenStore存储引擎是阿里云Elasticsearch 7.10日志增强版的重要功能,结合Indexing Service写入托管服务,满足用户在日志场景下低成本的高并发写入及长期数据存储需求。您可以按需创建7.10日志增强版实例,开启OpenStore智能混合存储功能,混合存储直接无法通过商业版升级到日志增强版。
如果未开启OpenStore,OpenStore存储默认关闭。您可以在实例基本信息页面的节点可视化区域查看是否已开启OpenStore功能、开启OpenStore功能并查看OpenStore存储信息,详细信息请参见查看集群状态和节点信息。
开启OpenStore后,建议您在控制台关闭自动快照备份功能,具体操作请参见自动备份与恢复。
适用场景
阿里云Elasticsearch自研Openstore存储引擎,适用于有海量数据写入及长期存储需求,数据查询QPS较低且查询时延容忍度相对较高的日志检索、指标分析等场景。
智能混合存储引擎适用于业务上对于数据有实时更新的需求,数据没有严格的冷热区分。
使用说明
无须单独购买集群热数据存储空间,所有数据统一使用OpenStore存储,按小时计算实际用量。价格详情,请参见Elasticsearch计费项。
创建的索引默认为混合存储索引,无须手动配置索引冷热生命周期策略。
OpenStore存储会自动根据查询情况选择缓存数据,数据分层及降级由混合存储自动完。
优势
海量存储:存储Serverless付费,无须提前规划及购买存储容量,数据存储按小时统计实际使用量,存储资源使用率达到100%。
低成本:实时可修改、支持写入更新,无须配置复杂索引生命周期,自动完成数据降级,超低使用门槛;数据存储单价相较于使用本地SATA盘存储成本降低了60%,相较于高效云盘降低了70%。
高可用:基于存储计算分离架构,多副本之间共享一份数据,不增加额外存储成本;底层存储服务保证集群的数据高可用,提供99.9999999999%(可达12个9)的数据持久性。
查询性能提升:对于典型日志场景的常用查询分析,性能相较于本地SATA提升了100%,与高效云盘或者PL0级别的ESSD云盘性能相当。
混合存储架构
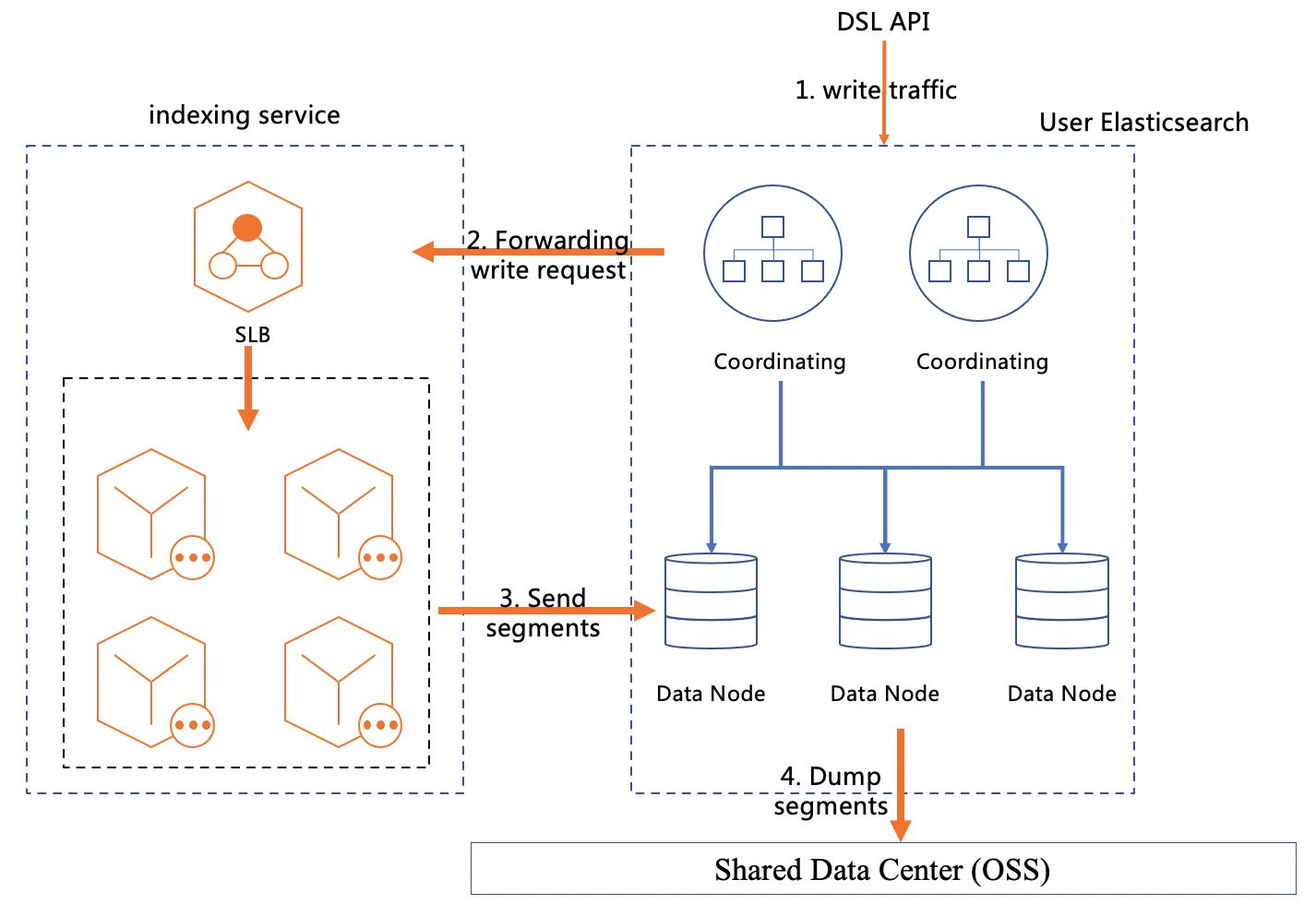
此架构具备以下优势:
存储计算分离:相较于冷热分离架构,进一步解耦计算与存储资源,用户不需要再关注存储容量。实现弹性存储、按量计费的同时,立足云原生优化集群扩展性,极大地提升了索引迁移和恢复的速度,适应海量数据场景。
易用性:全自动的索引生命周期管理,您只需要做简单的索引周期配置,引擎完全托管了索引冷热分离和数据迁移OpenStore存储的全过程。
数据一致性:智能混合存储通过基于Raft实现的混合存储一致性协议,保证不同存储介质之间的数据一致性,在用户无感知的情况下,自动完成数据降级及缓存加速,并支持数据实时更新。
使用限制
购买和使用OpenStore存储时,存在以下使用限制。
类别 | 限制说明 |
地域 | 目前仅开放以下地域(具体以控制台为准):
|
实例版本 | 仅7.10版本实例支持开启OpenStore存储,开启方式为新购7.10日志增强版Index Service实例开启。 |
实例规格 | 仅支持选择OpenStore存储型8核64 GB、16核64 GB规格 |
实例存储容量 | 单节点最大存储数据容量为30 TB。 说明 如果您有更大的单节点存储需求,请提交工单申请,最大支持50 TB。 |
shard副本数 | 开启OpenStore智能混合存储,shard副本数须大于等于1。 警告 多副本之间共享一份数据,不增加额外存储成本。多副本用于保证本地存储写入加速的可靠性,如果未设置多副本可能会导致部分实时写入数据的丢失,丢失后数据无法恢复。 |
索引模板 |
详细信息,请参见通过OpenStore智能混合存储实现海量数据存储。 说明 手动删除OpenStore存储索引时,需要将索引及索引对应的别名一起删除才可删除成功。 |
索引生命周期配置 | 不支持在索引生命周期中自定义freeze。 |
查询限制 |
|
集群分片数限制 | 建议80000以下。 |
节点分片数限制 | 建议3000以下。 |
单分片大小 | 建议40 G以下。 |
数据盘写入吞吐 | 数据盘实际使用水位在85%以下,300 MB/s。 数据盘实际使用水位在85%以上,100 MB/s。 |
性能测试
测试环境
数据集:某日志场景数据集。
集群规格:均采用某日志场景的相同配置,其中:
节点数:10
Shard数:108
查询条件:
查询类型:sort
文档个数:3,800,000,000
测试结果
存储类型
查询时间
本地SATA盘
30秒以上
高效云盘
12.229秒
OpenStore存储
15.841秒
测试结论:
在集群配置相同的情况下,查询日志数据时,通过OpenStore存储的查询耗时明显低于通过本地SATA盘存储的耗时,与高效云盘查询耗时基本持平。从价格方面来看,OpenStore存储的单价比高效云盘存储的单价低60%左右,而且是按量付费,无须提前购买存储容量。所以,通过使用OpenStore存储,可以为您节省一定的费用。
相关文档
- 本页导读 (1)