针对图像检索业务场景,PAI提供了端到端的相似图像匹配和图像检索解决方案。本文介绍如何基于未标注的数据构建图像自监督模型,助力您快速搭建相似图像匹配和图像检索业务系统,进而实现以图搜图。
背景信息
针对图像检索的业务场景(例如电商业务中需要根据已有图像搜索目标商品),PAI提供了如下解决方案,帮助您快速搭建相似图像匹配和图像检索业务系统:
解决方案
PAI在相似图像匹配和图像检索领域提供了端到端、轻量化的纯白盒解决方案。您只需要准备原始的图像数据,无需标注就能够构建模型。然后利用PAI的可视化建模平台快速自定义构建图像自监督模型。最后将模型在PAI上进行部署推理,形成完整的端到端流程,从而实现相似图像匹配和图像检索的业务系统。
方案架构
相似图像匹配解决方案的架构图如下所示。

图像检索解决方案的架构图如下所示。

方案优势
无需标注:图像无需标注,使用原始数据即可建模,从而节省大量人力成本。
纯白盒:可以根据自己具体的业务场景,纯自定义构建模型。
端到端:从最初的数据准备到最后的模型推理,提供全链路系统构建流程。
轻量级:无论是工程师还是初级用户,都能快速搭建图像匹配和检索系统。
前提条件
已开通PAI(Studio、DSW、EAS)后付费,详情请参见开通。
已开通工作空间,并添加MaxCompute计算资源和DLC计算资源,详情请参见AI工作空间(旧版)。
已创建OSS存储空间(Bucket),用于存储原始图像和训练获得的模型文件。关于如何创建存储空间,请参见控制台创建存储空间。
已创建EAS专属资源组,本文训练好的模型会部署至该资源组。关于如何创建专属资源组,请参见创建专属资源组。
已完成DLC使用权限授权,授权方法详情请参见云产品依赖与授权:DLC。
操作流程
基于阿里云PAI平台,构建相似图像匹配与图像检索解决方案的流程如下:
本文使用的算法为图像自监督算法,训练过程中无需标注数据,您将原始数据存入OSS即可直接进行模型训练。此外,如果使用图像检索解决方案,则需要在本地准备检索图的图像数据库。从而在图像检索模型的部署过程中,将准备好的本地数据注册到数据库中。
PAI提供了原始数据集,您可以直接使用它进行数据准备。关于数据集的下载方式,请参见Deepfashion2图像数据集。
利用可视化建模PAI-Studio平台,基于自己特定的业务场景,采用自监督的图像深度学习训练组件,将原始的尚未标注的图像直接进行训练。对于相似图像匹配场景和图像检索场景,您都可以使用该自监督组件进行模型训练,两种场景在模型训练部分无差别。
部署及调用模型服务
通过模型在线服务EAS,您可以将训练好的图像自监督模型部署为在线服务,并在实际的生产环境中的相似图像匹配和图像检索两个场景下进行推理实践,详情请参见部署及调用相似图像匹配的模型服务和部署及调用图像检索的模型服务。
准备数据
PAI提供了原始数据集,您可以直接使用它进行数据准备。关于数据集的下载方式,请参见Deepfashion2图像数据集。
准备模型训练所需的数据。
将原始图片上传至OSS的某一目录中。关于如何将文件上传至OSS,请参见控制台上传文件。
根据图像上传的OSS文件目录,生成OSS图像目标索引的TXT文件。索引文件的示例请参见demo_img_list.txt。
将生成好的TXT索引文件存储到OSS的某一目录下。
如果您使用图像检索解决方案,则需要准备图像检索数据库。
部署图像检索模型时,您需要准备检索的图像数据库,并对注册到数据库中的图像进行特征提取,从而在目标图像的推理过程中实现在已存在图像数据库中对上传的图像进行相似的快速检索。因此,您需要在本地准备图像检索数据库中的图像数据,为后续模型部署环节的注册数据库做准备。
构建图像自监督模型
登录PAI控制台。
在左侧导航栏,选择。
基于实验模板,创建相似图像匹配与图像检索实验。
在可视化建模(Studio)页面,单击实验模板页签。
单击CV页签。
在相似图像匹配与图像检索区域,单击创建。
在新建工作流对话框,配置参数,并单击确定。
其中:工作流数据存储建议配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
进入实验,并配置组件参数。
在可视化建模(Studio)页面,单击实验列表页签。
在实验列表页面,选中刚才创建好的模板实验,并单击进入实验。
系统根据预置的模板,自动构建实验,如下图所示。
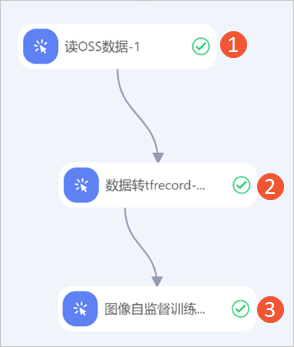
区域
描述
①
配置实验的数据集,即配置读OSS数据组件的OSS数据路径参数为准备的图像目标索引TXT文件的OSS目录。例如
oss://demo-zhoulou.oss-cn-hangzhou.aliyuncs.com/demo_image_match/df2_data/meta/train_crop_label_lt_10k_nolabel.txt,该数据集是PAI在华东1(杭州)准备好的数据集,您可以直接使用。②
将初始数据集转换为图像自监督训练组件所需的训练集。数据转tfrecord组件的配置详情请参见下文的数据转tfrecord组件配置。
③
配置图像自监督模型训练的参数。图像自监督训练组件的配置详情请参见下文的图像自监督训练组件配置。
表 1. 数据转tfrecord组件配置 页签
参数
描述
本案例的示例值
字段设置
转换配置文件路径
转化配置文件的OSS路径。在PAI-Studio中无需使用该配置文件。
无需填写
输出tfrecord路径
组件运行成功后,系统会自动在该路径下输出训练集和测试集文件。
oss://pai-online-hangzhou.oss-cn-hangzhou-internal.aliyuncs.com/demo_image_match/df2_data/tfrecord/test_210910/输出tfrecord前缀
自定义输出TFRecord文件名称的前缀。
df2_val
参数设置
转换数据用于何种模型训练
数据转tfrecord组件的输出数据可以用于以下类型的模型训练:
CLASSIFICATION :图像分类或多标签分类
DETECTION:物体检测
SEGMENTATION:语义分割
POLYGON_SEGMENTATION:多边形语义分割
INSTANCE_SEGMENTATION:实体分割
TEXT_END2END:端到端OCR
TEXT_RECOGNITION:单行文字识别
TEXT_DETECTION :文字检测
VIDEO_CLASSIFICATION :视频分类
CLASSIFICATION
类别列表文件路径
类别列表文件的OSS路径。由于自监督训练组件无需标签组,因此,您上传空文件即可。例如使用示例test.config。
oss://pai-online-hangzhou.oss-cn-hangzhou-internal.aliyuncs.com/demo_image_match/df2_data/meta/test.config测试数据分割比例
测试数据分割比例。如果设置为0,则所有数据转换为训练数据。设置为0.1表示10%的数据作为验证集。
0
图片最大边限制
如果配置了该参数,则大图片会被Resize后存入TFRecord,从而节省存储、提高数据读取速度。
无需填写
测试图片最大边限制
同图片最大边限制,用于配置测试数据。
无需填写
默认类别名称
默认类别名称。对于在类别列表文件中未找到的类别,系统将其映射到默认类别。
无需填写
错误类别名称
含有该类别的物体和Box会被过滤,不参与训练。
无需填写
忽略类别名称
仅用于检测模型,含有该类别的Box会在训练中被忽略。
无需填写
转换类名称
标注数据的来源类型,支持以下取值:
PAI标注格式
亲测标注格式
自监督标注格式
PAI标注格式
分隔符
用于标记内容的分隔符。
无需填写
图片编码方式
TFRecord中图片的编码方式。
jpg
执行调优
读取并发数
训练过程读取并发数。
10
写tfrecord并发数
训练过程写TFRecord并发数。
1
每个tfrecord保存图片数
训练过程每个TFRecord保存的图片数量。
1000
worker个数
训练过程中的Worker数量。
5
CPU Core个数
训练过程中的CPU Core数量。
800
memory大小
训练过程中的内存大小,单位为MB。
20000
表 2. 图像自监督训练组件配置 页签
参数
描述
本案例的示例值
字段设置
训练模型类型
模型训练的类型,支持以下取值:
MOCO_R50
MOBY_TIMM
MOCO_TIMM
SWAV_R50
在后续的模型推理中,MOBY_TIMM的特征维度为384,其余类型的特征维度皆为2048。
MOBY_TIMM
训练所用oss目录
存储训练模型的OSS目录。
oss://pai-online-hangzhou.oss-cn-hangzhou-internal.aliyuncs.com/demo_image_match/train/moby_0902/训练数据oss路径
训练数据集的OSS路径。如果通过上游组件传递训练数据,则无需指定该参数。
无需填写
是否使用预训练的模型
建议使用预训练模型,以提高训练模型的精度。
否
预训练模型oss路径
如果有自己的预训练模型,则将该参数配置为自己预训练模型的OSS路径。如果没有配置该参数,则使用PAI提供的默认预训练模型。
无需填写
参数设置
自监督模型使用的backbone
识别模型的网络名称,系统支持主流的识别模型resnet_50。
resnet_50
优化方法
模型训练的优化方法,仅支持AdamW。
AdamW
初始学习率
网络训练初始的学习率。
0.001
训练batch_size
训练的批大小,即单次模型迭代或训练过程中使用的样本数量。
64
总的训练迭代epoch轮数
总的训练迭代轮数。
80
保存checkpoint的频率
保存模型文件的频率。取值1表示对所有训练数据都进行一次迭代。
10
执行调优
读取训练数据线程数
读取训练数据的线程数。
4
evtorch model 开启半精度
开启半精度会使模型的推理速度显著提升,同时准确率略有降低。
否
单机或分布式(maxCompute/DLC)
模型训练使用的计算资源,支持以下取值:
单机DLC
分布式DLC
分布式DLC
worker个数
使用分布式DLC计算时,您需要配置用于计算的Worker数量。
1
gpu机型选择
计算资源的GPU机型。
说明自监督模型对资源的消耗较大,建议选择单机4卡或单机8卡的机器进行训练。
48vCPU+368GB Mem+4xv100-ecs.gn6e-c12g1.12xlarge
部署及调用相似图像匹配的模型服务
进入PAI-EAS 模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,进入PAI-EAS 模型在线服务页面。
部署模型服务。
在PAI-EAS 模型在线服务页面,单击部署服务。
在资源和模型面板,配置参数(此处仅介绍与本案例相关的核心参数配置方法,其他参数的解释请参见控制台上传部署),并单击下一步。
参数
描述
自定义模型名称
模型的名称,建议结合实际业务进行命名,以区分不同的模型服务。
资源组种类
建议使用专属资源组部署模型服务,从而避免公共资源组资源有限时导致的服务排队。关于如何创建专属资源组,请参见使用专属资源组。
资源种类
如果您选择资源组种类为公共资源组,则需要选择资源种类为GPU。
Processor种类
选择EasyVision。
模型类型
选择通用图像比对。
模型文件
本案例中训练好的模型均存储在OSS中,因此选择OSS文件导入。
您选择训练所用oss目录下的.pt模型文件即可。例如选择epoch_50_export.pt。
在部署详情及配置确认面板,配置模型服务占用资源的相关参数。
单击部署,等待一段时间即可完成模型部署。
查看模型服务的公网地址和访问Token。
在PAI-EAS 模型在线服务页面,单击目标服务服务方式列下的调用信息。
在调用信息对话框的公网地址调用页签,查看公网调用的访问地址和Token。
使用脚本进行批量调用。
创建相似图像匹配的Python脚本img_match.py。
import requests import base64 import sys import json hosts = 'http://16640818xxxxxxx.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/img_match_001' head = { "Authorization":"ZDgzYzdlODg5NTA3ODZiOTY0OWRxxxxxxxxxxxxxxxxxxxxx" } imagea_path = "./001.jpg" # 对比图像1的本地路经。 imageb_path = "./002.jpg" # 对比图像2的本地路经。 ENCODING = 'utf-8' datas = json.dumps( { "imagea": base64.b64encode(open(imagea_path, 'rb').read()).decode(ENCODING), "imageb": base64.b64encode(open(imageb_path, 'rb').read()).decode(ENCODING), }) for x in range(0,1): resp = requests.post(hosts, data=datas, headers=head) print(resp.content) print("test ending")将Python脚本上传至您的任意环境,并在脚本上传后的当前目录执行如下调用命令。
python3 <img_match.py>其中<img_match.py>需要替换为实际的Python脚本名称。
得到类似如下的预测结果。
 其中similarity表示图像的相似度,取值0~1之间,数值越大表示相似度越高。
其中similarity表示图像的相似度,取值0~1之间,数值越大表示相似度越高。
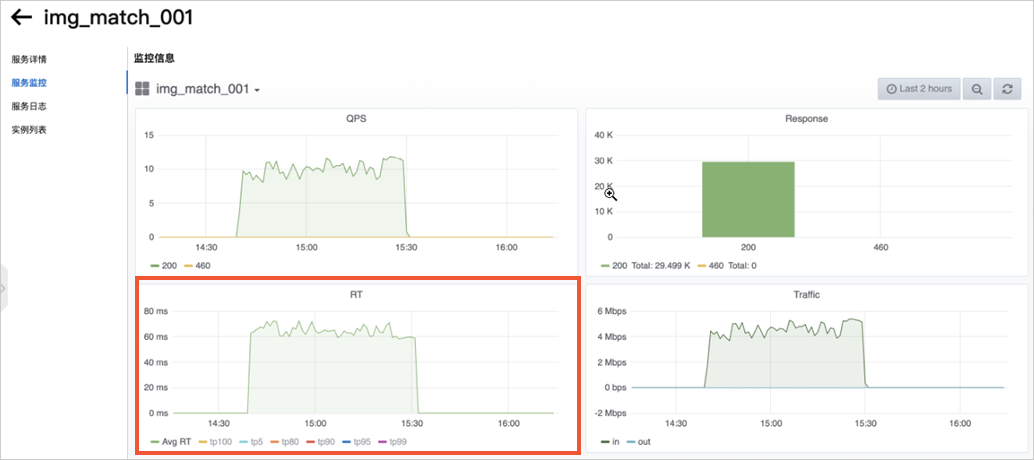
监控服务指标。
调用模型服务后,您可以查看模型调用的相关指标水位,包括QPS、RT、CPU、GPU及Memory。
在PAI-EAS 模型在线服务页面,单击已调用服务服务监控列下的
 图标。
图标。在服务监控页签,即可查看模型调用的指标水位。
从下面的服务监控水位图中可以看到,本案例部署的模型时延在80 ms左右。您自己的模型时延以实际为准。
部署及调用图像检索的模型服务
进入PAI-EAS 模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择,进入PAI-EAS 模型在线服务页面。
部署模型服务。
在PAI-EAS 模型在线服务页面,单击部署服务。
在资源和模型面板,配置参数(此处仅介绍与本案例相关的核心参数配置方法,其他参数的解释请参见控制台上传部署),并单击下一步。
参数
描述
自定义模型名称
模型的名称,建议结合实际业务进行命名,以区分不同的模型服务。
资源组种类
建议使用专属资源组部署模型服务,从而避免公共资源组资源有限时导致的服务排队。关于如何创建专属资源组,请参见使用专属资源组。
资源种类
如果您选择资源组种类为公共资源组,则需要选择资源种类为GPU。
Processor种类
选择EasyVision。
模型类型
选择商品检索。
模型文件
本案例中训练好的模型均存储在OSS中,因此选择OSS文件导入。
您选择训练所用oss目录下的.pt模型文件即可。例如选择epoch_50_export.pt。
在部署详情及配置确认面板,配置模型服务占用资源的相关参数。
参数
描述
实例数
本案例配置为1。实际应用时建议配置多个服务实例,以避免单点部署带来的风险。
卡数
本案例配置为1。实际应用时根据情况配置。
核数
本案例配置为1。实际应用时根据情况配置。
内存数(M)
本案例配置为16384 MB。实际应用时根据情况配置。
单击部署,等待一段时间即可完成模型部署。
查看模型服务的公网地址和访问Token。
在PAI-EAS 模型在线服务页面,单击目标服务服务方式列下的调用信息。
在调用信息对话框的公网地址调用页签,查看公网调用的访问地址和Token。
调用图像检索服务进行推理。
图像检索服务需要首先建立图像检索数据库,然后将注册到数据库中的图像进行特征提取,最后从图像数据库的数据中,对上传的图像进行相似快速检索。整个过程需要使用的接口包括数据库初始化、增加数据库、增加数据及检索数据等接口,如下表所示,所有接口说明请参见概述。下文提供一个简单的示例供您参考。
功能
描述
接口文档
初始化
首先基于某一指定的OSS路径进行数据库的初始化。
数据库管理
支持对图像数据库进行增加、查询、删除及存储操作。
图像数据注册
指定已存在的图像数据库,对图像数据进行增加、查询、删除及修改操作。
图像数据检索
指定已存在的图像数据库,对上传的图片进行图像相似的快速检索。
说明该方案主要针对轻量级数据。如果您的检索库数据量预期大于1000万,请联系您的商务经理来处理。
创建数据库初始化的Python脚本retrieval_init.py。
import requests import base64 import sys import json ENCODING = 'utf-8' our_oss_io_config = dict(ak_id='LTAIcsXXXXXXXXXX', # 阿里云账号的AccessKey。 ak_secret='gsiu1HjLGDXXXXXXXXXX', # 阿里云账号的AccessKey Secret。 hosts='oss-cn-hangzhou-internal.aliyuncs.com', # 内网Endpoint。 buckets=['tongxin-lly']) # OSS Bucket。 datas = json.dumps({ "function_name": "init", "function_params": { "backend": "oss", "root_path": "oss://tongxin-lly/img_retrieval/db0914/", # OSS具体路经。 "oss_io_config" : our_oss_io_config, }, }) hosts = 'http://16640818xxxxxxx.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/img_retrieval_001' head = { "Authorization":"NTE3Y2M2ZmEzZGQ3ZGRkOGM4ZDxxxxxxxxx" } r = requests.post(hosts, data=datas, headers=head) print(r.content) print("test ending")关于内网Endpoint的更多内容,详情请参见访问域名和数据中心。
创建增加数据库的Python脚本retrieval_add.py。
import requests import base64 import sys import json ENCODING = 'utf-8' datas = json.dumps({ "function_name": "add", "function_params": { "database_name" : "tongxin_demo", "feature_dim_dict": {'feature' : 384}, #模型训练的特征维度。模型训练时,如果选择MOBY_TIMM,则取值为384,否则取值均为2048。 "feature_distance_dict":{'feature':'Cosine'}, # 计算特征距离的衡量方法。 }, }) hosts = 'http://16640818xxxxxx.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/img_retrieval_001' head = { "Authorization":"NTE3Y2M2ZmEzZGQ3ZGRkOGM4ZDE1MDxxxxxxxxxxxxxx" } r = requests.post(hosts, data=datas, headers=head) print(r.content) print("test ending")创建增加数据的Python脚本retrieval_db_set.py。
import requests import base64 import sys import json ENCODING = 'utf-8' image_path = "./010.jpg" datas = json.dumps({ "function_name": "db_set", "function_params": { "database_name":"tongxin_demo", "image" : base64.b64encode(open(image_path, 'rb').read()).decode(ENCODING), "group_id" : "888", # 存入该数据的群组名。 "intra_id" : 10 # 该图像群组名下的具体ID。 }, }) hosts = 'http://16640818xxxxxx.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/img_retrieval_001' head = { "Authorization":"NTE3Y2M2ZmEzZGQ3ZGRkOGM4Zxxxxxxxxxxxx" } r = requests.post(hosts, data=datas, headers=head) print(r.content) print("test ending")创建检索数据的Python脚本retrieval_db_search.py。
import requests import base64 import sys import json ENCODING = 'utf-8' image_path = "./test.jpg" datas = json.dumps({ "function_name": "db_search", "function_params": { "database_name":"tongxin_demo", "image" : base64.b64encode(open(image_path, 'rb').read()).decode(ENCODING), 'search_topk' : 3, # 返回的最相似的k张图像. }, }) hosts = 'http://1664081855xxxxxx.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/img_retrieval_001' head = { "Authorization":"NTE3Y2M2ZmEzZGQ3ZGRkOGM4ZDE1MDVhNzxxxxxxxxx" } r = requests.post(hosts, data=datas, headers=head) print(r.content) print("test ending")将上述创建的Python脚本全部上传至您的任意环境,并在脚本上传后的当前目录依次执行调用命令。
python3 <retrieval_xxx.py>其中<retrieval_xxx.py>需要依次替换为上述创建的初始化脚本、增加数据库脚本及增加数据脚本。
针对部署好的数据库,进行目标图像检索,即调用检索数据脚本。
python3 retrieval_db_search.py得到的推理预测结果如下图所示。
 从上述模型推理的返回结果可以看出,模型服务返回了该数据库中与目标图像相似度最高的三张图像的group_id和对应intra_id。
从上述模型推理的返回结果可以看出,模型服务返回了该数据库中与目标图像相似度最高的三张图像的group_id和对应intra_id。
- 本页导读 (1)