本文介绍如何使用Logtail采集主机文本日志。
前提条件
已创建Logtail机器组并添加相应服务器,创建机器组的步骤,请参见创建用户自定义标识机器组(推荐)或创建IP地址机器组。
安装Logtail的主机需开放80(HTTP)端口和443(HTTPS)端口。ECS实例的端口由安全组规则控制,添加安全组规则的步骤请参见添加安全组规则。
服务器日志的内容持续新增。Logtail只采集增量日志,如果下发Logtail配置后日志文件无更新,则Logtail不会采集该文件中的日志。更多信息,请参见读取日志。
操作步骤
登录日志服务控制台。
在接入数据区域中,根据需要选择包含文本日志后缀的入口。本文以采集主机中的多行文本日志为例。

在选择日志空间页面,按照选择目标Project和Logstore,单击下一步。
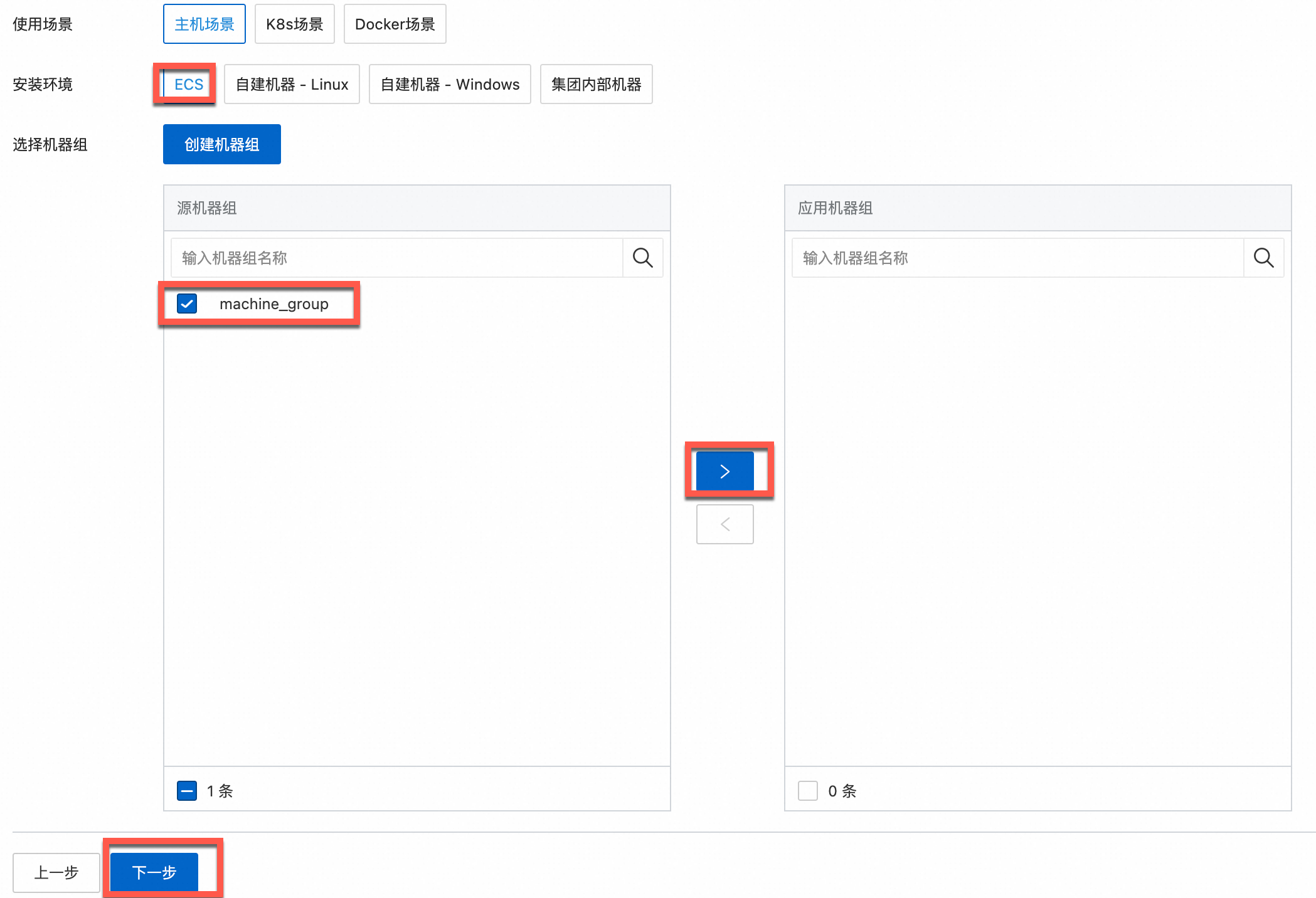
在机器组配置页面,配置机器组。
根据实际需求,选择使用场景和安装环境。
重要无论是否已有机器组,都必须根据实际需求正确选择使用场景和安装环境,这将影响后续的页面配置。
确认目标机器组已在应用机器组区域,单击下一步。
已有机器组
从源机器组列表选择目标机器组。
没有可用机器组
单击创建机器组,在创建机器组面板设置相关参数。机器组标识分为IP地址和用户自定义标识,更多信息请参见创建用户自定义标识机器组(推荐)或创建IP地址机器组。
重要创建机器组后立刻应用,可能因为连接未生效,导致心跳为FAIL,您可单击重试。如果还未解决,请参见Logtail机器组无心跳进行排查。
创建Logtail配置,单击下一步,创建Logtail配置。Logtail配置生效时间最长需要3分钟,请耐心等待。
创建索引和预览数据,然后单击下一步。日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果需要查询日志中的所有字段,建议使用全文索引。如果只需查询部分字段、建议使用字段索引,减少索引流量。如果需要对字段进行分析(SELECT语句),必须创建字段索引。
单击查询日志,系统将跳转至Logstore查询分析页面。
您需要等待1分钟左右,待索引生效后,才能在原始日志页签中,查看已采集到的日志。查询和分析日志的详细步骤,请参见查询和分析日志。
相关文档
使用Logtail采集日志后,如果预览页面为空或查询页面无数据,请按照Logtail采集日志失败的排查思路进行排查。在使用Logtail采集日志时,可能遇到正则解析失败、文件路径不正确、流量超过Shard服务能力等错误。查看Logtail采集错误的步骤,请参见如何查看Logtail采集错误信息。采集数据常见的错误类型请参见日志服务采集数据常见的错误类型。
默认情况下,一个日志文件只能匹配一个Logtail配置。如果同一份日志需要被采集多份,请参见如何实现文件中的日志被采集多份。
将企业内网服务器日志采集到日志服务,请参见采集企业内网服务器日志。
- 本页导读 (1)