本文介绍如何在E-MapReduce上配置及访问Hue,通过使用Hue可以在浏览器端与Hadoop集群进行交互来分析处理数据。
前提条件
已设置安全组访问。
重要设置安全组规则时要针对有限的IP范围。禁止在配置的时候对0.0.0.0/0开放规则。
已打开8888端口。
注意事项
EMR-3.35.0及后续版本或EMR-4.9.0及后续版本的Hadoop集群,需要注意以下信息:
当您需要使用Hue的Workflow作业时,请在Hue配置页签,删除app_blacklist参数值中的jobbrowser。
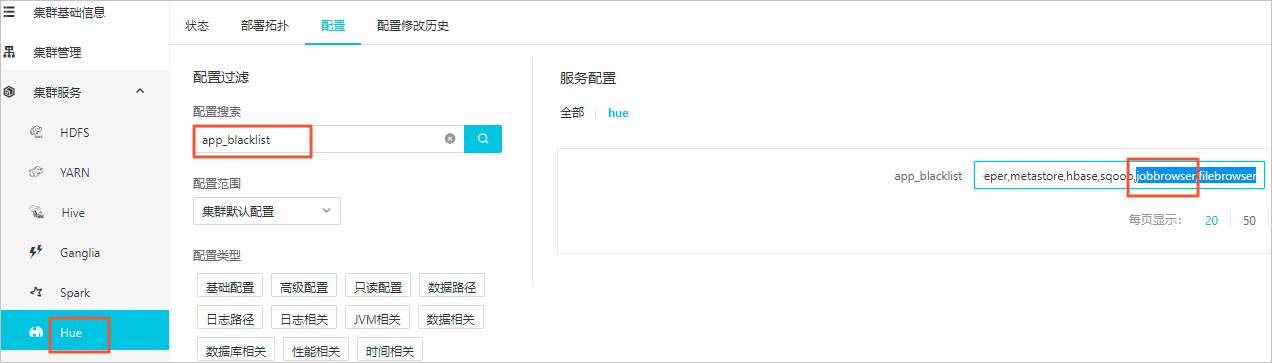
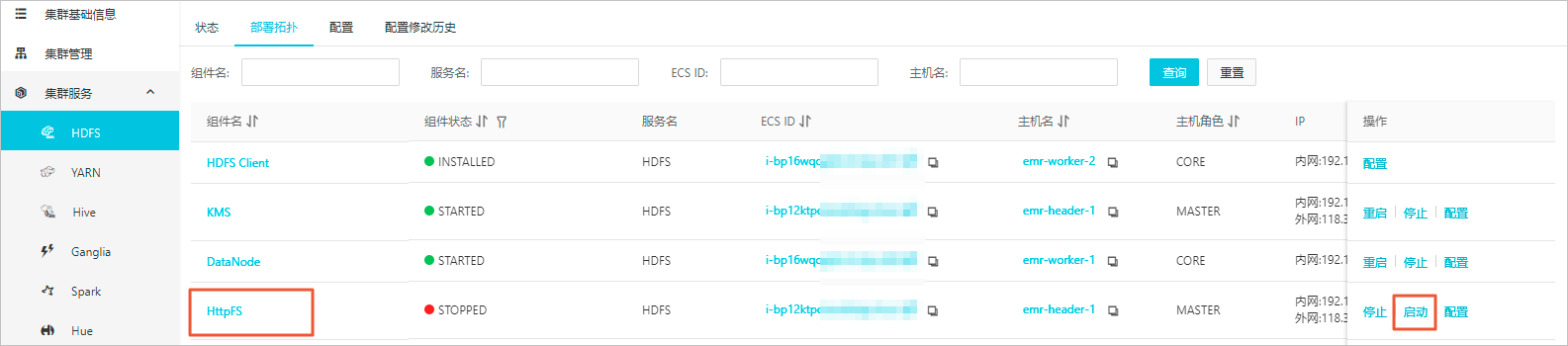
当您需要使用Hue通过界面浏览或者操作HDFS系统的目录时,请在Hue配置页签,删除app_blacklist参数值中的filebrowser,并启动HDFS服务的HttpFS组件。
查看初始密码
Hue服务默认在第一次运行时,如果未设置管理员则将第一个登录用户设置为管理员。因此出于安全考虑,E-MapReduce将默认为Hue服务创建一个名为admin的管理员账号,并为其设置一个随机的初始密码。您可以通过以下方式查看该管理员账号的初始密码:
在顶部菜单栏处,根据实际情况选择地域和资源组。
单击上方的集群管理页签。
在集群管理页面,单击相应集群所在行的详情。
单击左侧导航栏中的集群服务,在集群服务列表中,选择Hue。
单击配置页签,找到admin_pwd参数,该参数对应的值就是随机密码。
重要admin_pwd仅为admin账号的初始密码,在E-MapReduce控制台上更改该密码不会同步到Hue中。如果需要更改admin账号在Hue中的登录密码,您可以使用该初始密码登录Hue,然后在Hue的用户管理模块中进行修改,或者重置账号密码。
访问Hue
在集群管理页面,单击相应集群所在行的详情。
在页面左侧导航栏中,单击访问链接与端口。
单击Hue服务所在行的链接。
输入Hue账号和对应的密码。
创建用户账号
在集群管理页面,单击相应集群所在行的详情。
在主实例组区域获取Master节点的公网IP。
登录Master节点,具体步骤请参见登录集群。
执行以下命令,创建新账号。
输入新用户名、电子邮件,然后输入密码,再次输入密码后,按Enter键。
如果提示Superuser created successfully,则说明新账号创建成功,稍后用新账号登录Hue即可。
重置账号密码
使用SSH方式登录到集群主节点,详情请参见登录集群。
执行以下命令,查看Hue的路径。
ps aux | grep hue例如回显信息如下。
 说明
说明本示例中获取到Hue的路径为/opt/apps/hue/build/env/bin/hue。
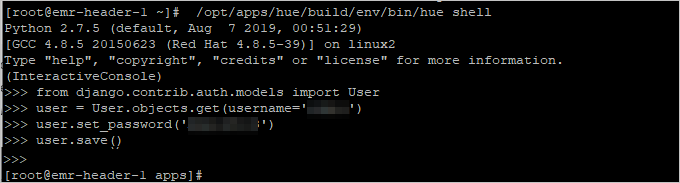
执行以下命令,重置用户密码。
from django.contrib.auth.models import User user = User.objects.get(username='your username') //输入待重置密码的用户名。 user.set_password('your new password') //输入新密码。 user.save()说明您可以按下键盘的ctrl+D组合键退出Shell。
示例如下:
添加配置
在集群管理页面,单击相应集群所在行的详情。
在页面左侧导航栏中,单击。
单击配置页签。
在服务配置区域,单击hue。
单击右上角的自定义配置,添加配置的Key和Value值,
$section_path.$real_key参数信息如下:
$real_key即为需要添加的实际的Key,例如hive_server_host。$section_path可以通过hue.ini文件查看。例如:通过hue.ini文件可以看出
hive_server_host属于[beeswax]这个section下,则$section_path为beeswax。说明综上可见,添加的Key为
beeswax.hive_server_host。如果需要修改hue.ini文件中的多级section([desktop] -> [[ldap]] -> [[[ldap_servers]]] -> [[[[users]]]] ->user_name_attr)下的值,则需要配置key为desktop.ldap.ldap_servers.users.user_name_attr。
调整YARN队列
HUE进行SQL交互查询时,需要向YARN申请资源进行计算,如果需要对计算资源进行管理和隔离,则需要配置HiveSQL和SparkSQL的对应队列。
在集群管理页面,单击相应集群所在行的详情。
修改或添加自定义配置。
HiveSQL需要根据不同引擎设置HiveServer2。
重要本文的QUEUENAME为需要配置的队列名称。
单击左侧导航栏的。
单击配置页签。
单击服务配置区域的hiveserver2-site页签。
单击右上角的自定义配置添加相应如下配置:
引擎
配置项
说明
Hive on MR
mapreduce.job.queuename
QUEUENAME
Hive on Tez
tez.queue.name
Hive on Spark
spark.yarn.queue
说明若需修改配置,可直接在服务配置页面修改配置项的值。
SparkSQL使用SparkThriftServer,在Spark组件上修改spark-thriftServer配置或添加自定义配置:
单击左侧导航栏的。
单击配置页签。
单击服务配置区域的spark-thriftServer页签。
单击右上角的自定义配置,添加spark.yarn.queue为QUEUENAME。
重启Hue所在集群的HiveServer2和Spark的ThriftServer。
在集群管理页面,单击。
在组件列表区域,单击HiveServer2所在行的重启。
输入相关信息,单击确定。
在集群管理页面,单击。
在组件列表区域,单击ThriftServer所在行的重启。
输入相关信息,单击确定。