本文为您介绍基于SLS推出的ScheduledSQL功能,对历史数据进行汇总压缩,降低使用存储成本。
背景
日志服务 SLS通过丰富灵活的方式将多种类型(日志、指标)的数据接入到服务中,并随着时间不断沉淀;之后,用户就可以通过SLS强大的查询分析能力对多个维度的数据进行搜索、分析。虽然历史数据同样有较高的查询分析价值,但是大量历史数据的存储成本也不能忽视。因而SLS的用户一般会给数据设置一个固定的保留日期,定期清理历史数据,减轻成本压力。为了解决这一问题,SLS近期推出了新功能ScheduledSQL,让用户定时保存SLS中的汇总数据,既保存了历史数据供以后查询分析,同时又减轻了存储的成本压力。
汇总数据
日志、指标类的数据都会随着时间的推移不断累积。例如一个系统每秒产生1000条日志,日志的平均大小为500byte,一小时就会有1.8GB的日志,一年就会产生15T的数据。虽然数据使用方希望能够尽可能多的保存这15T数据以供查询分析使用,但是这些历史数据在提供分析价值的同时,也造成了较高的成本压力。定期删除历史数据虽然能够解决成本问题,但同时也给数据使用方带来了不便。
数据价值的时间梯度
从使用频率、数据权重等维度不难看出,数据的价值是随着时间不断降低的。例如用户页面查看日志,需要查看最近七天单个用户每天的特定页面的访问数,最近一月单个用户每天的访问数,最近一年单个用户每月的访问数。假设有2万用户,20可供用户访问的页面:
数据维度 | 时间梯度 | 保存时长 | 汇总数据量(条) | 原始数据量(条) | 汇总占比 |
user/page | 天 | 7天 | 2万 * 20 * 7 = 280万 | 2万 * 20 * 7 = 280万 | 100% |
user | 天 | 30天 | 2万 * 30 = 60万 | 2万 * 20 * 30 = 1200万 | 5% |
user | 月 | 1年 | 2万* 12 = 24万 | 2万 * 20 * 365 = 1.4亿 | 0.16% |
可以看到在上述场景下,随着时间推移,数据具有极高的可压缩比率。相对于直接删除历史数据,可以通过保存汇总数据来降低存储成本。这样即能够查询分析历史数据,又不必花费极高的存储成本。
汇总数据结构
在生成汇总数据的时候,首先需要评估数据的使用场景。不同场景、不同类型的数据的使用方式千差万别,其评估方式也不尽相同。下面介绍下不同类型数据的评估方式。
数值型数据
指标数据是典型的数值型数据,一条典型的指标日志如下所示:
{
"bucket_location": "oss-cn-*****-h",
"bucket": "buc*****65",
"object": "245-***************.model",
"operation": "PostObject",
"time": "23/Jun/2021:10:23:50",
"object_size": "3188",
"__time__": 1624443830,
"key": "data-***************.txt",
"content_length_out": "22583527",
"content_length_in": "46803694",
"http_status": "200",
"response_time": "7339",
"__tag__:__receive_time__": "1624443838"
}这条日志的字段可以分为时间,数值字段,分组字段三类,例如:
字段名称 | 字段值 | 类型 |
bucket | buc*****65 | 分组 |
object | 245-***************.model | 分组 |
operation | PostObject | 分组 |
object_size | 3188 | 数值 |
content_length_in | 46803694 | 数值 |
content_length_out | 22583527 | 数值 |
__time__ | 1624443830 | 时间 |
__tag__:__receive_time__ | 1624443838 | 时间 |
数值字段即为具体的指标值,维度和时间字段一般用作分组值,在计算指标的聚合值时作为分组依据。例如,如果要计算OSS每个bucket每小时写入的数据量,则需要使用维度字段operation和bucket,时间字段__time__,数值字段content_length_out:
operation: PostObject | select bucket, date_trunc("hour", __time__) as tm, sum(content_length_in) as total from log group by bucket, tm如果使汇总数据支持上述场景,需要在汇总数据中保存分组字段operation和bucket,精确到小时级别的__time__字段,以及content_length_in的聚合值。所以可以通过如下sql语句计算汇总数据,支持上述场景:
operation: PostObject | select bucket, operation, date_trunc("hour", __time__) as tm, sum(content_length_in) as size from log group by bucket, operation, tm如果还需要汇总数据同时支持计算每小时单次写入数据量的平均值,则需要通过如下sql语句计算汇总数据:
operation: PostObject | select bucket, operation, date_trunc("hour", __time__) as tm, avg(content_length_in) as avg, count(1) as size from log group by bucket, operation, tm得到如下所示的汇总数据:
字段名称 | 字段样例 | 字段说明 |
bucket | buc*****65 | bucket名称 |
operation | PostObject | 操作名称 |
tm | 1624442400 | 取整到小时的时间戳 |
avg | 22583527 | 单次写入数据大小的平均值 |
size | 65 | 写入数据请求的次数 |
基于得到的汇总数据,可以通过如下sql语句进行计算
计算OSS每个bucket每小时写入的数据量
operation: PostObject | select bucket, tm, sum(avg * size) as total from log每小时单次写入数据量的平均值
operation: PostObject | select bucket, tm, avg from log可以看出,随着场景的不同,计算汇总数据所需的sql语句也不尽相同。可以从以下几个方面评估如何计算汇总数据:
选择分组字段。
选择数值字段的聚合值:计数、求和、平均、最大、最小。
选择时间粒度:分钟、小时、天。
采样历史数据
采样历史数据则较为简单,在历史数据中按照一定的规则挑选合适的数据存储即可。例如对于系统日志,可以选择存储日志级别为WARNING或者ERROR的数据进行存储,忽略INFO级别的日志。
汇总数据的限制
汇总数据本质上是对原始数据在更粗时间粒度的聚合,并且聚合分组、计算都是按照对汇总数据的预期使用方式来选择的。
时间粒度
如果汇总数据的时间粒度是小时,则使用汇总数据进行数据分析只能够得到以小时为单位的聚合结果,无法得到更细粒度的数据。
聚合函数
聚合函数只能够使用汇总数据中聚合值支持的。如果汇总结果中不包含最小值,则基于汇总结果进行聚合计算的时候,是无法精确得到最小值的。
分组数据
由于汇总数据只保存了部分分组数据,在使用汇总数据进行数据分析时只能够使用保存的部分。
日志服务中的汇总数据
下面以OSS访问日志为例,说明如何基于SLS推出的ScheduledSQL功能,对历史数据进行汇总压缩,从而降低使用存储成本。
评估使用场景
一条完整的OSS访问日志如下:
{
"__topic__": "oss_access_log",
"bucket_location": "oss-cn-****-p",
"bucket": "bucket****",
"object": "245-************.model",
"client_ip": "127.0.0.1",
"operation": "PutObject",
"logging_flag": "false",
"time": "23/Jun/2021:13:07:30",
"server_cost_time": "8636",
"object_size": "7748",
"vpc_addr": "127.0.0.1",
"sync_request": "cdn",
"__time__": 1624453650,
"key": "data*****6958txt",
"delta_data_size": "3938",
"__source__": "127.0.0.1",
"error_code": "network disconnected",
"content_length_out": "79193322",
"response_body_length": "717233083",
"request_uri": "/request/path-2/file-9",
"content_length_in": "1823770",
"http_method": "GET",
"http_status": "200",
"request_length": "4099",
"response_time": "398",
"__tag__:__receive_time__": "1624453651",
"owner_id": "ln***v2",
"http_type": "https",
"bucket_storage_type": "archive"
}需要基于OSS访问数据构建如下的几类关键结果:
名称 | 时间粒度 | 分组依据 | 聚合函数 |
单位时间请求次数 | 小时 | bucket, operation | count |
单位时间请求错误 | 小时 | bucket, operation, http_status | count |
单位时间写入数据量 | 小时 | bucket, operation | sum |
单位时间平均写入数据量 | 小时 | bucket, operation | avg, count |
单位时间读取数据量 | 小时 | bucket, operation | sum |
单位时间平均读取数据量 | 小时 | bucket, operation | avg, count |
根据上面的使用场景,可以通过如下语句计算汇总数据:
operation: PostObject | select bucket, operation, http_status, date_trunc('hour', __time__) as tm, avg(content_length_out) as out_avg, avg(content_length_in) as in_avg, count(1) as size from log group by bucket, operation, http_status, tm创建ScheduledSQL任务
执行查询语句
在SLS的控制台中执行上述查询语句,随后点击创建ScheduledSQL。
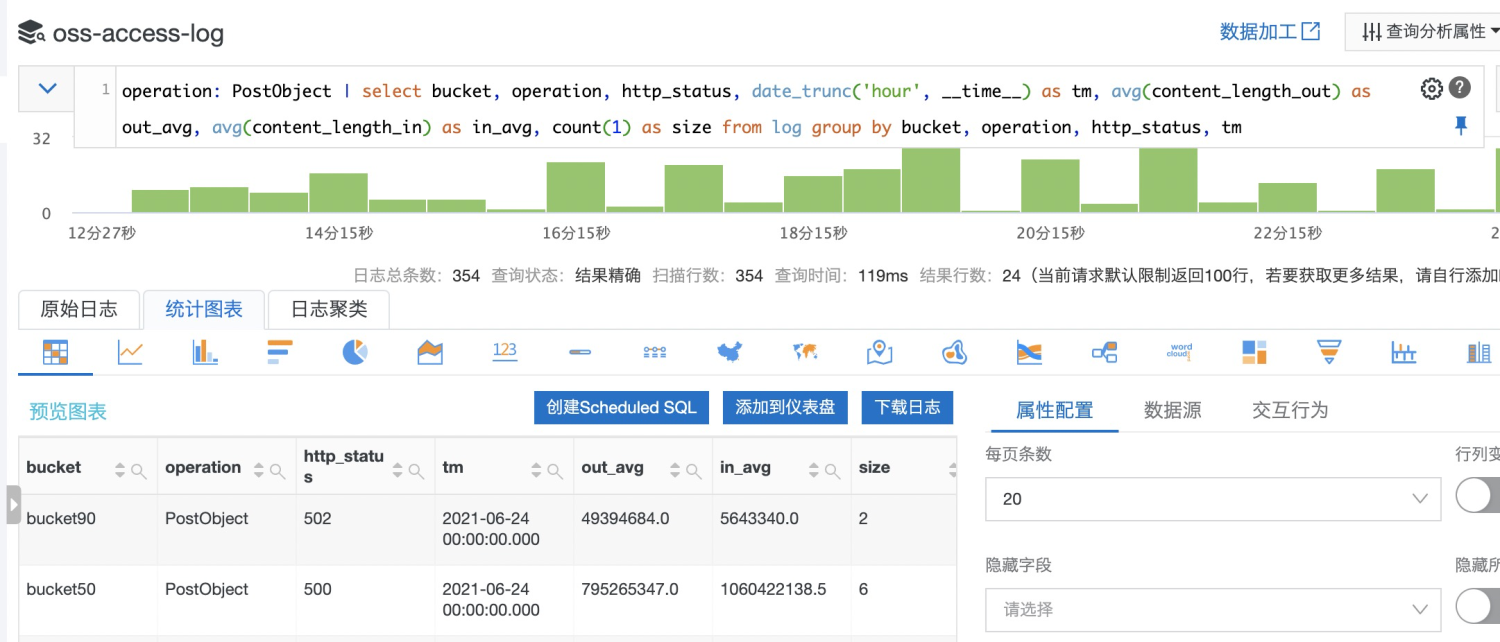
计算配置
此处填入合适的作业名称、以及目标库即可。此处需要注意开启目标库的索引。
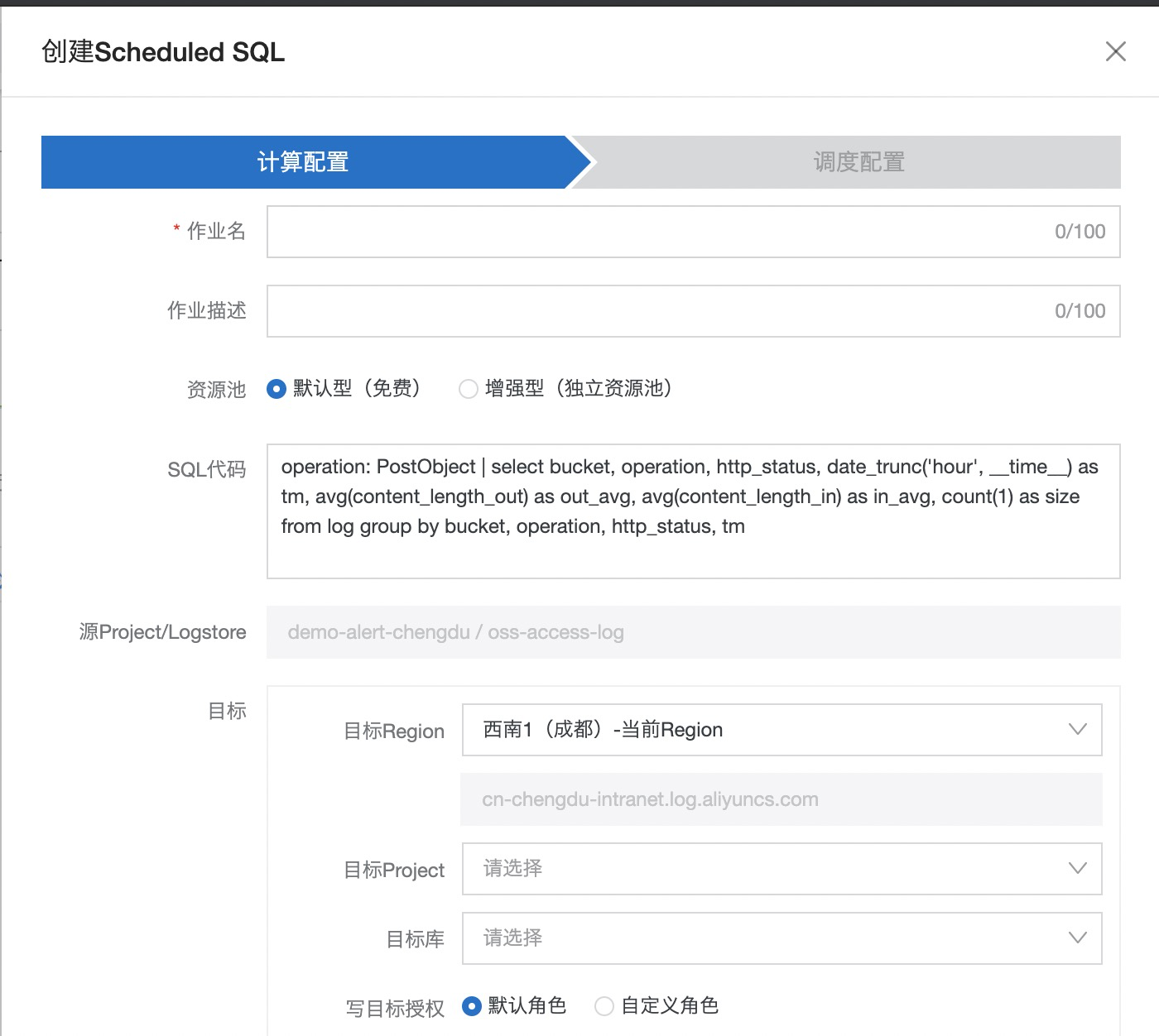
调度配置
这里调度间隔和时间窗口都选择小时级别,点击确认即可。关于调度配置的详细信息,可以参考官方文档。
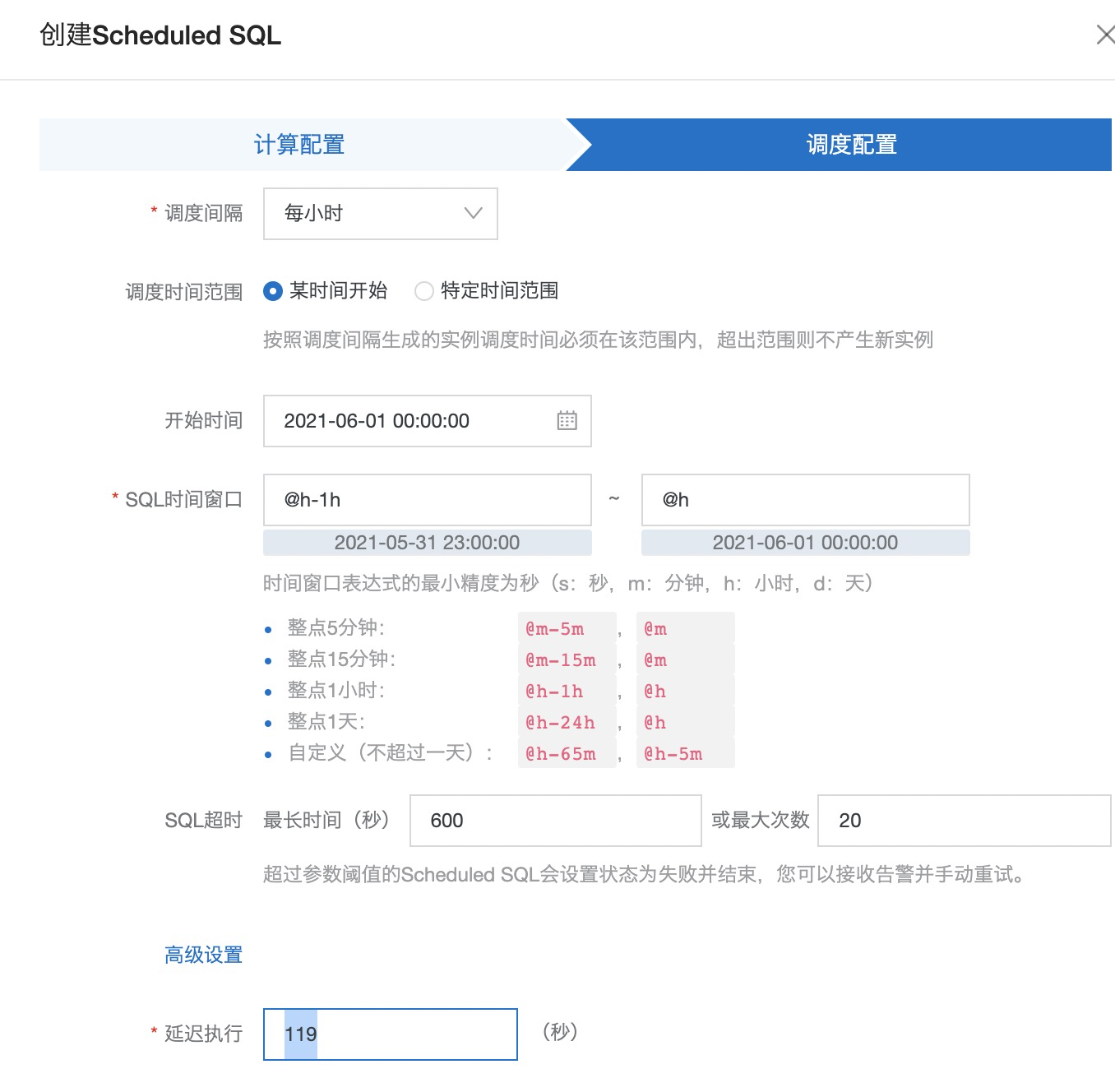
在任务执行成功之后,就可以在目标库中看到汇总数据。
汇总数据的使用
基于ScheduledSQL任务生成的汇总数据,可以为上述场景提供支撑。
名称 | 查询语句 |
单位时间请求次数 | *| select bucket, tm, sum(1) as total group by bucket, tm |
单位时间请求错误 | not http_status: 200 | select bucket, count(1) as cnt group by bucket |
单位时间写入数据量 | operation: PostObject | select bucket, tm, sum(avg_out * size) as total from log |
单位时间平均写入数据量 | operation: PostObject | select bucket, tm, sum(avg_out * size) as total from log |
单位时间读取数据量 | operation: GetObject | select bucket, tm, sum(avg_in * size) as total from log |
单位时间平均读取数据量 | operation: GetObject | select bucket, tm, sum(avg_in * size) as total from log |
总结
通过汇总数据支撑历史数据分析,能够较大的减轻存储成本上的压力。虽然同原始数据相比,其在使用场景以及灵活性方面都有所欠缺,但是如果能够提前做好规划,就能够很好的支撑大部分的使用场景。