PolarDB提供了热备切换功能,您可事先为集群中的只读节点开启热备功能,从而在主备切换的过程中实现快速切换和事务保持。
背景信息
云数据库高可用的演进可以概括为以下几个阶段。传统主备模式的高可用采用Binlog复制,存在复制延迟问题,如DDL和大事务。PolarDB的高可用通过物理复制解决了延迟问题,通过共享存储提升了扩缩容能力,但版本升级等场景依然会存在连接中断和事务回滚,过程中应用客户端会存在大量的请求报错。为了最大化的提升小版本升级、扩缩容以及故障容灾等场景的实用价值,推出了热备无感秒切的技术。该技术也是PolarDB向Serverless演进的一个必要条件。
 PolarDB的无感秒切技术从故障探测、切换速度和切换体验三个方面对切换场景进行了优化,包括计划内的切换,如集群升降配和小版本升级,以及计划外的容灾切换。整合了多项技术,来解决用户的痛点问题:
PolarDB的无感秒切技术从故障探测、切换速度和切换体验三个方面对切换场景进行了优化,包括计划内的切换,如集群升降配和小版本升级,以及计划外的容灾切换。整合了多项技术,来解决用户的痛点问题:
引入全新的高可用模块Voting Disk(简称VDS),该模块基于共享存储架构,实现自治的集群节点管理,大幅降低故障检测和集群选主耗时;
新增支持全局预热系统的热备节点,通过对存储引擎内部的多个模块提前预热,优化升主的执行耗时;
结合数据库代理(PolarProxy),支持连接保持和事务保持功能。在集群升降配或小版本升级过程中,开启连接保持和事务保持功能后,系统会尽可能地保证用户的连接和事务不中断,实现基本无感知的主动运维。
适用版本
支持使用热备切换功能的PolarDB MySQL版版本如下:
PolarDB MySQL版5.6版本,且内核小版本需为5.6.1.0.35及以上。
PolarDB MySQL版5.7版本,且内核小版本需为5.7.1.0.24及以上。
PolarDB MySQL版8.0.1版本,且内核小版本需为8.0.1.1.29及以上。
PolarDB MySQL版8.0.2版本,且内核小版本需为8.0.2.2.12及以上。
注意事项
当只读节点未开启热备时,主备切换过程中可能会出现20~30秒左右的闪断,因此切换前请务必确保应用具备重连机制;当只读节点开启了热备功能时,主备切换将在3~10秒内完成。
热备节点规格需要与主节点规格保持一致。
热备切换功能中的Voting Disk与列存索引功能互斥,若集群中已存在只读列存节点,则该集群中的任何只读节点都不支持开启热备功能。
此时若您需要继续为集群开启热备功能,请先删除已存在的只读列存节点。
若需要开启事务保持功能,您需要在控制台的参数配置页面将
loose_innodb_trx_resume参数值设置为ON。设置参数值详情请参见设置集群参数和节点参数。
技术原理
PolarDB热备切换功能的核心技术如下:
全新的高可用系统VDS
热备功能开启后,PolarDB会启用VDS。VDS借助PolarDB的共享存储架构,可以实现集群节点的自治管理、故障检测和集群选主。
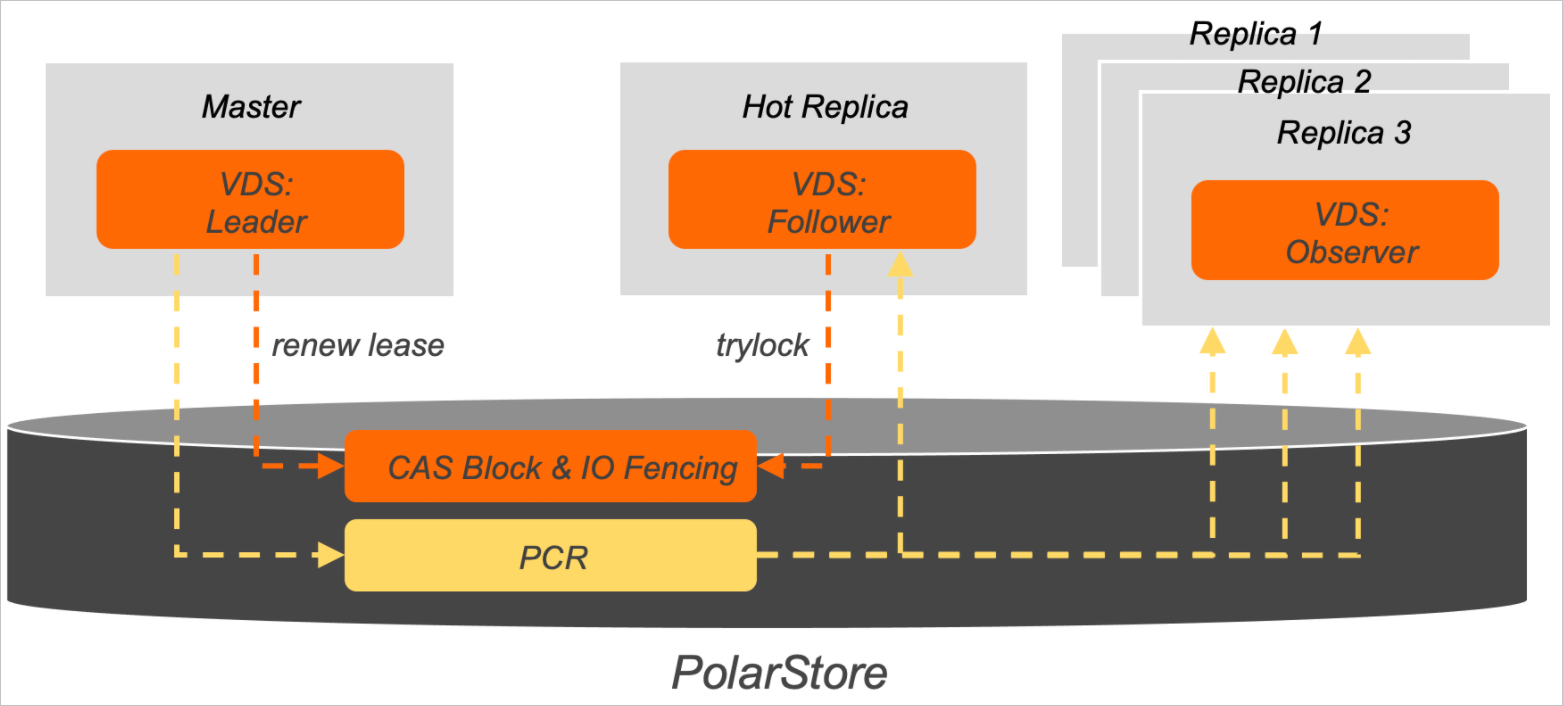 VDS架构说明如下:
VDS架构说明如下:VDS中每个计算节点有独立的VDS线程,分为三种不同的角色:Leader、Follower和Observer。其中Leader对应PolarDB的主节点,Follower对应PolarDB的热备节点,Observer对应PolarDB的只读节点。一般情况下,一个PolarDB集群包含1个Leader、1个Follower和多个Observer。
VDS在共享存储(PolarStore)上维护了两个数据模块,分别是CAS Block和Polar Cluster Registry(简称PCR)。
CAS Block是PolarStore提供的支持Compare-And-Swap(简称CAS)操作的原子数据块。VDS基于CAS实现了分布式租约锁,并在数据块中记录了锁持有者和租约时间等元信息。PolarDB的主节点和热备节点,通过续租和加锁语义,完成故障探测和集群选主。
PCR是一个保存了PolarDB节点管理信息的数据块,负责维护整个集群的拓扑状态。VDS中的Leader角色有PCR的写入权限,Follower和Observer角色只有只读权限。当VDS中的Follower角色升级为Leader时,原来的Leader角色会自动降级为Follower,且只有最新的Leader角色才拥有共享存储的写入权限。与此同时,PCR会重建拓扑。
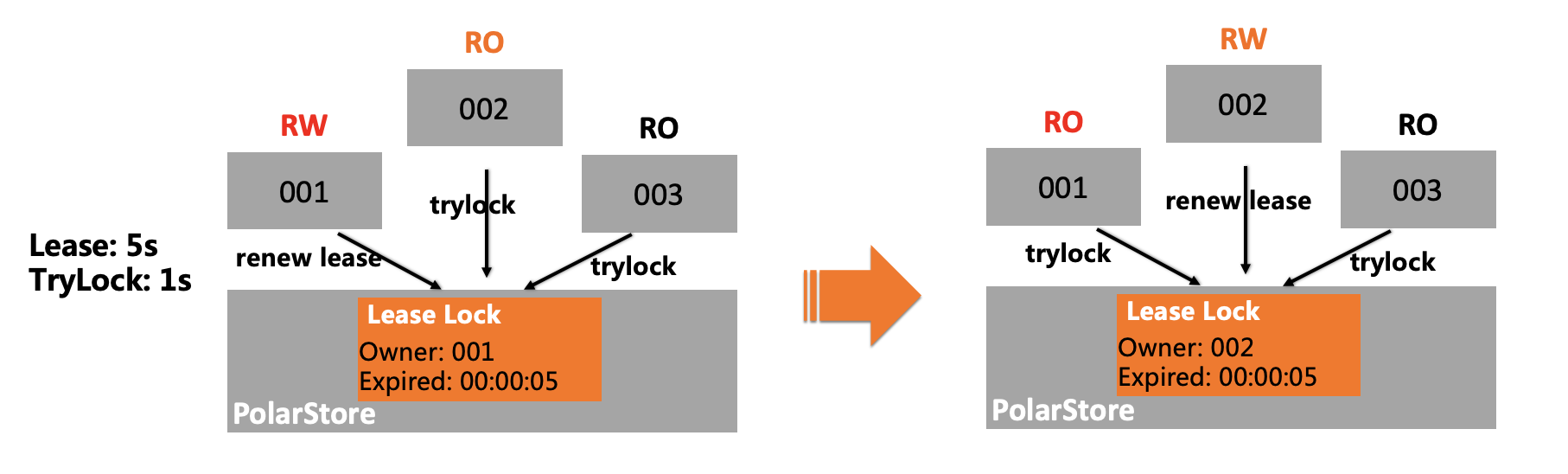
正常情况下,主节点对外提供读写服务,并通过VDS中的Leader定期续租。当主节点故障时,热备切换流程如下:
VDS Follower在租约超期之后会加锁成功升级为Leader,从而使热备节点升级为新的主节点。
故障的主节点恢复后,加锁失败,会自动降级为备节点。
在集群选主流程结束后,PCR会将新的拓扑信息广播给所有的VDS Observer。这样只读节点就能够自动连接到新的主节点,并恢复LSN和Binlog等同步链路。
全局预热系统
热备节点是弱化版的只读节点,同时也是一个更接近主节点,并随时准备切换的灾备。相较于普通的只读节点,它保留了有限的读服务,预留了更多的CPU和Memory资源来优化切换速度。全局预热系统是热备切换中最核心的模块,主要负责实时同步主节点的元信息,将一些关键数据提前加载进内存,来提升未来潜在的升主切换速度。全局预热系统包含四个模块: Buffer Pool、Undo、Redo和Binlog。
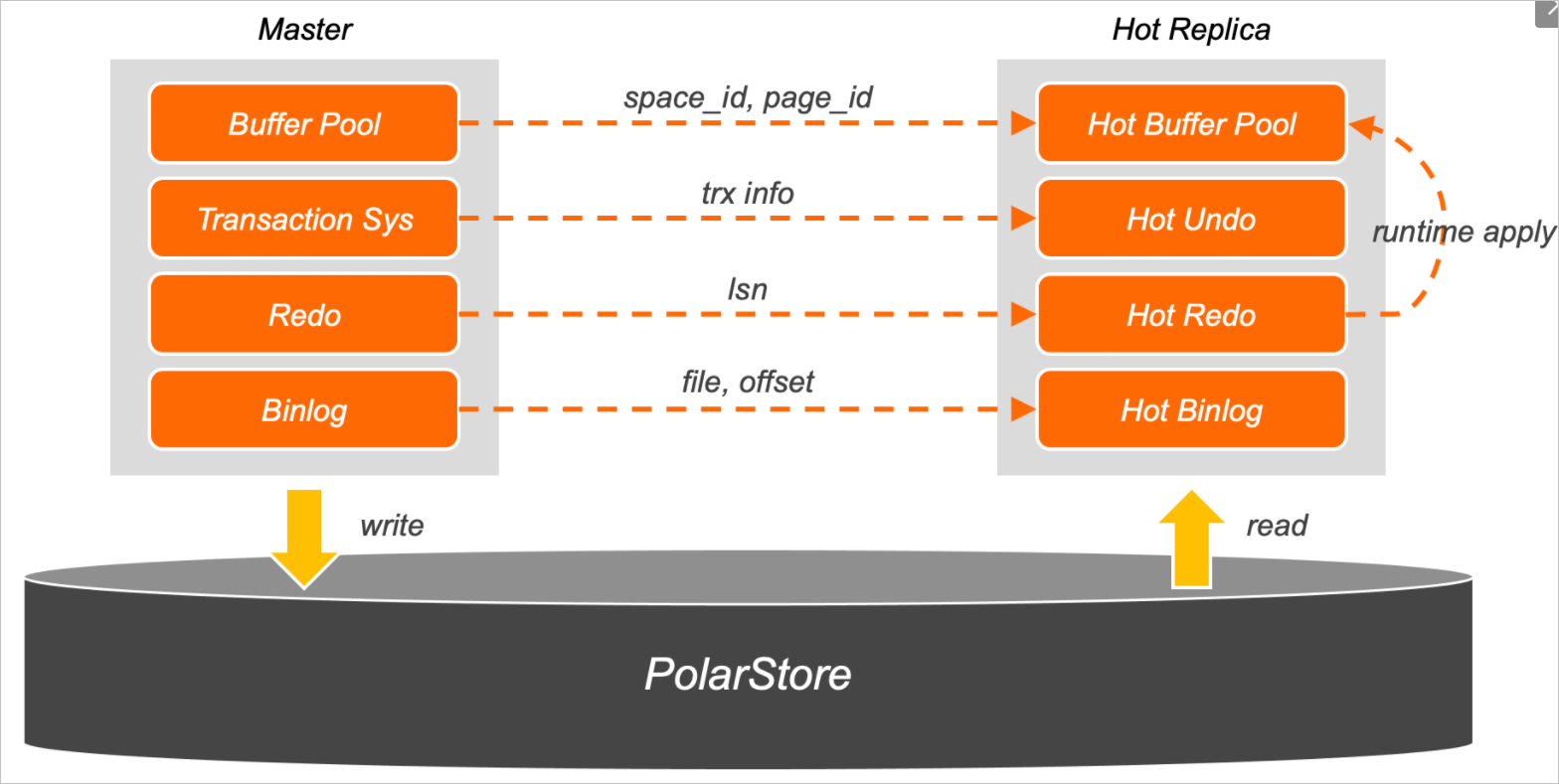
Buffer Pool
Buffer Pool预热模块会实时监控主节点Buffer Pool的LRU(Least Recently Used)链表,并将相关信息发送给热备节点。热备节点会智能地选择最热的数据页,并将它们提前批量加载到内存中,用来缓解只读节点切换为主节点后,Buffer Pool命中率大幅下降带来的性能抖动。
Undo
Undo预热模块是对事务系统的预热。在切换过程中,PolarDB需要从Undo Page中找出悬挂事务并进行回滚。只读节点只会服务于分析类型的大查询,而不会访问主节点未提交的事务。因此,在切换流程中存在Undo Page的IO等待。热备切换提前预热Undo Page,通过Runtime Apply回放到最新版本,减少事务系统的恢复时间。
Redo
Redo预热模块会将热备节点和只读节点的Redo日志实时缓存在内存的Redo Hash中。
Binlog
如果集群开启了Binlog,切换过程中,处于Prepare状态的InnoDB事务还依赖Binlog信息来决策提交或者回滚事务。对于大事务场景,完整读取和解析最后一个Binlog文件时,经常需要耗费数秒甚至数分钟的时间。热备节点通过后台线程,异步地将最新的Binlog数据缓存在IO Cache中,并提前进行解析,来彻底解决切换耗时问题。
PolarDB支持热备节点和普通备节点之间的动态转换。在实际使用场景中,您可以选择长期开启一个热备节点,或者选择仅在变配、升降级的过程中短时间开启热备功能。为了节约成本,PolarDB支持配置不同规格的主节点和只读节点,但至少有一个和主节点同规格的只读节点作为灾备,建议将这个节点配置为热备节点。
连接保持和事务保持
常规的主备切换或热升级操作会对应用服务造成影响,导致连接闪断、新建连接短暂失败以及存量事务回滚等问题,增加了应用开发的复杂性和风险。
PolarDB支持连接保持功能。连接保持的原理是数据库代理在应用程序和PolarDB之间,扮演了连接桥接的角色。当数据库进行主备切换时,数据库代理将新的后端连接(即数据库代理和数据库节点的连接)桥接到原有的前端连接(即应用程序和数据库代理的连接)上,同时恢复之前的会话状态,包括原来的系统变量、用户变量和字符集编码等信息。
连接保持功能只能作用于空闲的连接,如果在切换瞬间,当前的会话有正在执行的事务,一方面数据库代理无法从PolarDB中找回原有事务的上下文,另一方面新的主节点会将未提交的悬挂事务回滚,释放这些事务持有的行锁。在这种场景下,连接保持就会失效,而PolarDB最新推出的事务保持功能可以解决这一问题。事务保持配合连接保持,可以实现对应用程序完全无感知的高可用切换。

相比传统的基于Binlog的逻辑复制,PolarDB是基于物理复制的架构,可以在热备节点上重建与主节点完全一致的事务。
假设应用程序完整的事务是begin-insert-update-commit,并开启事务保持功能。事务开始执行时,PolarProxy在将SQL语句转发给主节点的同时,会缓存最近执行的SQL语句。当INSERT操作在主节点执行成功后,PolarDB会自动保存最近一条语句的Savepoint来作为事务信息的一部分。通过Session Tracker将当前的会话信息和事务信息返回给PolarProxy,PolarProxy会将这些数据临时保存在内部缓存中。其中,会话信息用于连接保持,如字符集和用户变量等信息;事务信息用于事务保持,如trx_id、undo_no等信息。此外,事务信息会通过一个单独的RDMA链路,持续高效地同步到热备中。如果后端数据库开启了Binlog,还会将每个事务对应的本地Binlog缓存同步到热备中。
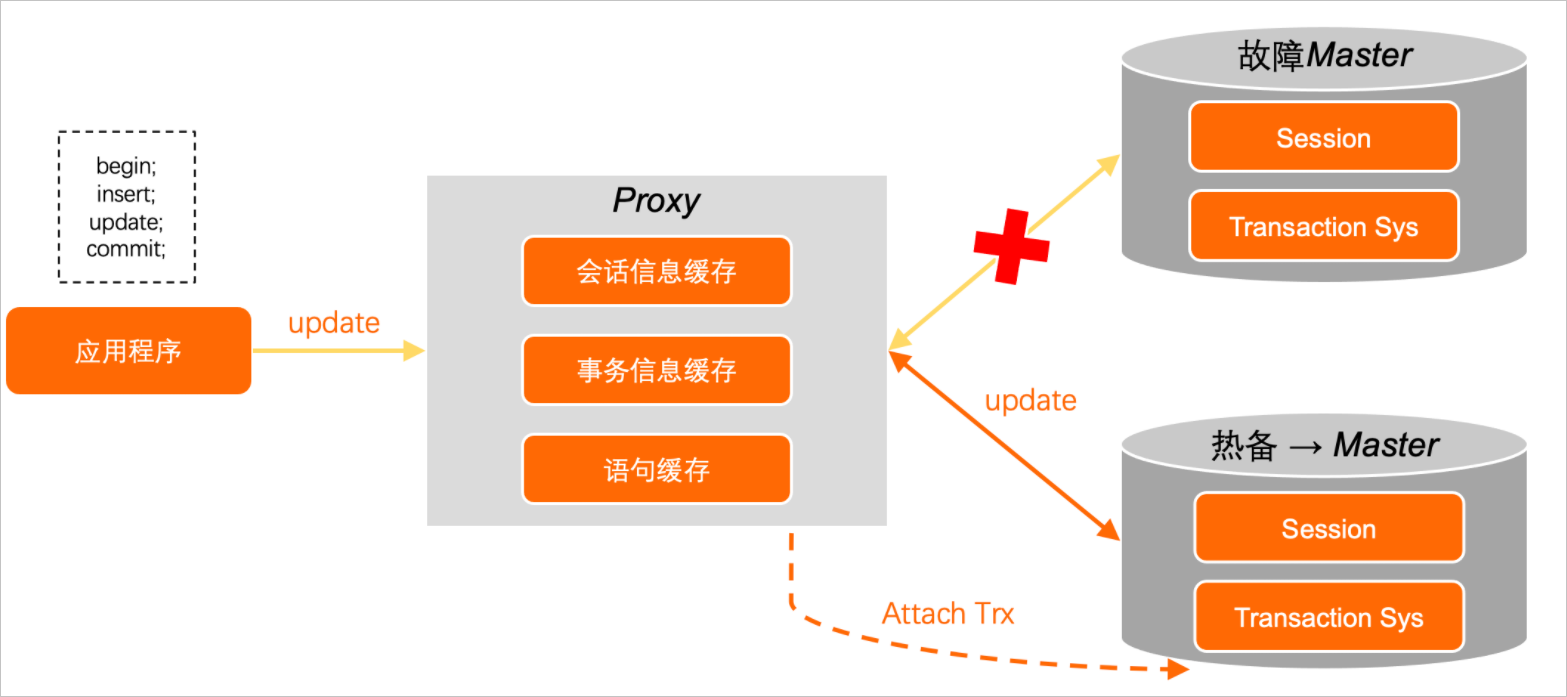
假设应用程序在PolarDB执行UPDATE的过程中,主节点出现故障。此时PolarProxy并不会立刻将底层的报错传给应用连接,而是将整个请求hold一段时间。热备切换选主之后,新的主节点通过Redo Log构建出所有的未提交事务,并异步等待未提交的事务,且暂时不进行回滚。PolarProxy在探测到主备切换成功信息后,会利用自身缓存的会话信息和事务信息,借助PolarDB的Attach Trx接口,桥接事务状态。PolarDB会根据PolarProxy信息,判断相关的事务信息是否有效。如果事务有效,会将事务信息绑定到这个连接上,并回滚至最后一条语句(即上文的UPDATE)对应undo_no的Savepoint中。
当事务桥接成功后,PolarProxy就可以从SQL语句缓存中,将最近一次未执行成功的UPDATE操作重新发送给新的主节点。从用户角度来看,整个主备切换过程,应用程序只感知到一条执行时间变慢的UPDATE语句,但不会接收到任何连接报错或事务报错。
热备无感秒切通过VDS、全局预热系统、连接保持和事务保持三大特性,解决了PolarDB的故障探测、切换速度和切换体验问题。用户可以在任意时刻对集群进行升配,而无需担心连接中断或事务中断问题,真正实现了云原生数据库的弹性承诺。
免费体验
阿里云提供了数据库解决方案功能体验馆。您无需购买任何资源,即可在线体验PolarDB MySQL版热备无感秒切的效果。
您可前往体验PolarDB MySQL无感切换进行体验,详情请参见免费体验PolarDB MySQL热备无感秒切。
- 本页导读 (0)