

本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何使用数据传输服务DTS(Data Transmission Service),将云数据库MongoDB版(副本集架构或分片集群架构)迁移至云原生多模数据库Lindorm。
前提条件
云数据库MongoDB版为副本集架构或分片集群架构。
重要若源库为分片集群架构的云数据库MongoDB版,则需为Shard节点申请连接地址,且各Shard的账号和密码需保持一致。申请方法,请参见申请Shard或ConfigServer节点连接地址。
已创建目标云原生多模数据库Lindorm实例,且数据库引擎是为宽表引擎,创建方式请参见创建实例。
已根据业务需求在Lindorm中创建宽表,创建方式请参见通过Lindorm-cli连接并使用宽表引擎或通过Lindorm Shell访问宽表引擎。
说明若Lindorm中的宽表是用HBase创建的,建议您为表添加列映射关系(即宽表的列为普通列),详情请参见HBase表添加列映射示例。
建议目标实例的存储空间比源数据库已使用的存储空间大10%。
注意事项
类型 | 说明 |
源库限制 |
|
其他限制 |
|
费用说明
迁移类型 | 链路配置费用 | 公网流量费用 |
全量数据迁移 | 不收费。 | 通过公网将数据迁移出阿里云时将收费,详情请参见计费概述。 |
增量数据迁移 | 收费,详情请参见计费概述。 |
迁移类型说明
迁移类型 | 说明 |
全量迁移 | 将源云数据库MongoDB版迁移对象的存量数据全部迁移到目标云原生多模数据库Lindorm中。 说明 支持全量迁移DATABASE和COLLECTION中的数据。 |
增量迁移 | 在全量迁移的基础上,将源云数据库MongoDB版的增量更新迁移到目标云原生多模数据库Lindorm中。 说明 仅支持增量迁移在集合中插入、更新、删除文档的操作。 |
数据库账号的权限要求
数据库 | 全量迁移 | 增量迁移 | 账号创建及授权方法 |
源云数据库MongoDB版 | 待迁移库的read权限。 | 待迁移库、admin库和local库的read权限。 | |
目标云原生多模数据库Lindorm | 云原生多模数据库Lindorm的read和write权限。 | ||
操作步骤
本操作的目标库以Lindorm SQL创建的宽表为例进行介绍。
进入迁移任务的列表页面。
登录DMS数据管理服务。
在顶部菜单栏中,单击集成与开发(DTS)。
在左侧导航栏,选择。
说明您也可以登录新版DTS迁移任务的列表页面。
在迁移任务右侧,选择源实例所属地域。
说明新版DTS迁移任务列表页面,需要在页面左上角选择迁移实例所属地域。
单击创建任务,配置源库及目标库信息。
类别
配置
说明
无
任务名称
DTS会自动生成一个任务名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源库信息
选择已有的DMS数据库实例
您可以按实际需求,选择是否使用已有实例。
如使用已有实例,下方数据库信息将自动填入,您无需重复输入。
如不使用已有实例,您需要输入下方的数据库信息。
数据库类型
选择MongoDB。
接入方式
选择云实例。
实例地区
选择源云数据库MongoDB版所属地域。
是否跨阿里云账号
本示例为同一阿里云账号间的迁移,选择不跨账号。
架构类型
本示例选择副本集架构。
说明若您的源云数据库MongoDB版为分片集群架构,您还需要填写shard账号和shard密码。
实例ID
选择源云数据库MongoDB版实例ID。
鉴权数据库名称
填入源云数据库MongoDB版实例中数据库账号所属的数据库名称,若未修改过则默认为admin。
数据库账号
填入源云数据库MongoDB版的数据库账号。
数据库密码
填入该数据库账号对应的密码。
目标库信息
选择已有的DMS数据库实例
您可以按实际需求,选择是否使用已有实例。
如使用已有实例,下方数据库信息将自动填入,您无需重复输入。
如不使用已有实例,您需要输入下方的数据库信息。
数据库类型
选择Lindorm。
接入方式
选择云实例。
实例地区
选择目标云原生多模数据库Lindorm所属地域。
实例ID
选择目标云原生多模数据库Lindorm的实例ID。
数据库账号
填入目标云原生多模数据库Lindorm的数据库账号。
数据库密码
填入该数据库账号对应的密码。
配置完成后,单击页面下方的测试连接以进行下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
进行数据迁移配置。
配置
说明
迁移类型
如果只需要进行全量迁移,请选中全量迁移。
如果需要进行不停机迁移,请同时选中全量迁移和增量迁移。
说明如果未选择增量迁移,为保障数据一致性,数据迁移期间请勿在源实例中写入新的数据。
目标已存在表的处理模式
预检查并报错拦截:检查目标数据库中是否有同名的集合。如果目标数据库中没有同名的集合,则通过该检查项目;如果目标数据库中有同名的集合,则在预检查阶段提示错误,数据迁移任务不会被启动。
说明如果目标库中同名的集合不方便删除或重命名,您可以更改该集合在目标库中的名称,请参见库表列名映射。
忽略报错并继续执行:跳过目标数据库中是否有同名集合的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
在目标库遇到与源库主键的值相同的记录,则会保留目标库中的该条记录,即源库中的该条记录不会迁移至目标库中。
可能会导致无法初始化数据、只能迁移部分的数据或迁移失败。
目标库对象名称大小写策略
您可以配置目标实例中同步对象的库名和集合名的英文大小写策略。默认情况下选择DTS默认策略,您也可以选择与源库或目标库默认策略保持一致。更多信息,请参见目标库对象名称大小写策略。
源库对象
在源库对象框中单击待迁移的集合,然后单击
 将其移动至已选择对象框。
将其移动至已选择对象框。已选择对象
若目标库中的宽表是通过Lindorm SQL创建的,需要通过配置新增列的方式迁移数据,未配置的列不会迁移至目标库。
编辑库名映射。
右键单击已选择对象中的待迁移集合所属的库。
将Schema名称修改为Lindorm中目标库的名称。
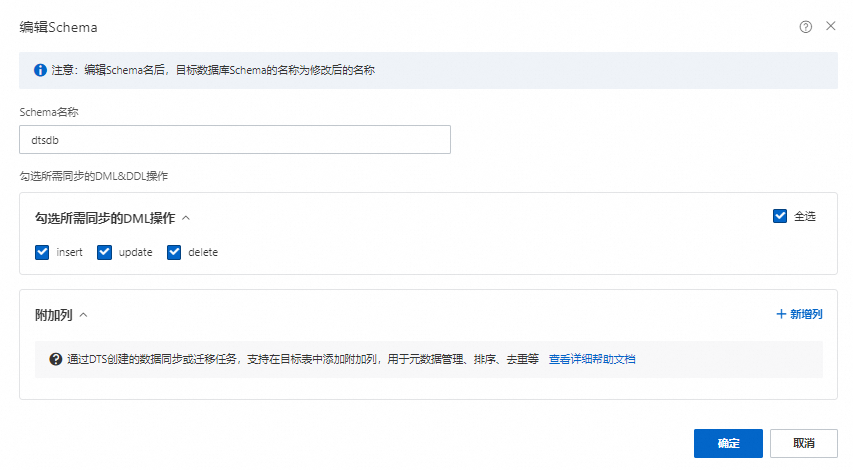
可选:在勾选所需同步的DML&DDL操作区域选择所需增量迁移的操作。
单击确定。
编辑表名映射。
右击已选择对象中的待迁移的集合。
将表名称修改为Lindorm中目标表的名称。
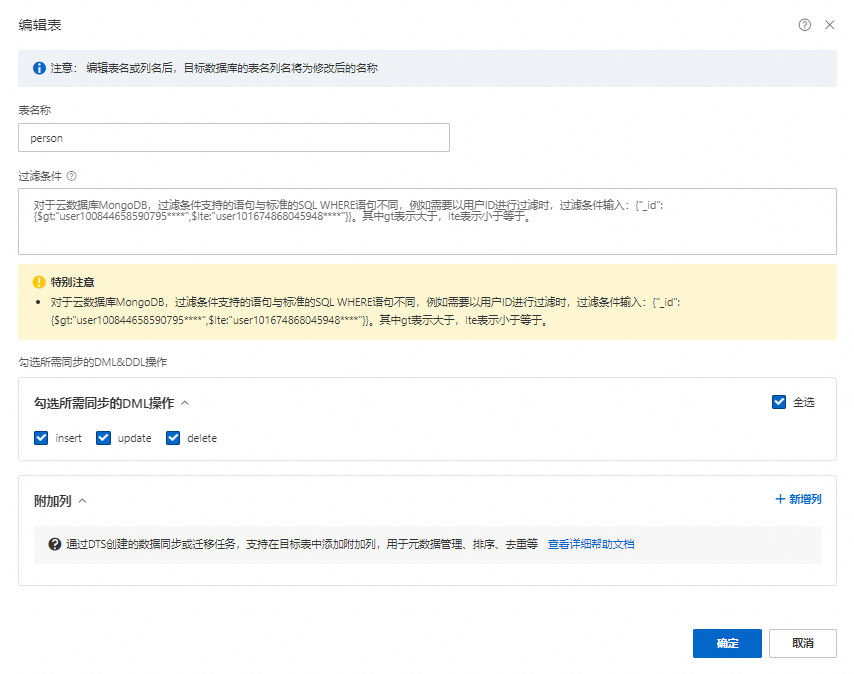
可选:设置过滤条件,设置方法请参见设置过滤条件。
可选:在勾选所需同步的DML&DDL操作区域选择所需增量迁移的操作。
配置MongoDB中需要迁移的字段(Field)。
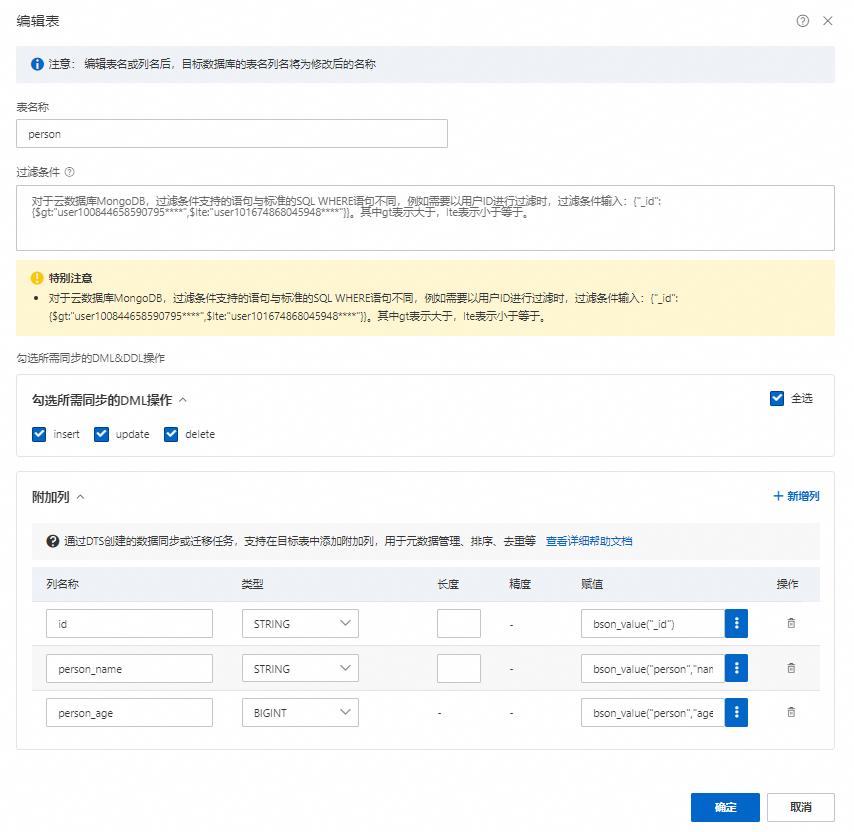
单击+ 新增列。
填写列名称。
说明此处填写的是Lindorm中目标表的列名。
若目标表是用SQL创建的,列名称填写的是Lindorm中目标表的列名。
若目标表是用HBase创建的且需要使用新增列功能,在修改列名称前您需要提前添加列映射关系,详情请参见HBase表添加列映射示例。列名称填写内容如下:
该列是主键:填写为ROW。
该列不是主键:填写格式为列族:列名,如person:name。
选择列数据的类型。
可选:配置列数据的长度和精度。
在赋值下方的文本框中填写
bson_value()表达式,详情请参见赋值配置示例。
单击下一步高级配置,进行高级配置。
配置
说明
选择调度该任务的专属集群
DTS默认将任务调度到共享集群上,您无需选择。若您希望任务更加稳定,可以购买专属集群来运行DTS迁移任务。更多信息,请参见什么是DTS专属集群。
设置告警
是否设置告警,当迁移失败或延迟超过阈值后,将通知告警联系人。
不设置:不设置告警。
设置:设置告警,您还需要设置告警阈值和告警联系人。更多信息,请参见在配置任务过程中配置监控报警。
源库、目标库无法连接后的重试时间
在迁移任务启动后,若源库或目标库连接失败则DTS会报错,并会立即进行持续的重试连接,默认重试720分钟,您也可以在取值范围(10~1440分钟)内自定义重试时间,建议设置30分钟以上。如果DTS在设置的时间内重新连接上源、目标库,迁移任务将自动恢复。否则,迁移任务将失败。
说明针对同源或者同目标的多个DTS实例,网络重试时间以后创建任务的设置为准。
由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
源库、目标库出现其他问题后的重试时间
在迁移任务启动后,若源库或目标库出现非连接性的其他问题(如DDL或DML执行异常),则DTS会报错并会立即进行持续的重试操作,默认持续重试时间为10分钟,您也可以在取值范围(1~1440分钟)内自定义重试时间,建议设置10分钟以上。如果DTS在设置的重试时间内相关操作执行成功,迁移任务将自动恢复。否则,迁移任务将会失败。
重要源库、目标库出现其他问题后的重试时间的值需要小于源库、目标库无法连接后的重试时间的值。
是否限制全量迁移速率
在全量迁移阶段,DTS将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升。您可以根据实际情况,选择是否对全量迁移任务进行限速设置(设置每秒查询源库的速率QPS、每秒全量迁移的行数RPS和每秒全量迁移的数据量(MB)BPS),以缓解目标库的压力。
说明仅当迁移类型选择了全量迁移时才可以配置。
是否限制增量迁移速率
您也可以根据实际情况,选择是否对增量迁移任务进行限速设置(设置每秒增量迁移的行数RPS和每秒增量迁移的数据量(MB)BPS),以缓解目标库的压力。
说明仅当迁移类型选择了增量迁移时才可以配置。
环境标签
您可以根据实际情况,选择用于标识实例的环境标签。本示例无需选择。
配置ETL功能
选择是否配置ETL功能。关于ETL的更多信息,请参见什么是ETL。
是:配置ETL功能,并在文本框中填写数据处理语句,详情请参见在DTS迁移或同步任务中配置ETL。
否:不配置ETL功能。
说明若目标表是用HBase创建的,请注意如下事项:
ETL的语法包括需要配置的列和需要排除的列,在迁移过程中会将MongoDB已配置ETL的文档(Document)所有顶层字段,存储在HBase表默认的列族f中。以下示例表示:将除_id和name两个顶层元素的其他元素作为动态列写入目标表。更多信息,请参见HBase表迁移示例(ETL)。
script:e_expand_bson_value("*", "_id,name")若您需要同时使用新增列和ETL功能,请确保Lindorm中的数据不会重复。
新增列和ETL功能均未配置的列不会迁移至目标库。
上述配置完成后,单击页下方的下一步保存任务并预检查。
说明在迁移任务正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动迁移任务。
如果预检查失败,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
如果预检查产生警告:
对于不可以忽略的检查项,请单击失败检查项后的查看详情,并根据提示修复后重新进行预检查。
对于可以忽略无需修复的检查项,您可以依次单击点击确认告警详情、确认屏蔽、确定、重新进行预检查,跳过告警检查项重新进行预检查。如果选择屏蔽告警检查项,可能会导致数据不一致等问题,给业务带来风险。
预检查通过率显示为100%时,单击下一步购买。
在购买页面,选择数据迁移实例的链路规格,详细说明请参见下表。
类别
参数
说明
信息配置
资源组配置
选择实例所属的资源组,默认为default resource group。更多信息,请参见什么是资源管理。
链路规格
DTS为您提供了不同性能的迁移规格,迁移链路规格的不同会影响迁移速率,您可以根据业务场景进行选择。更多信息,请参见数据迁移链路规格说明。
配置完成后,阅读并勾选《数据传输(按量付费)服务条款》。
单击购买并启动,迁移任务正式开始,您可在数据迁移界面查看具体进度。
HBase表添加列映射示例
本示例以在SQL Shell上操作为例介绍。
Lindorm须为2.4.0及以上版本。
为HBase创建的表添加列映射。
ALTER TABLE test MAP DYNAMIC COLUMN f:_mongo_id_ HSTRING/HINT/..., person:name HSTRING, person:age HINT;为HBase创建的表添加二级索引。
CREATE INDEX idx ON test(f:_mongo_id_);
HBase表迁移示例(ETL)
MongoDB文档(Document)
{
"_id" : 0,
"person" : {
"name" : "cindy0",
"age" : 0,
"student" : true
}
}ETL数据处理语句
script:e_expand_bson_value("*", "_id")迁移结果

赋值配置示例
源MongoDB数据结构
{
"_id":"62cd344c85c1ea6a2a9f****",
"person":{
"name":"neo",
"age":"26",
"sex":"male"
}
}目标Lindorm表结构
列名称 | 类型 |
id | STRING |
person_name | STRING |
person_age | INT |
新增列配置
列名称 | 类型 | 赋值 |
id | STRING | bson_value("_id") |
person_name | STRING | bson_value("person","name") |
person_age | BIGINT | bson_value("person","age") |
- 本页导读 (1)