通过分箱组件可以进行特征离散化,即将连续的数据进行分段,使其变为多个离散化区间。分箱组件支持等频分箱、等宽分箱及自动分箱。
配置组件
您可以使用以下任意一种方式,配置分箱组件参数。
方式一:可视化方式
在Designer工作流页面配置组件参数。
页签 | 参数 | 描述 |
字段设置 | 特征列 | 支持STRING、BIGINT及DOUBLE类型。 |
标签列 | 仅支持二分类。 | |
正例值 | 仅当标签列存在时才生效。 | |
选择分箱的参数来源 | 参数来源支持“参数设置”中的参数和手动分箱或自定义Json。 | |
是否保留没有在“特征列”中选择的字段 | 使用自定义分箱时,如果该参数选择是,则未在特征列中选择的字段会原样保留,否则会删除未选择的字段。 | |
上传分箱和约束Json | 当选择分箱的参数来源取值为手动分箱或自定义Json时,该参数生效。 | |
参数设置 | 分箱个数 | 配置为10,表示将连续特征离散化至10个区间中。 |
自定义列分箱个数 | 可以指定单个或多个字段的分箱数,会覆写总的分箱个数。如果自定义的列不在字段选择中,则多出的列也会进行计算。例如,字段选择为col0和col1, 自定义分箱为col0:3,col2:5,当分箱个数为10时,那么按照col0:3,col1:10,col2:5进行计算。 取值格式为:字段名1:分箱个数, 字段名2:分箱个数。 | |
自定义离散值个数阈值 | 格式为col0:3。 | |
区间选择 | 支持左开右闭或左闭右开区间。 | |
分箱方式 | 支持等频、等宽及自动分箱。 | |
离散值个数阈值 | 如果小于该值,则分到“其它”分箱。 | |
执行调优 | 核心数 | 默认系统自动分配。 |
每个核分配的内存数 | 默认系统自动分配。 |
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
PAI -name binning
-project algo_public
-DinputTableName=input
-DoutputTableName=output参数 | 描述 | 是否必选 | 默认值 |
inputTableName | 输入表的名称。 | 是 | 无 |
outputTableName | 输出表的名称。 | 是 | 无 |
selectedColNames | 输入表选择分箱的列。 | 否 | 除Label外的其他列,如果无Label,则选择全部。 |
labelColName | Label所在的列。 | 否 | 无 |
validTableName | 表示binningMethod为auto时输入的验证表名。在auto模式下,该参数为必选。 | 否 | 空 |
validTablePartitions | 验证表选择的分区。 | 否 | 全表 |
inputTablePartitions | 输入表选择的分区。 | 否 | 全表 |
inputBinTableName | 输入的分箱表。 | 否 | 无 |
selectedBinColNames | 分箱表选择的列。 | 否 | 空 |
positiveLabel | 输出正样本的分类。 | 否 | 1 |
nDivide | 分箱的个数,取值为正整数。 | 否 | 10 |
colsNDivide | 自定义列的分箱个数,例如col0:3,col2:5。如果colsNDivide中选中的列不在selectedColNames中,则多出的列也会进行计算。例如,selectedColNames为col0,col1,colsNDivide为col0:3,col2:5,nDivide为10时,则按照col0:3,col1:10,col2:5进行计算。 | 否 | 空 |
isLeftOpen | 选择区间为左开右闭或左闭右开,取值包括为:
| 否 | true |
stringThreshold | 离散值为其他分箱的阈值。 | 否 | 无 |
colsStringThreshold | 自定义列的阈值,同colsNDivide。 | 否 | 空 |
binningMethod | 分箱类型,取值包括:
| 否 | quantile |
lifecycle | 输出表的生命周期,取值为正整数。 | 否 | 无 |
coreNum | 核心数,取值为正整数。 | 否 | 系统自动计算 |
memSizePerCore | 内存数,取值为正整数。 | 否 | 系统自动计算 |
分箱约束功能需要与评分卡训练组件配合使用。在评分卡训练过程中通过分箱进行特征工程,将特征离散化生成Dummy变量,并对训练过程中的每个Dummy变量的权重增加一定约束。各个约束项的含义如下:
顺序升序约束:该特征的各个Dummy变量按照Index从小到大添加权重上升的约束,即Index越大,权重越大。
顺序降序约束:该特征的各个Dummy变量按照Index从小到大添加权重下降的约束,即Index越大,权重越小。
相等权重值:该特征两个Dummy变量的权重值相等的约束。
权重值为0:该特征某个Dummy变量的权重值为0的约束。
等于固定权重值:该特征某个Dummy变量的权重值等于固定浮点数值的约束。
WOE值顺序约束:该特征各个Dummy变量按照WOE值从小到大添加权重上升的约束,即WOE值越大,权重值越大。
结果演示
使用分箱组件的工作流运行结束后,右键单击画布中的分箱组件,在快捷菜单,单击我要分箱。
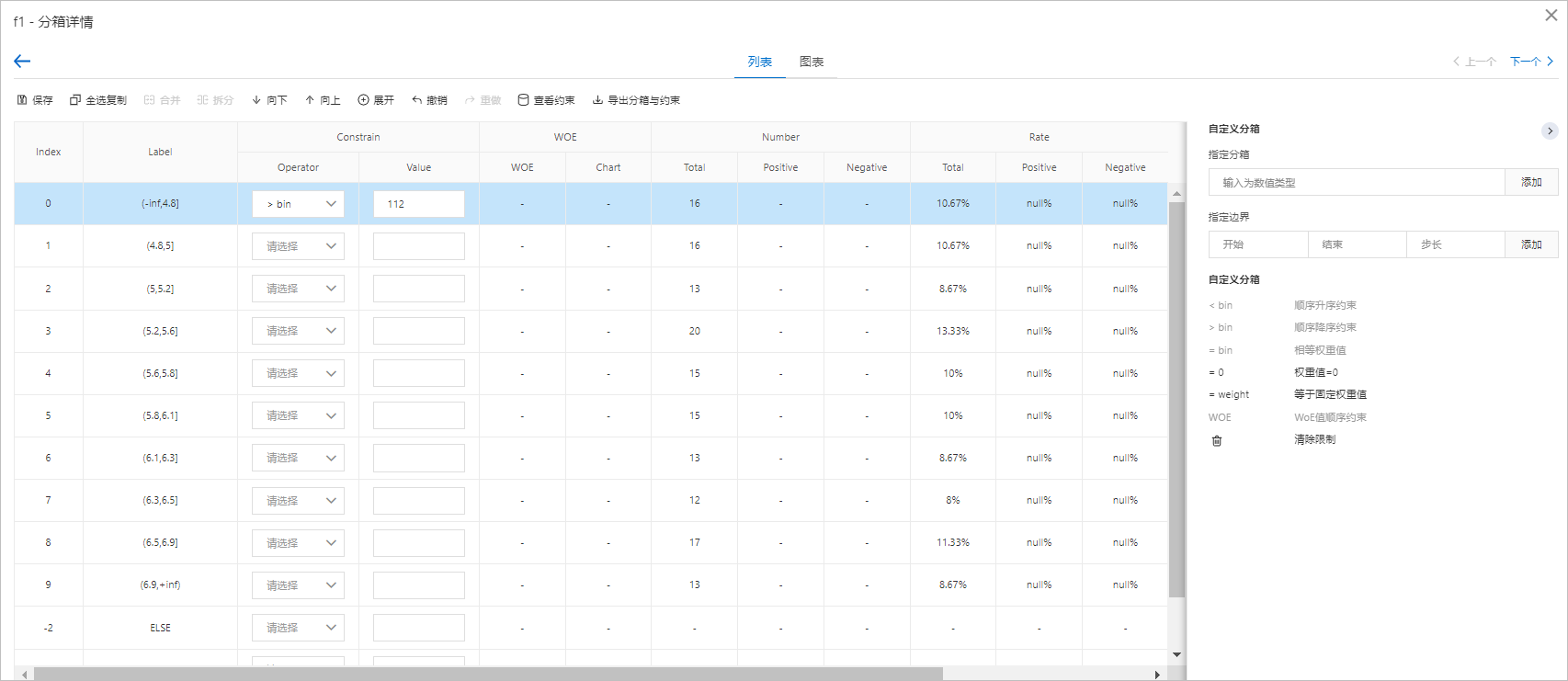
在变量列表页面,您可以查看每个变量的分箱数、类型、IV等信息,具体如下图所示。
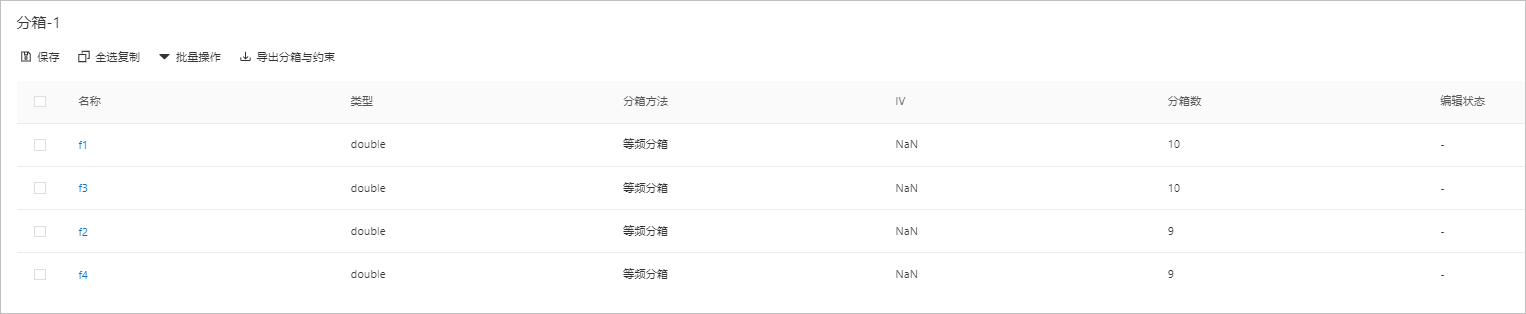
单击变量的名称(以f1为例),可以打开f1-分箱详情页面,该页面详情如下图所示。
您可以在该页面对分箱进行合并、拆分,也可以对分箱增加约束。
说明约束仅对后续的评分卡训练模块有效,如果仅使用分箱,不使用评分卡训练,则可以忽略约束项。