PolarDB MySQL版目前支持集群版和多主集群(库表)2种不同的产品系列。本文将简要介绍2种产品系列的产品架构、优势和适用场景等信息。
2种产品系列的适用场景对比如下表所示:
系列 | 说明 | 适用场景 |
集群版 | 使用计算与存储分离的架构,提供更快的弹性扩缩容、更大的存储容量、更低的主备延迟。 |
|
多主集群(库表) | 在一个集群中通过多个主节点来实现从一写多读架构到多写多读架构的升级。集群中所有的数据文件都存放在共享存储(PolarStore)中,各个主节点通过分布式文件系统(PolarFileSystem)共享底层存储(PolarStore)中的数据文件。用户可以通过集群地址访问整个集群,数据库代理会自动转发SQL命令到正确的主节点。 |
|
集群版
集群版使用计算与存储分离的架构,提供更快的弹性扩缩容、更大的存储容量、更低的主备延迟。
一写多读
PolarDB采用分布式集群架构,一个集群版集群包含一个主节点和最多15个只读节点(可以只包含一个主节点),多个数据库节点构成数据库引擎层。主节点处理读写请求,只读节点仅处理读请求。主节点和只读节点之间采用Active-Active的Failover方式,提供数据库的高可用服务。
共享分布式存储(PolarStore)
多个计算节点共享一份数据,而不是每个计算节点都存储一份数据,极大降低了用户的存储成本。基于分布式块存储和文件系统,存储容量可以在线平滑扩展,不会受到单个数据库服务器的存储容量限制,可应对上百TB级别的数据规模。
计算与存储分离
采用计算与存储分离的架构,满足公共云计算环境下根据业务发展弹性扩展集群的刚性需求。数据库的计算节点仅存储元数据,而将数据文件、Redo Log等存储在共享分布式存储(PolarStore)的数据库存储节点中。各计算节点之间仅需同步Redo Log相关的元数据信息,极大降低了主节点和只读节点间的复制延迟,而且在主节点故障时,只读节点可以快速切换为主节点。
读写分离
数据库代理的读写分离功能是集群版默认提供的一个透明、高可用、自适应的负载均衡能力。通过集群地址,SQL请求自动转发到集群版的各个数据库节点,提供聚合、高吞吐的并发SQL处理能力。具体请参见什么是读写分离。
高速链路互联
数据库的计算节点和存储节点之间采用高速网络互联,并通过RDMA协议进行数据传输,使I/O性能不再成为瓶颈。
数据可靠性和一致性
数据库存储节点的数据采用多副本形式,确保数据的可靠性,并通过Parallel-Raft协议保证数据的一致性。
产品架构
集群版的架构图如下: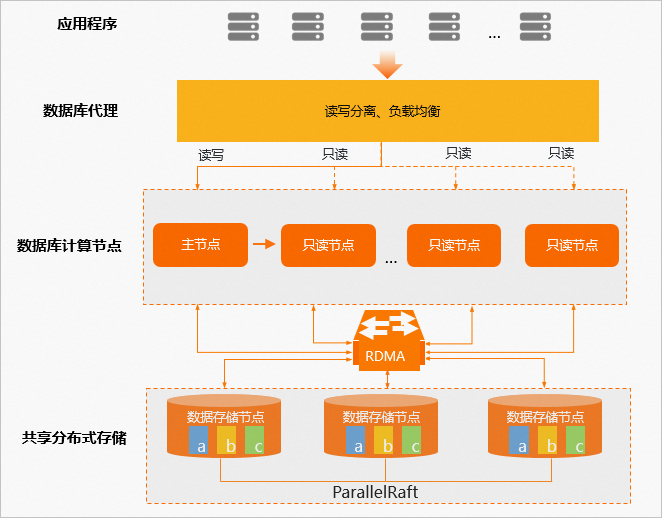
支持的内核版本
集群版目前支持PolarDB MySQL版5.6、5.7和8.0三个内核版本。
适用场景
大中型企业的生产数据库。
互联网、物联网、零售电商、物流、游戏等行业的数据库。
对数据安全性要求非常高的金融、证券、保险行业的核心数据库。
节点规格与定价
集群版支持独享规格和通用规格。更多详情,请参见计费项概览。
多主集群(库表)
PolarDB MySQL版推出多主集群(库表),实现从一写多读架构到多写多读架构的升级,提升了数据库的并发读写能力。
产品架构
多主集群(库表)的架构图如下: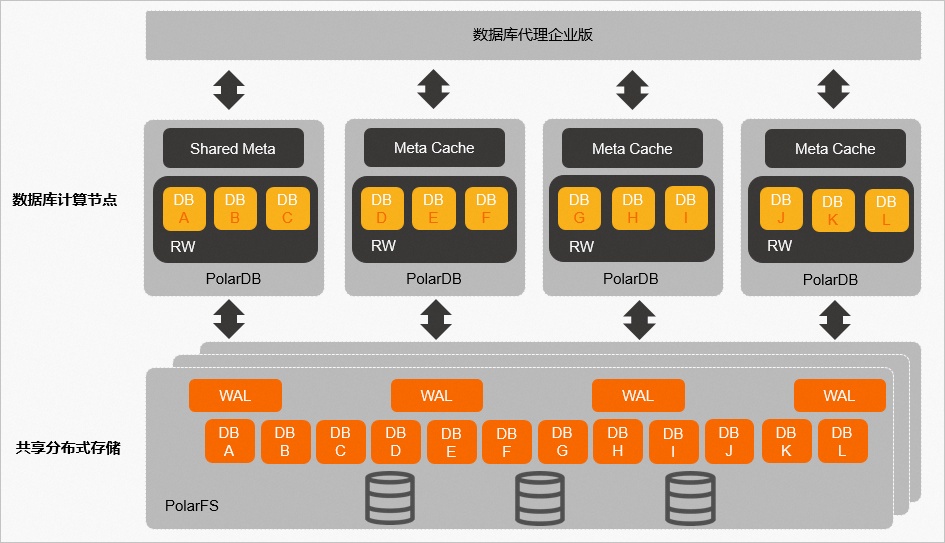
集群中所有的数据文件都存放在共享分布式存储(PolarStore)中,各个RW节点通过分布式文件系统(PolarFileSystem)共享底层存储(PolarStore)中的数据文件。用户可以通过集群地址访问整个集群,数据库代理会自动转发SQL命令到正确的RW节点。
支持的内核版本
目前仅PolarDB MySQL版8.0内核版本支持多主集群(库表)。
产品优势
秒级横向写扩展
支持不同库/表在不同计算节点并发写入,最多支持32个节点同时写入。不同数据库可以在不同计算节点秒级动态调度,极大提升整体的并发读写能力。
多主互备(省去备节点)
如果某个主节点发生故障,可秒级切换到其他低流量主节点,同时由于没有额外的用于热备的闲置资源,成本降低一半。
全局只读节点
可以在全局只读节点上读取到所有写节点的数据,方便执行汇聚库的请求。
适用场景
多主集群(库表)主要面向SaaS多租户、游戏、电商等高并发读写的应用场景。
SaaS多租户场景:满足高并发性能需求,实现租户间负载均衡
多主集群(库表)可帮助客户秒级将租户的数据库在不同RW节点间进行切换,或秒级增加新的RW节点承担突发流量,从而实现负载均衡。
世界服游戏及电商场景:分钟级的扩缩容,适应快速增长的业务请求
多主集群(库表)的秒级横向扩展和透明路由功能,结合中间件或业务分库分表可以实现透明的秒级扩展,将原来数天的扩容变为分钟级。
分服游戏场景:更好的性能和扩展能力,灵活扩缩容
游戏成长期,可快速将部分数据库切换到新的RW节点,实现负载均衡;游戏衰退期,可快速将数据库聚合到少量RW节点,快速降低运作成本。
节点规格与定价
多主集群(库表)支持独享规格和通用规格。更多详情,请参见企业版计算节点规格。
关于多主集群(库表)的计费详情,请参见产品计费。
- 本页导读 (0)