本文通过查询、关联分析、统计分析等场景介绍如何使用日志服务对程序日志进行查询和分析。
背景信息
程序日志内容全、存在一定共性,它是运维程序的重要信息,但程序日志具有如下不便于存储与分析的特性:
格式随意:不同开发者的代码风格不同,对应的日志风格也不同,难以统一。
数据量大:程序日志一般比访问日志大1个数量级。
分布的服务器多:大部分应用为无状态模式,运行在不同框架中,例如云服务器、容器服务等,对应的实例数从几个到数千个,需要有一种跨服务器的日志采集方案。
运行环境复杂:程序运行在不同的环境中,产生的日志也保存在不同的环境中,例如应用相关的日志在容器中、API相关日志在FunctionCompute中、旧系统日志在本地IDC中、移动端相关日志在用户处、网页端日志在浏览器中等。
为了能够获得全量日志,必须把所有日志统一存储。针对该场景,日志服务提供多样化的日志采集方式及一站式分析功能,您可通过查询+SQL92语法对日志进行实时分析,并以图表形式直观展示分析结果。和开源方案对比,日志服务提供的解决方案在查询分析成本上仅是开源方案的25%。
查询程序日志
例如某App出现订单错误或请求延时等问题,您可以通过查询语句在TB级数据量的日志中快速(1s内)定位问题。还可以根据业务需求,设置时间范围、查询关键字等信息,更精准地返回查询结果。
查询延时大于1s,并且请求方法是以Post开头的请求数据。
Latency > 1000000 and Method=Post*查找包含error关键词但不包含merge关键词的日志。
error not merge
关联分析程序日志
关联分析包括进程内关联与跨进程关联,区别如下:
进程内关联:一般比较简单,因为同一个进程前后日志都在一个文件中。在多线程环境中,只需根据线程ID进行过滤即可。
跨进程关联:跨进程的请求一般没有明确线索,一般通过RPC中传入的TracerId来进行关联。

进程内关联
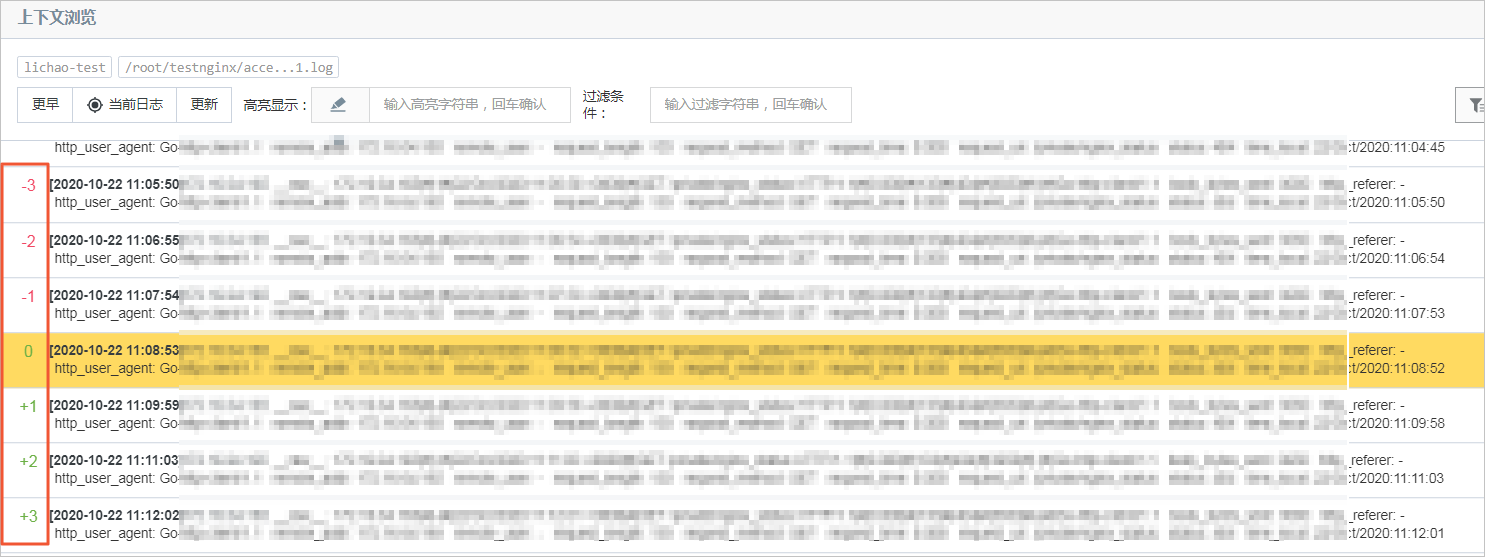
通过上下文查询查看关联日志。例如通过关键词查询定位到一个异常日志,然后单击上下文浏览,查看该日志前后N条日志,操作步骤请参见上下文查询。

上下文查询结果如下所示:
跨进程关联
跨进程关联也叫Tracing,比较常见的工具有鹰眼、Dapper、StackDriver Trace、Zipkin、Appdash、X-ray等。
此处基于日志服务,实现基本的Tracing功能。您可以在各模块日志中输出Request_id、OrderId等可以关联的标识字段,通过在不同的日志库中查找,获取所有相关日志。
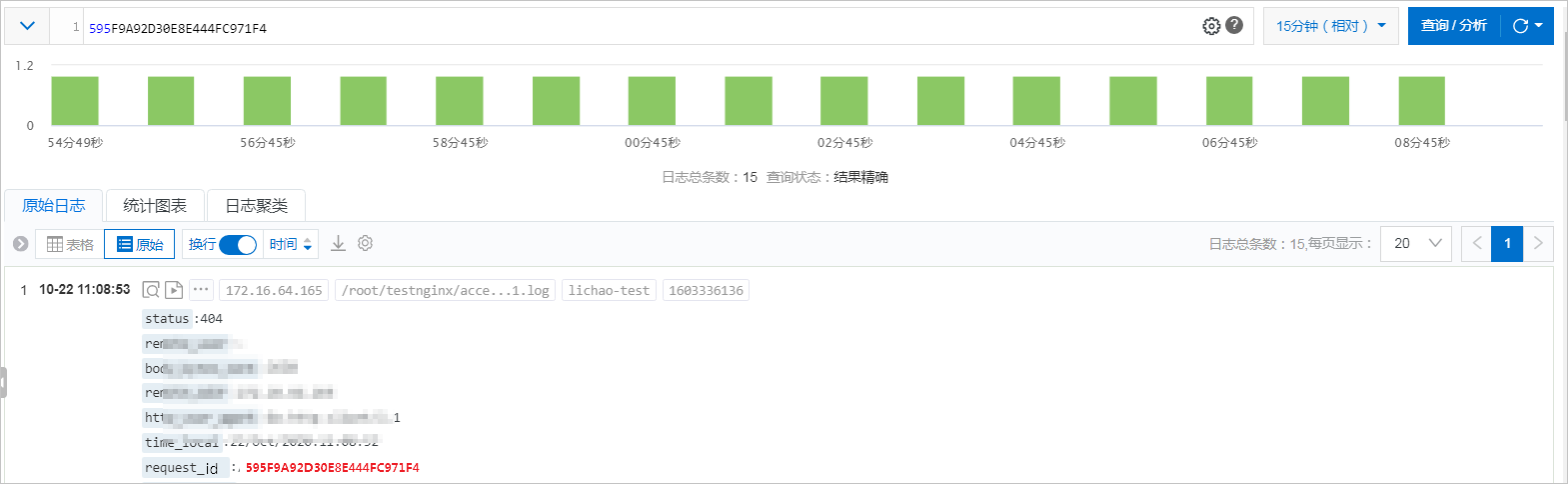
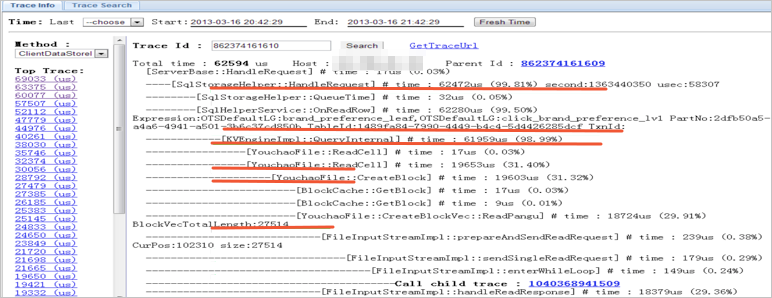
例如通过SDK查询前端机、后端机、支付系统、订单系统等日志。获得结果后,制作一个前端页面将跨进程分析关联起来,如下图所示。
统计分析程序日志
查询到日志后,您还可以做进一步统计分析。
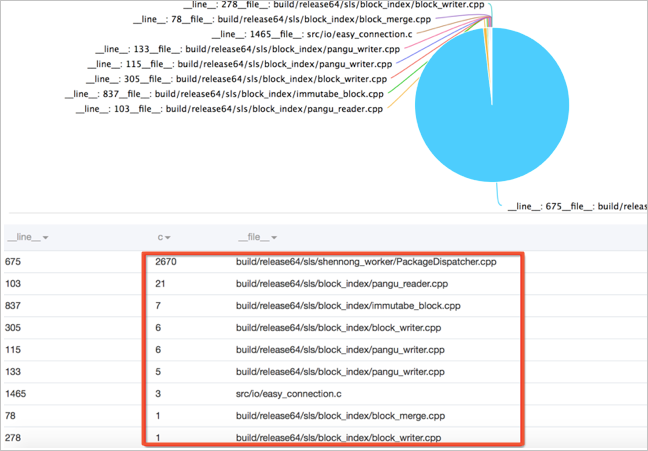
执行如下查询分析语句,统计所有错误发生的类型和位置的分布。
__level__:error | select __file__, __line__, count(*) as c group by __file__, __line__ order by c desc