您可以通过加速弹性客户端存储卷的监控仪表板定位分析客户端的IO操作问题,并定位到问题所在的相关业务(Pod)。例如,哪些频繁的操作会导致系统繁忙占用大量带宽等常见的客户端IO问题。本文通过示例介绍如何通过CNFS可观测性定位这些问题。
索引
前提条件
已创建Kubernetes托管版集群,且集群版本大于1.20,存储插件选择为CSI。具体操作,请参见创建Kubernetes托管版集群。
CSI-Plugin和CSI-Provisioner组件版本不低于v1.24.9-74f8490-aliyun。关于升级CSI-Plugin和CSI-Provisioner组件的操作,请参见管理CSI组件。
已通过CNFS方式挂载使用弹性客户端。具体操作,请参见开启CNFS NAS计算端分布式缓存。
存储插件监控功能费用说明
启用存储插件CSI监控功能后,相关组件会自动将监控指标发送至阿里云Prometheus服务,这些指标将被视为自定义指标。使用自定义指标可能会引起额外的费用。
为了避免产生额外的费用,建议在启用此功能前,仔细阅读阿里云Prometheus的计费概述,了解自定义指标的收费策略。费用将根据您的集群规模和应用数量等因素产生变动。您可以通过资源消耗统计功能,监控和管理您的资源使用情况。
存储监控仪表板大盘介绍
大盘名称 | 说明 |
Frontend Storage IO Monitoring (Cluster Level) | 加速弹性客户端访问缓存的IO监控(集群维度)的大盘,以NAS或CPFS的ID为过滤选项,存储重要指标的统计。 |
Backend Storage IO Monitoring (Cluster Level) | 加速弹性客户端访问NAS存储服务端的IO监控(集群维度)的大盘,以NAS或CPFS的ID为过滤选项,存储重要指标的统计。 |
Container Storage IO Monitoring (Cluster Level) | 加速弹性客户端访问缓存的存储IO监控(集群维度)的大盘,TOPN Pod的重要指标的统计。 |
Pod IO Monitoring (Pod Level) | 加速弹性客户端访问缓存的容器组IO监控(容器组维度)的大盘,以Pod为过滤选项,存储卷重要指标的统计。 |
存储卷监控仪表板的大盘指标属于自定义类的指标。关于自定义指标的收费,请参见收费说明。
查看存储监控仪表板大盘
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus监控页面,单击存储监控页签。
在存储监控页签,单击Frontend Storage IO Monitoring (Cluster Level),查看加速弹性客户端访问缓存的IO监控(集群维度)的大盘。
在存储监控页签,单击Backend Storage IO Monitoring (Cluster Level),查看加速弹性客户端访问NAS存储服务端的IO监控(集群维度)的大盘。
在存储监控页签,单击Container Storage IO Monitoring (Cluster Level),查看加速弹性客户端访问缓存的存储IO监控(集群维度)的大盘。
在存储监控页签,单击Pod IO Monitoring (Pod Level),查看加速弹性客户端访问缓存的容器组IO监控(容器组维度)的大盘。
定位容器内应用的IO问题
以下问题定位的示例均以NAS存储卷的读操作为例进行说明,CPFS问题定位的操作类似。
问题1:如何查看集群挂载NAS的当前使用情况?
查看Frontend Storage IO Monitoring (Cluster Level)监控大盘,设置如下选择项后,查看当前集群挂载NAS的使用情况。
client_name:选择eac。
backend_storage:选择nas。
bucket_name:选择对应的文件系统ID。
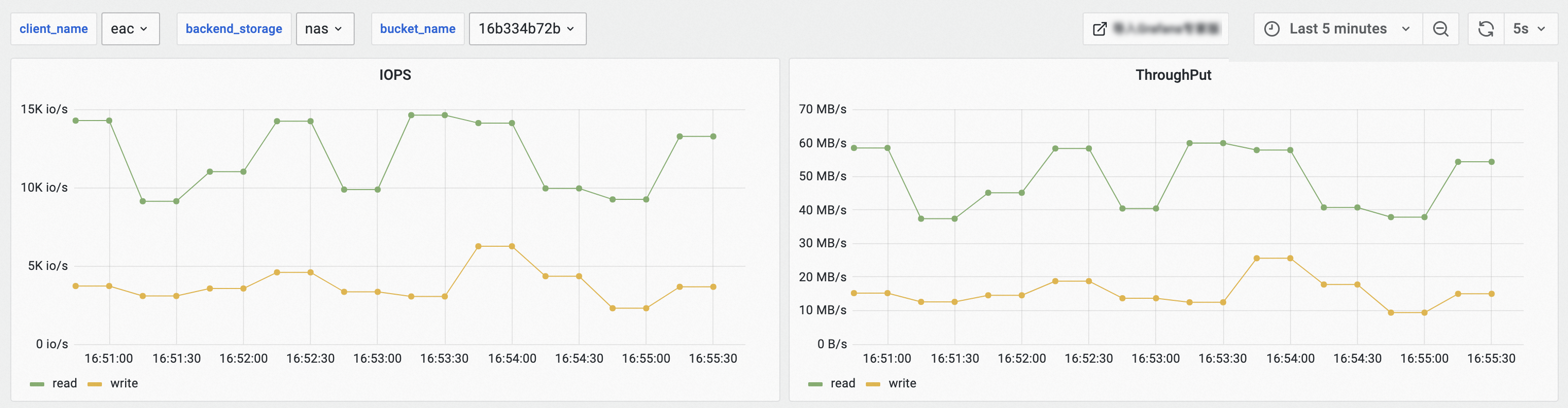
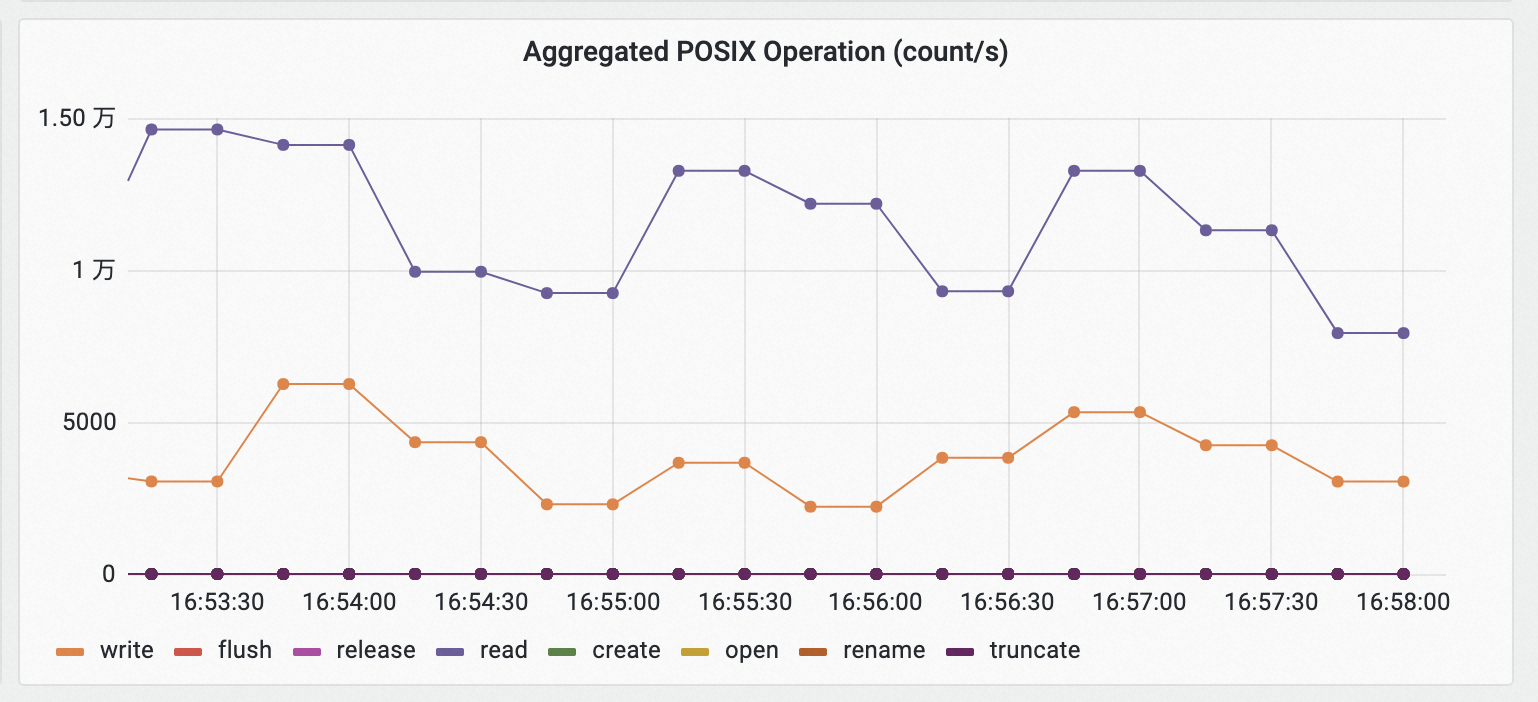
以上示例表明,集群内所有持久化卷的聚合IO情况如下表所示。
IOPS | ThroughPut | POSIX请求 |
13 k/s | 50 MB/s | 14k count/s |
4 k/s | 18 MB/s | 4k count/s |
问题2:定位哪些应用和存储卷的IO操作频繁会导致系统繁忙?
您可以通过以下操作定位当应用Pod的PVC读访问请求高时,可能触发的服务侧限流和不响应问题。
定位热点应用Pod。
查看Container Storage IO Monitoring (Cluster Level)监控大盘,根据TopN_Pod_IOPS(IO/s)和TopN_Pod_Throughput面板的read排序,找到高IO和高吞吐的Pod。
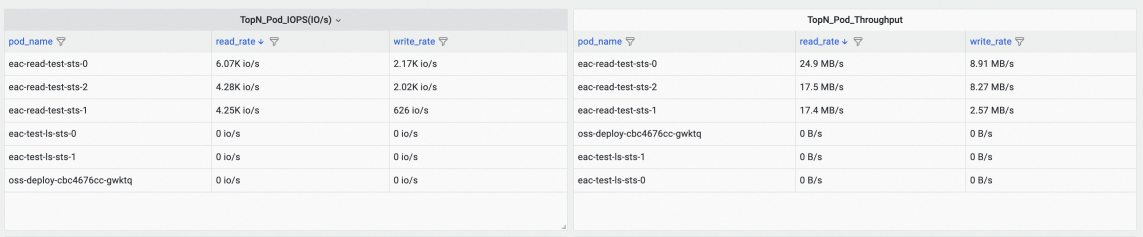
以上示例表明,名称以eac-read-test-sts开头对应的Pod产生了较多的读IO和吞吐,其中eac-read-test-sts-0产生最多的读IO和吞吐。
定位热点存储卷。
查看Container Storage IO Monitoring (Cluster Level)监控大盘,根据TopN_PV_IOPS(IO/s)和TopN_PV_Throughput面板的read排序,找到高IO和高吞吐的PV。
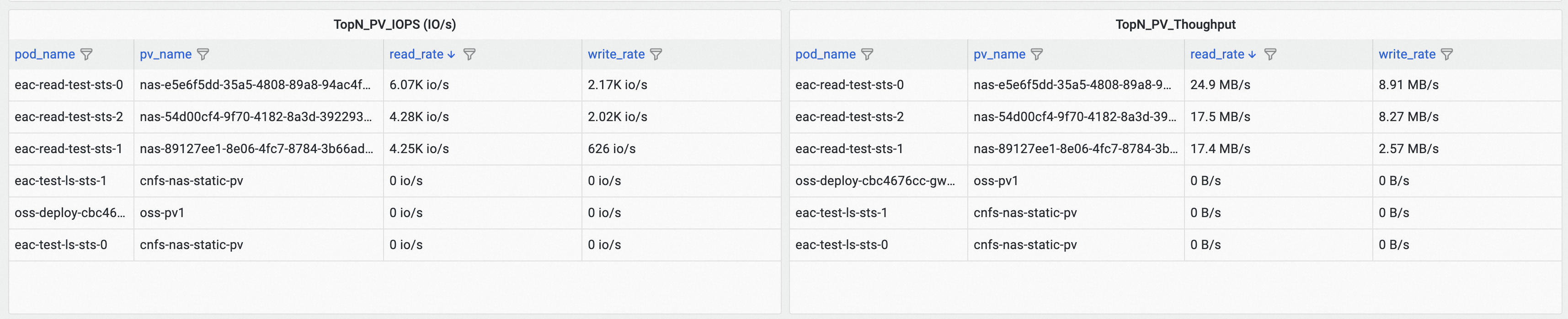
以上示例表明,eac-read-test-sts-0挂载名为nas-e5e6f5dd-35a5-4808-89a8-94ac4fbe6534的PV产生最多的读IO和吞吐。
定位热点POSIX操作。
查看Pod IO Monitoring (Pod Level)监控大盘,选择Pod为eac-read-test-sts-0,然后查看Throughput、IOPS和POSIX Operation(count/s)面板,找出执行POSIX Operation命令过高导致的高吞吐。
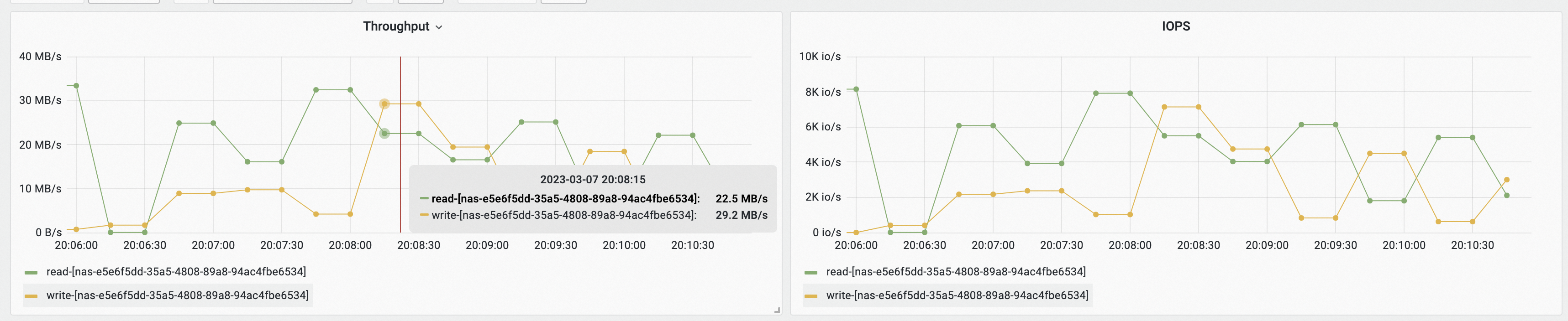
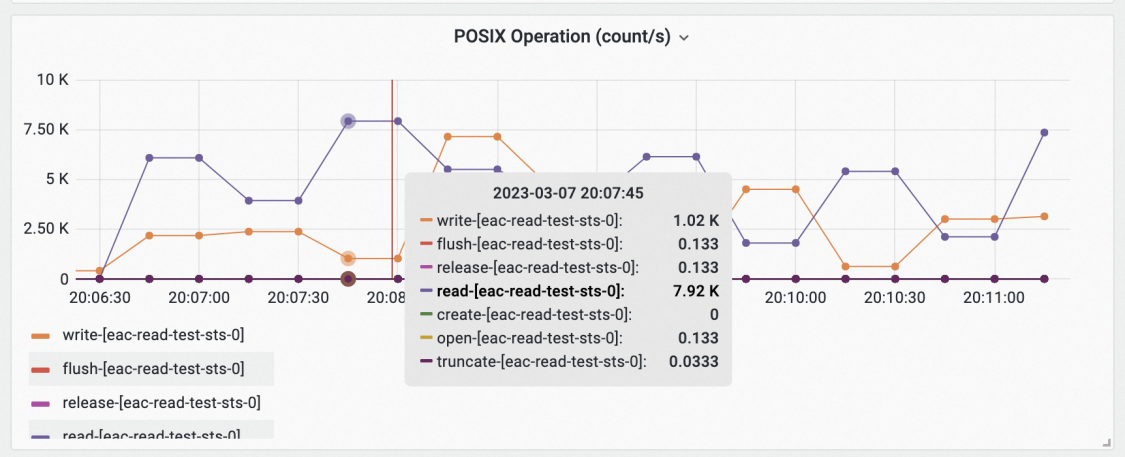
以上示例表明,eac-read-test-sts-0挂载名为nas-e5e6f5dd-35a5-4808-89a8-94ac4fbe6534的PV存储卷的IOPS最高,每秒产生约7920个Read POSIX操作。
根据以上获取的高访问元数据的信息,修改应用。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在容器组页面,单击名称为eac-test-ls-sts的目标StatefulSet,进入应用详情页面,在该页面下获取应用的镜像信息,然后对应用进行修改。
问题3:定位哪些元数据频繁操作导致的系统繁忙?
您可以通过以下操作定位当NAS元数据读访问请求过高时,可能触发的服务侧限流和不响应问题。
定位热点元数据应用。
查看Frontend Storage IO Monitoring (Cluster Level)监控大盘,设置如下选择项后,查看Aggregated POSIX Operation (count/s)面板中readdir请求数。
client_name:选择eac。
backend_storage:选择nas。
bucket_name:选择对应的文件系统ID。
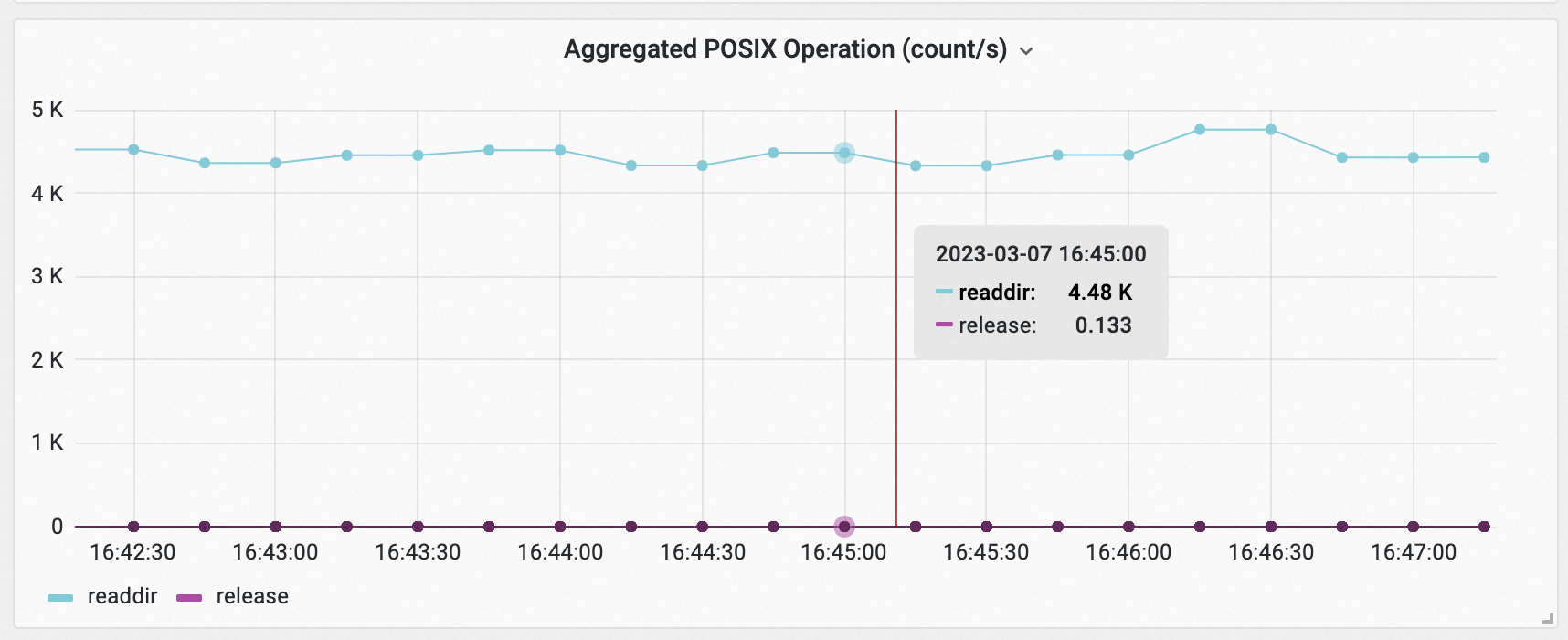
以上示例表明,eac客户端每秒产生4480个的readdir请求。
定位热点元数据存储卷。
查看Container Storage IO Monitoring (Cluster Level)监控大盘,根据TopN_Pod_Meta_Operation和TopN_PV_Meta_Operation面板的readdir的rate指标进行倒序排序,查看访问元数据过于频繁的PV和Pod。
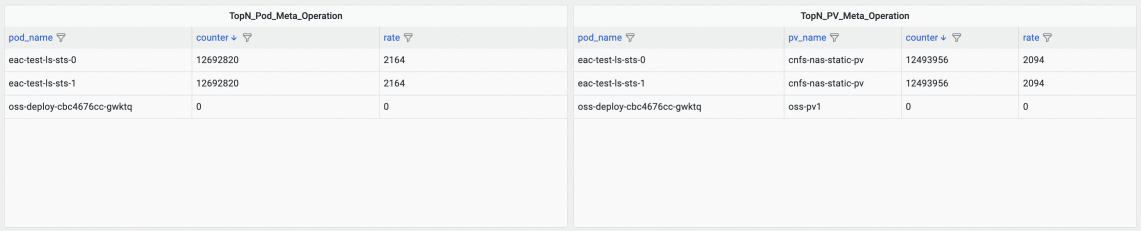
以上示例表明,以eac-test-ls-sts开头的Pod,挂载名为cnfs-eac-static-pv的PV产生最多遍历文件的操作。
定位热点应用的热点操作。
查看Pod IO Monitoring (Pod Level)监控大盘,分别选择Pod为eac-test-ls-sts-0和eac-test-ls-sts-1,查看POSIX Operation (count/s)面板中Pod的IO情况。
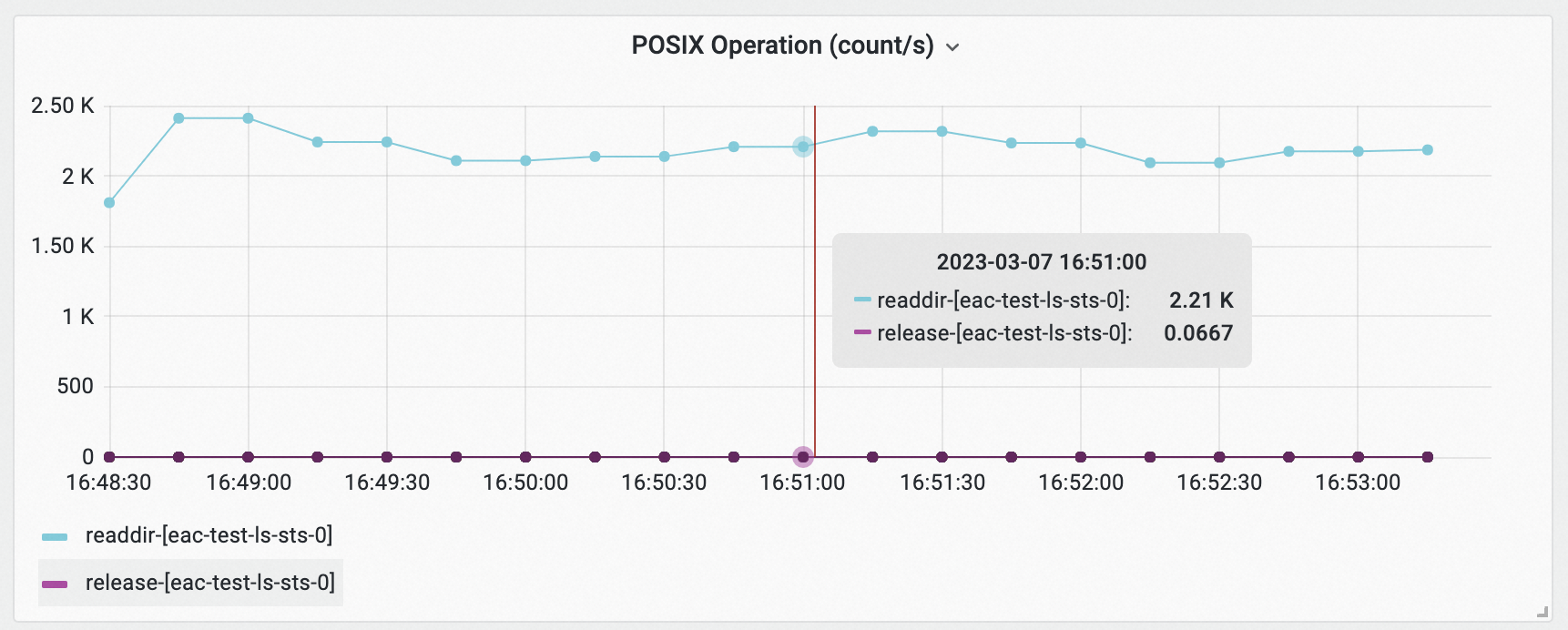
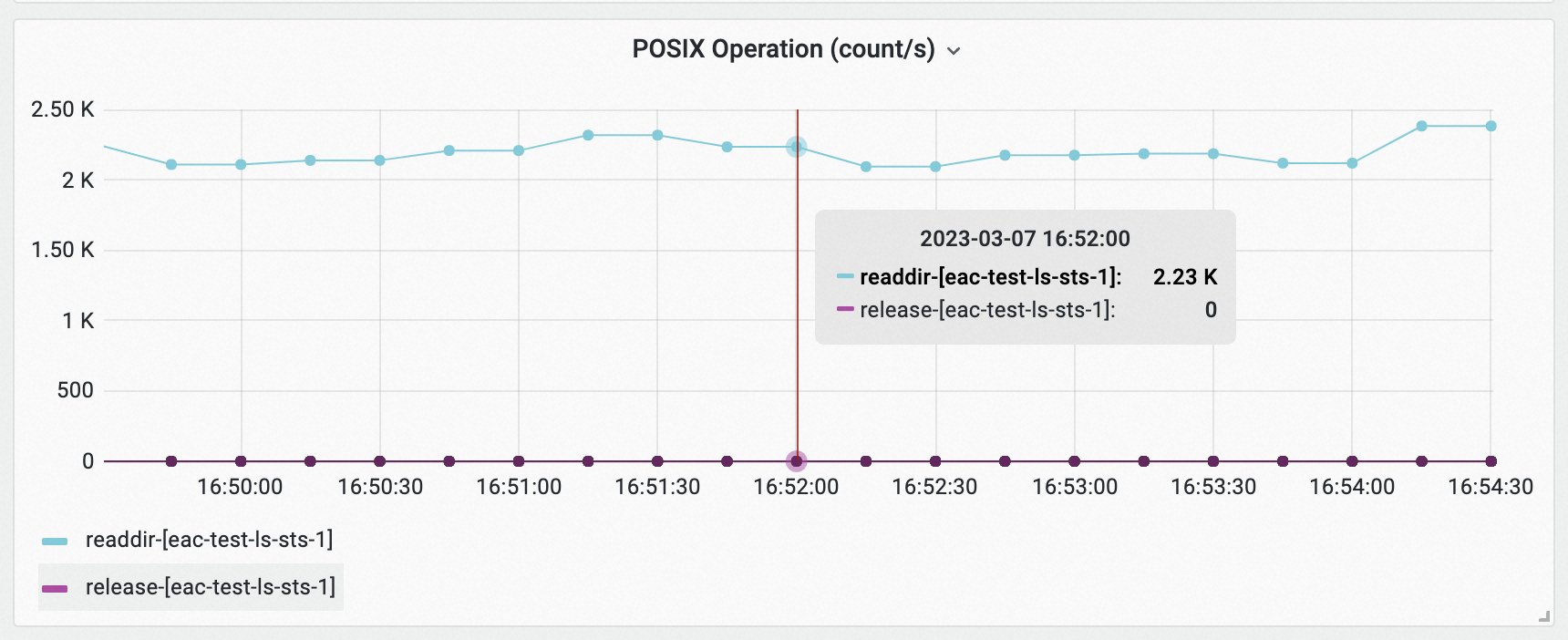
根据以上获取的高访问元数据的信息,修改应用。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在容器组页面,单击名称为eac-test-ls-sts的目标StatefulSet,进入应用详情页面,在该页面下获取应用的镜像信息,然后对应用进行修改。
相关文档
- 本页导读 (1)