GROUP BY子句通常与聚合函数一起使用,用来对查询结果中的数据行进行分组。每个分组都基于一列或多列的值。通过这种方式,可以为每个不同的组合生成一个汇总行,从而帮助用户更有效地分析数据。此外,GROUP BY子句还可以搭配ROLLUP、CUBE和GROUPING SETS子句,以扩展其分组功能,提供更多样化的数据分析选项。
基本语法
GROUP BY
对分析结果进行分组。
SELECT
key1,
...
aggregate_function
GROUP BY
key,...参数说明如下所示:
key1:是您希望根据其值来分组的列,支持按照日志字段名称或聚合函数计算结果列进行分组。GROUP BY子句支持单列或多列。aggregate_function:是应用在每个分组上的聚合函数,如count、min、max、avg和sum等。
GROUP BY ROLLUP
GROUP BY ROLLUP子句按照汇总分组,支持为每个分组返回一个小计,为所有分组返回一个总计。例如GROUP BY ROLLUP (a, b)的结果集为(a, b)、(a, null)和 (null, null)。
SELECT
key1,
...
aggregate_function
GROUP BY ROLLUP (key1,...)参数说明如下所示:
key1:是您希望根据其值来分组的列,支持按照日志字段名称或聚合函数计算结果列进行分组。GROUP BY子句支持单列或多列。aggregate_function:是应用在每个分组上的聚合函数,如count、min、max、avg和sum等。
GROUP BY CUBE
GROUP BY CUBE子句按照所有可能的列组合进行分组。例如GROUP BY CUBE (a, b)的结果集为(a, b)、(null, b)、(a, null) 和(null, null) 。
SELECT
key1,
...
aggregate_function
GROUP BY CUBE (key1,...)参数说明如下所示:
key1:是您希望根据其值来分组的列,支持按照日志字段名称或聚合函数计算结果列进行分组。GROUP BY子句支持单列或多列。aggregate_function:是应用在每个分组上的聚合函数,如count、min、max、avg和sum等。
GROUP BY GROUPING SETS
GROUP BY GROUPING SETS子句按照列依次进行分组。例如GROUP BY GROUPING SETS (a, b)的结果集为(a, null)和(null, b)。
SELECT
key1,
...
aggregate_function
GROUP BY GROUPING SETS (key1,...)参数说明如下所示:
key1:是您希望根据其值来分组的列,支持按照日志字段名称或聚合函数计算结果列进行分组。GROUP BY子句支持单列或多列。aggregate_function:是应用在每个分组上的聚合函数,如count、min、max、avg和sum等。
示例
在SQL语句中,如果使用了GROUP BY子句,则在SELECT语句中只能选择以下两类内容:
GROUP BY子句中指定的列;对任意列进行聚合计算的结果(如
COUNT()、SUM()等)。
直接选择非GROUP BY列是不允许的,因为这些列的值在分组后可能不唯一,无法明确其含义。例如,以下语句是非法的:
* | SELECT status, request_time, COUNT(*) AS PV GROUP BY status原因是request_time并未包含在GROUP BY子句中,且未对其进行聚合处理。
正确的写法可以是:
* | SELECT status, arbitrary(request_time), COUNT(*) AS PV GROUP BY status在这里,arbitrary(request_time)是对request_time进行聚合处理的一种方式,表示从每个分组中任意选取一个request_time值。这样既符合 SQL 的语法规则,又能满足查询需求。
示例1:统计不同状态码对应的请求次数。
查询和分析语句
* | SELECT status, count(*) AS PV GROUP BY status查询和分析结果
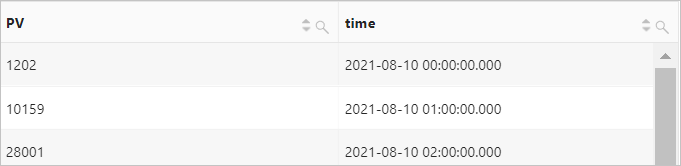
示例2:按照每小时的时间粒度计算网站访问PV。
查询和分析语句
__time__字段为日志服务中的保留字段,表示时间列。time为date_trunc('hour', __time__)的别名。关于date_trunc函数的更多信息,请参见date_trunc函数。* | SELECT count(*) AS PV, date_trunc('hour', __time__) AS time GROUP BY time ORDER BY time LIMIT 1000查询和分析结果
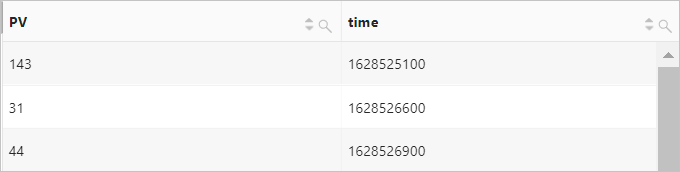
示例3:按照每5分钟的时间粒度计算PV。
查询和分析语句
因为
date_trunc函数只能按照固定时间间隔统计。如果您需要按照自定义的时间进行统计分析,请按照数学取模方法进行分组。例如%300表示按照5分钟的时间粒度进行取模对齐。* | SELECT count(*) AS PV, __time__-__time__ % 300 AS time GROUP BY time LIMIT 1000查询和分析结果
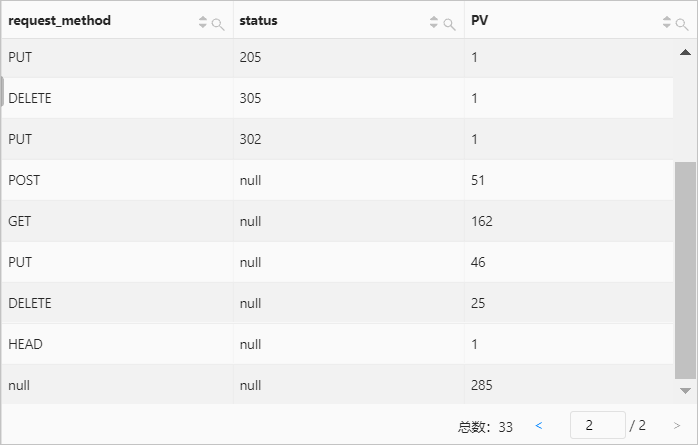
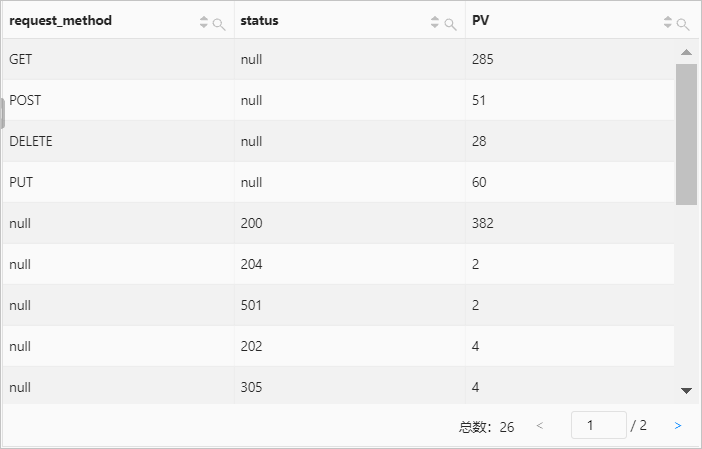
示例4:根据请求方法和请求状态分组,先计算各个请求方法对应的访问数据,再计算各个请求状态对应的访问数量。
查询和分析语句
* | SELECT request_method, status, count(*) AS PV GROUP BY GROUPING SETS (request_method, status)查询和分析结果
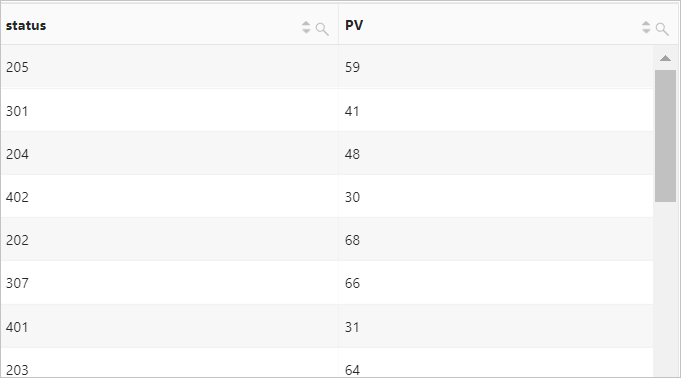
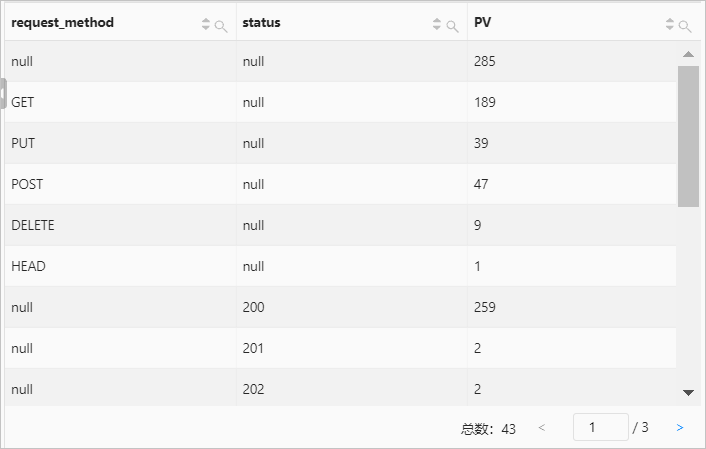
示例5:根据请求方法和请求状态分组,分组集包括
(null, null)、(request_method, null)、(null, status)和(request_method, status),计算以上各个分组的访问数量。查询和分析语句
* | SELECT request_method, status, count(*) AS PV GROUP BY CUBE (request_method, status)查询和分析结果
示例6:根据请求方法和请求状态分组,分组集包括
(request_method, status)、(request_method, null)和(null, null),计算以上各个分组的访问数量。查询和分析语句
* | SELECT request_method, status, count(*) AS PV GROUP BY ROLLUP (request_method, status)查询和分析结果