PolarDB-X 1.0计算资源只读实例是对PolarDB-X 1.0计算资源主实例的一种扩展补充,兼容主实例的SQL查询语法。
背景信息
PolarDB-X 1.0计算资源只读实例与主实例可以共享同一份数据,通过物理资源隔离的方式,缓解主实例的负载压力,降低业务架构的链路复杂度,无需进行额外的数据同步操作,节省运维及预算成本。可直接在RDS只读实例或RDS主实例上进行复杂数据查询分析。提供多种实例类型,可抵御超高并发的访问压力、减少复杂查询的响应时间。
注意事项
- 只读实例与主实例必须属于同一个地域,但是可以在不同的可用区。
- 只读实例无法单独存在,必须隶属于某个主实例。若您在主实例上创建了数据库,该数据库也会被复制到只读实例上。同理,若您在主实例上删除数据库时,只读实例上对应的数据库也会被删除。
- 目前,PolarDB-X 1.0计算资源只读实例仅支持专有网络VPC实例,只读实例上的RDS实例必须是VPC实例。
使用限制
- 不支持将数据迁移至只读实例。
- 不支持在只读实例上创建或删除数据库。
- 不支持克隆只读实例。
- 只读实例不支持使用数据变更DML语句。
只读实例类型
PolarDB-X 1.0计算资源只读实例为并发型只读实例,拓扑结构如下:
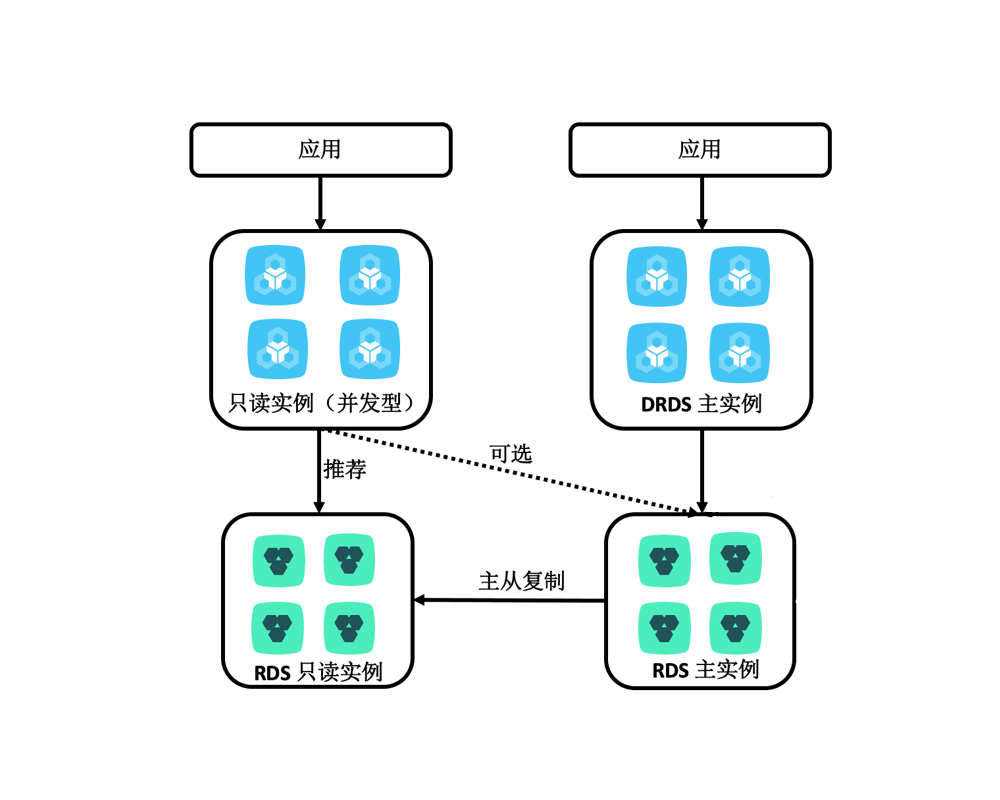
并发型只读实例,通过物理资源隔离的方式,可抵御超高流量的并发查询,以确保在线业务链路的稳定性。并发型只读实例主要应用于如下业务场景:
- 存在高并发、大流量简单查询的业务场景。
- 离线抽取数据的业务场景。