为避免过期版本集群存在的安全和稳定性风险,同时保证您业务的连贯性,容器服务ACK采用原地升级的方式升级ACK集群版本。您可以通过控制台升级集群的Kubernetes版本,也可以独立升级控制面和节点池,灵活控制升级节奏。本文介绍集群升级前后的注意事项、升级流程、操作步骤等。
为什么需要升级
ACK保证Kubernetes最新3个次要版本的稳定运行。例如,支持Kubernetes 1.24、1.26、1.28 3个双数版本时,1.22版本不再支持创建,过期补丁版本也不再支持创建。
主动升级集群有以下好处:
降低安全和稳定性风险:随着Kubernetes版本迭代,会不断优化及修复发现的安全及稳定性漏洞,长久使用过期版本集群会给业务带来安全和稳定性风险。
享受更好的维护支持:对于过期Kubernetes版本,ACK不再提供安全补丁和问题修复,也无法保证过期版本的技术支持质量。使用新版本能够让您享受更好的技术支持和答疑服务。
使用新版本的新功能:随着社区Kubernetes版本的演进,新版本包含新的功能和改进,ACK也将适配新版本,为您带来更好的开发和运维体验。
此外,基于安全原因,ACK保留强制升级过期版本集群的权利(在集群版本过期后的某个时间,强制升级集群到支持中的最早版本),建议您参照下文提前主动升级集群。
升级集群时,容器服务ACK会对您的集群进行前置检查,但无法保证检查出所有不兼容的功能配置和API。根据安全责任共担模型,请您通过帮助文档、控制台信息、站内信等渠道关注版本发布情况,并在集群升级时提前了解相应版本的升级注意事项。
更多关于Kubernetes版本支持信息,请参见Kubernetes版本概览及机制。
注意事项(重要)
版本说明
ACK集群的Kubernetes版本只能按照支持的版本依次升级。例如,Kubernetes版本为v1.24的ACK集群升级到v1.28时,需进行两次集群升级,即先升级到v1.26版本,再升级到v1.28版本。
您可以登录容器服务管理控制台,在集群页面的版本列查看集群的Kubernetes版本。确定待升级版本后,参见下方链接了解待升级版本的版本解读、废弃资源API、升级注意事项等,避免因高版本的功能变更导致业务功能不兼容,继而影响集群正常运行。
如果您的HELM Chart YAML文件中使用了废弃资源,请及时修改。更多信息,请参见上方版本说明和废弃API说明。
相关功能及自定义配置说明
如果您的集群中使用了如下相关功能,请仔细阅读以下说明及解决方案。
配置项 | 注意事项 | 推荐解决方案 |
Flexvolume存储 | 集群升级过程中,老版本的Flexvolume(v1.11.2.5及以前)挂载的OSS存储卷会重新挂载。 | 若您的集群使用OSS存储卷,请在集群升级后重建相应的Pod。 同时,由于Flexvolume存储插件已经弃用,建议您将FlexVolume迁移至CSI插件。具体操作,请参见迁移Flexvolume至CSI迁移Flexvolume至CSI。 |
节点自动伸缩 |
|
|
节点资源预留 | 升级至Kubernetes v1.18后,ACK会默认配置节点资源预留。如果集群未配置资源预留且节点水位较高,升级后存在Pod驱逐后无法被快速调度的风险。 | 为节点预留部分资源,推荐CPU使用率不超过50%,内存使用率不超过70%。更多信息,请参见节点资源预留策略。 |
Loadbalancer配置 | 集群外部访问集群时,需要通过SLB来访问。但当SLB设置 | 检查是否完成对应配置,避免LoadBalancer暴露的SLB地址访问不通的风险。如有相关问题,请参见Kubernetes集群中访问LoadBalancer暴露的SLB地址不通Kubernetes集群中访问LoadBalancer暴露出去的SLB地址不通。 |
API Server | 集群升级过程中,ACK竭力保障控制面的平滑升级,集群上的应用不会中断,但升级过程中可能会出现短暂的API Server中断。如果您的应用强依赖于API Server,例如需要对资源进行List-Watch,API Server重启会导致Watch 中断,需要您自行保证在中断时自动重试。 | 如果您的应用不访问API Server,将不会受到升级影响;如果需要访问API Server,则需要具备失败重试的能力。 |
启动探针(Startup Probe) | 如果集群中的Pod配置了启动探针,Pod会在kubelet重启后出现短暂的NotReady现象。 | 建议Pod采用多副本模式,将Pod分散到不同的节点上,以确保在某个节点重启期间仍有足够的可用Pod。 |
kubectl | 集群升级后,请同步升级您本地的kubectl版本。 如果未及时升级,在使用本地kubectl的过程中可能会因为与集群API Server版本不同,发生类似 | 安装或升级kubectl。具体操作,请参见安装kubectl。 |
如果您对集群曾有自定义配置,请仔细阅读以下说明。
配置项 | 说明 |
网络 | 集群升级需要使用yum下载升级所需的软件包。如果您的集群曾自行修改节点的网络配置或者使用了自定义的操作系统镜像,需确保节点yum能正常使用。您可以执行 |
操作系统镜像 | 自定义操作系统镜像非容器服务官方严格验证。ACK无法完全保证升级成功。 |
其他 | 如果您对集群有过配置更改,例如打开了SWAP分区、曾通过黑屏操作修改kubelet配置等,集群升级过程有可能失败,或自定义配置有可能丢失。 |
升级流程、方式及所需时间
升级流程
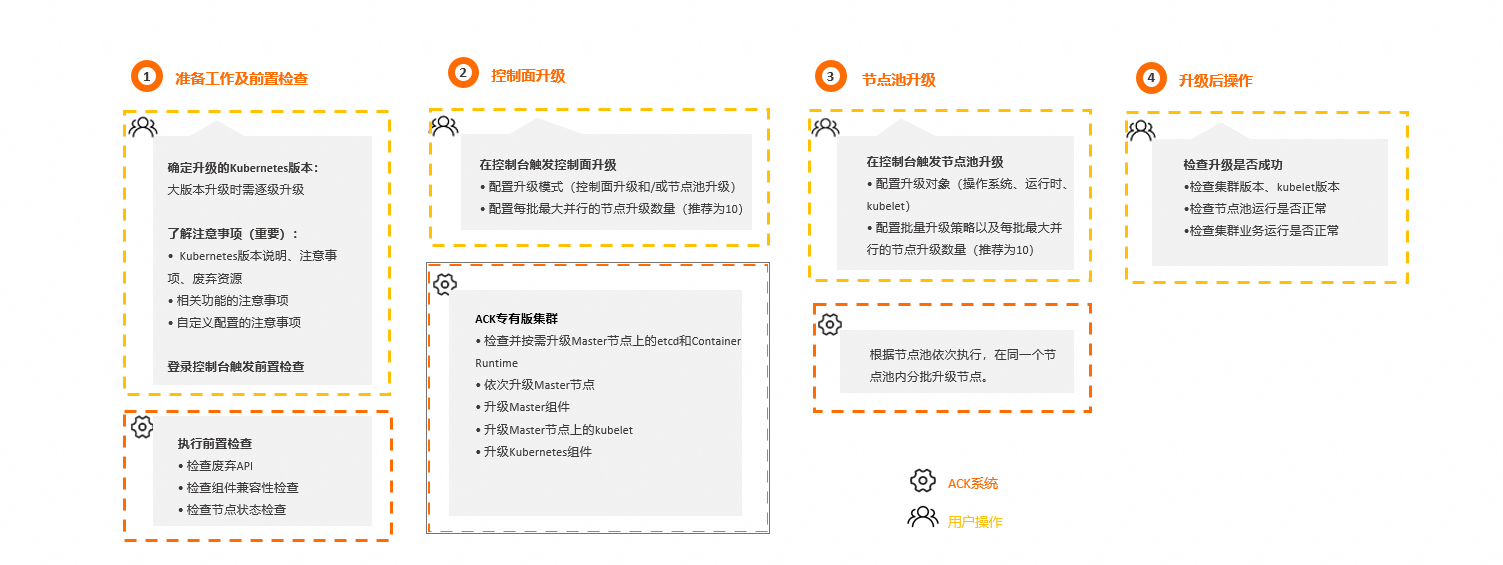
准备工作及前置检查:
注意事项:确定您待升级集群的Kubernetes版本后,仔细阅读待升级目标版本的版本升级注意事项,避免升级时潜在的功能不兼容问题。更多信息,请参见上文的版本说明。
前置检查:执行前置检查,排查暴露影响升级的风险项。如有检查异常项,请按控制台提示或参见集群检查项及修复方案修复风险项。
集群升级:前置检查通过后,可开始集群升级,包括控制面和节点池的升级。有关升级流程的更多信息,请参见参考信息:控制面及节点池升级流程。ACK提供以下两种升级模式。
同时升级:一起完成控制面和节点池升级。
独立升级:先独立升级控制面,再独立升级节点池。
控制面升级包括对核心组件kube-apiserver的升级,节点池升级包括对kubelet及其依赖组件的升级。为保证集群稳定性和可靠性,需保证kube-apiserver不低于kubelet两个版本,故需先完成控制面独立升级,再在业务低峰期完成节点池升级。
集群升级后:核验集群、kubelet等版本,检查节点池运行是否正常,以及检查集群业务是否运行正常。
升级方式
控制面:控制面升级将升级控制面组件,包括kube-apiserver、kube-controller-manager、cloud-controller-manager、kube-scheduler等。ACK托管集群、ACK Serverless集群将直接升级托管控制面组件;ACK专有集群采用原地升级的方式,以更大程度地保证您业务的连贯性,减少数据迁移和配置调整的风险。
节点池:节点池升级包括kubelet、OS镜像和容器运行时的升级。如您需要更换操作系统,或运行时需从Docker升级为containerd,系统会通过替换系统盘(替盘升级)的方式完成升级,即更换磁盘的同时进行操作系统或应用程序的升级。请提前做好系统盘的备份工作。其他情况下,保持使用原地升级方式。更多信息,请参见升级节点池。
升级所需时间
ACK托管集群、ACK Serverless集群控制面升级时间约为5分钟;ACK专有集群的Master节点需逐个、串行升级,每个Master节点升级时间约为8分钟。节点池升级时内部节点分批升级,每批升级时间约为5分钟。
操作步骤
同时升级控制面与节点池
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,选择目标集群,并在目标集群右侧操作列,选择。
在集群升级页面的操作对象区域,选择可升级的集群版本,选择升级模式为控制面和所有节点池,并在批量升级策略区域,设置每批次的最大并行数,然后单击前置检查。
检查完成后,单击查看详情,查看检查报告。
检查结果为正常时,您可以继续进行集群升级操作。
检查结果为异常时,请单击待处理页签按照页面提示进行修复。详细信息,请参见集群检查项及修复方案。
前置检查通过后,单击开始升级。
升级过程中,请勿添加或删除节点(如需操作,请先取消升级)。您可以在集群升级页面下方的事件轮转区域查看升级进程,还可按需进行以下操作。
暂停与继续升级:升级过程中,如需在某个阶段暂停升级,可单击暂停。如需继续集群升级进程,单击继续。
集群暂停状态为集群升级的中间状态,请尽快完成升级,并在此期间请勿对集群进行任何操作。处于暂停状态的集群将7日后关闭升级过程,同时清理升级相关的事件和日志信息。
取消升级:如需取消集群升级,可在暂停升级后单击取消,然后在弹出的对话框单击确定。取消升级后,当前批次已经开始升级的节点将完成升级且无法回滚,未开始升级的节点不会升级。
说明如果集群升级过程中发生错误,系统将暂停集群升级进程。具体失败原因会展示在页面下方详情中,您可根据提示进行修复。
集群升级过程中,除非发生错误,否则请勿修改kube-upgrade命名空间下的相关资源。
升级完成后,您可以在集群列表查看集群版本,确认管控组件升级是否成功,并在集群信息页面的左侧导航栏单击节点管理 > 节点,查看kubelet版本,确认节点升级是否成功。
仅升级控制面
使用限制
仅v1.18及以上版本的集群支持升级ACK集群时仅升级控制面。
操作步骤
节点池升级前,您应先完成控制面升级。
登录容器服务管理控制台,在左侧导航栏选择集群。
在集群列表页面,选择目标集群,并在目标集群右侧操作列,选择。
在集群升级页面的操作对象区域,选择可升级的集群版本,选择升级模式为仅控制面,然后单击前置检查。
检查完成后,单击查看详情,查看检查报告。
当检查报告中检查结果为正常时,表示升级检查成功,您可以进行集群升级操作。
当检查报告中检查结果为异常时,不影响当前集群的运行及集群状态。请单击待处理页签按照页面提示进行修复。典型修复方案,请参见集群检查项及修复方案。
说明Kubernetes 1.20及以后版本的集群升级前检查时,会检查当前版本是否使用了废弃API,检查结果不会影响升级流程,仅作为提示信息。详细内容,请参见废弃API说明。
前置检查通过后,单击开始升级。
升级过程中,您可以在集群升级页面下方查看升级进程。升级完成后,您可以在集群列表查看集群版本,确认管控组件升级是否成功。
后续操作:升级节点池
控制面升级完成后,新扩容节点的版本遵循控制面的版本。建议您在业务低峰期尽快完成存量节点的升级,并在升级完成后查看kubelet版本,确认升级是否成功。具体操作,请参见升级节点池。
集群升级常见问题
参考信息:控制面及节点池升级流程
控制面升级流程
ACK将按照以下流程升级您集群的控制面。具体策略如下。
ACK托管集群、ACK Serverless集群
升级控制面和托管组件,包括kube-apiserver、 kube-controller-manager和kube-scheduler等。
升级Kubernetes组件,例如kube-proxy等。
ACK专有集群
当ACK检测到您的集群需要进一步升级etcd和Container Runtime时,将依次升级Master节点上的etcd和Container Runtime。
依次选择Master节点,一次只升级一个Master节点,并展示当前正在升级的Master节点的编号。
升级Master组件,包括kube-apiserver、 kube-controller-manager和kube-scheduler。
升级Master节点上的kubelet。
在所有Master节点升级完成后,升级Kubernetes组件,例如kube-proxy等。
节点池升级流程
ACK将集群中的节点按照分批策略执行分批升级。具体策略如下。
根据节点池依次执行,同一时间只有一个节点池进行升级。
在同一个节点池内进行分批升级。第一批升级的节点数为1,后续的批次以2的幂数进行增长。如果暂停后重新恢复升级,依然遵循该分批策略。您可以在节点池升级页面配置每批升级节点的最大数量,推荐设置为10。具体操作,请参见升级节点池。
相关文档
v1.24不再支持将Docker作为内置容器运行时,升级到v1.24及更高版本前,请将节点容器运行时迁移到containerd。具体操作,请参见将节点容器运行时从Docker迁移到containerd
- 本页导读 (1)