在社交领域之中,有很多数据的存储,使用数据的形态也多种多态。目前主流的社交都带推荐模块会把新闻/消息/短文推动给适合的用户。本文简述社交类的基本架构。
社交领域的基本架构及流程流
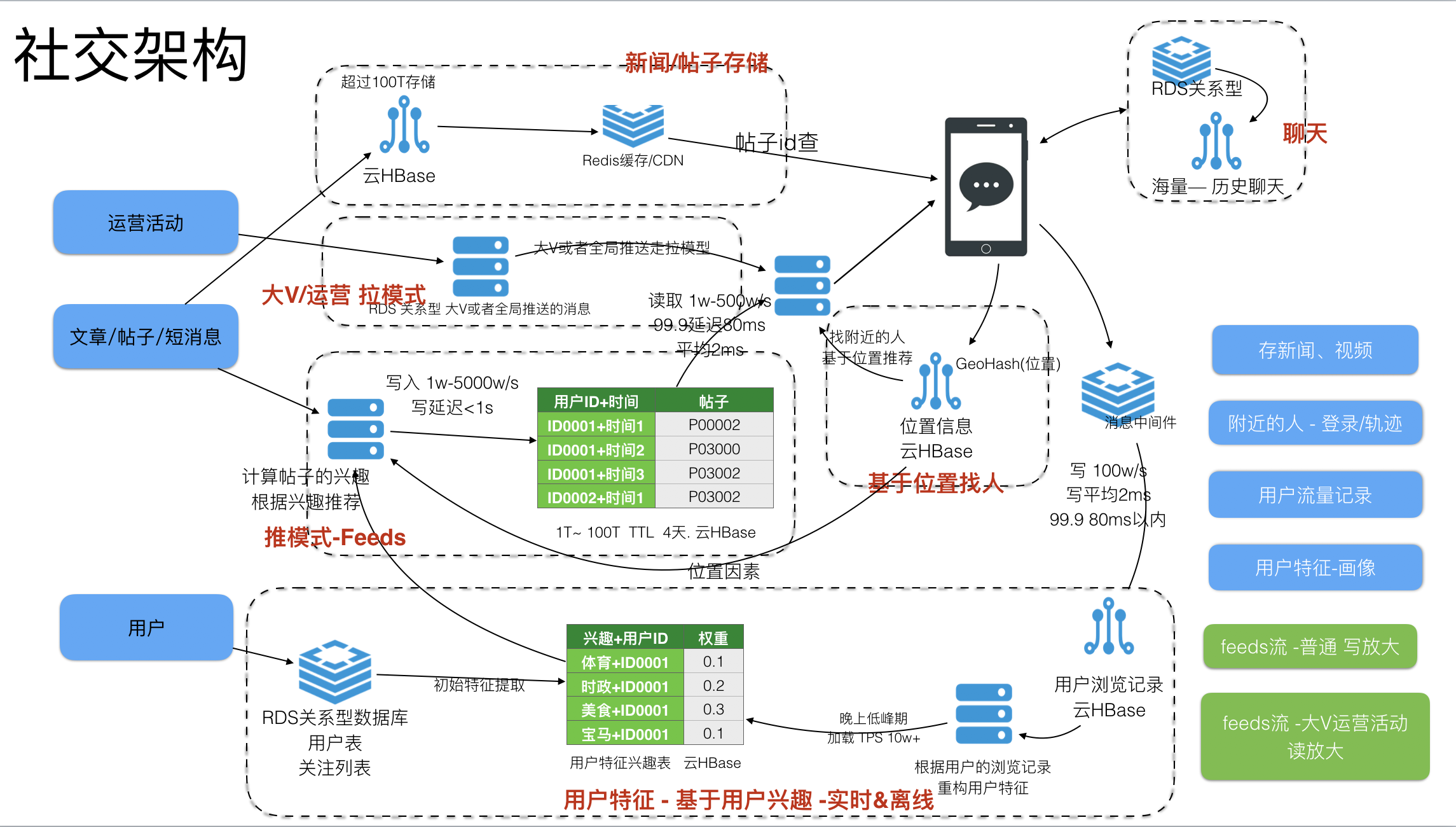
以上是社交领域的基本架构,分为以下基本部分:
客户登录后发帖和看帖
客户登录后,系统会记录位置信息,位置信息通过GeoHash处理后,可以存在HBase之中。
客户发帖子时可以将帖子写到HBase之中,发完之后,也可以立即写到推荐之中,可以看到自己发的帖子。
客户浏览帖子,系统记录客户浏览过的帖子的信息,把浏览记录写到HBase之中,以备后续分析反馈给用户特性-用户画像模块。
用户特性-用户画像
用户注册后,会选择感兴趣的特征,此块数据会形成最初的用户特性。
用户浏览信息后,会有浏览的历史记录,会写到HBase之中。
晚上会启动spark或者用户写的code分析用户的历史记录,修正用户的标签画像。
最终会形成一张用户特性-用户画像
推荐及Feeds流
一般有两个模型,分表为推模型和拉模型,最主要是以帖子为维度还是以查询的人为维度。推模型是写放大的,拉模型是读放大的。HBase基于LSM,比较适合推模型。
当帖子或者文章产生后,会写一份到HBase存储上。
再同时会计算,帖子的属性,分析帖子的归类,提取特征值。
根据帖子的特征值与用户特性-用户画像,把匹配的用户写入到推送的表之中。此块根据不同的业务,可能涉及的逻辑比较复杂,比如加入位置的因素、权重、好友关注的列表、把不活跃的客户剔除。
会形成一张帖子推荐表,数据量比较大,大约1T到100T左右。会有过期时间,一般在3天-4天左右。
对于大V或者写运营普发的信息,可以采取拉模式,可以显著减少写放大。一般实际的业务是推模型与拉模型混合使用
帖子新闻查询
用户打开APP,可以查询最近推荐的信息。
对于大V或者运营推送的信息,可以单独链路查询。
查询帖子推荐表,查询出所属的帖子ID后,再查询实际的帖子信息,这部分一般在Redis或者CDN之中有缓存,没有命中,可以查询到业务库HBase之中。
基于位置的推荐人
可以基于存的客户位置的信息,推荐兴趣相投的人。
基于地理信息,查询边上所有的客户,再查询画像表,找到兴趣相投的人,再推荐。