机器学习SQL提供以SQL的方式训练和预测机器学习模型。利用机器学习SQL,您可以迅速对DMS中已有的数据库数据进行更深入的分析和建模,提升对数据的分析效率,盘活对历史数据的利用率,最终达到以数据驱动产生的目的。
产品概述
-
目前机器学习SQL支持的数据库类型有:
- MySQL
-
目前机器学习SQL支持的机器学习算法有:
- Kmeans 聚类
- Linear regression 回归分析
- Logistic regression 二元分类
- 决策树二元分类
- 随机森林二元分类
机器学习SQL旨在帮助企业降低在机器学习领域的成本。一是人员成本,资深的机器学习算法科学家都比较稀缺,用人成本较高。二是算法科学家与业务人员的沟通成本,懂业务的人员未必能掌握机器学习的算法,但只需要掌握SQL,就能尝试解决部分机器学习场景的问题。
“机器学习SQL”优势
- SQL作为数据访问的常用方式,大多数的工程师都能掌握,降低学习其他语言的成本。
- 减少数据的导出步骤。一般情况下,遇到机器学习的问题,都需要导出数据到专业的平台或工具上才能解决,现在只需在DMS一个环境内就足够了。
- 提升解决问题/做出决策的效率。
入口
“机器学习SQL”第一版在个人版的DMS中上线,你可以通过导航栏的“SQL操作”中看到它: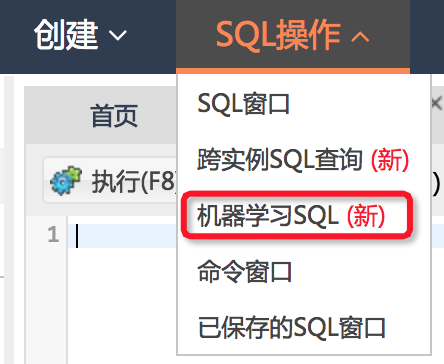
入门课程
- 界面介绍
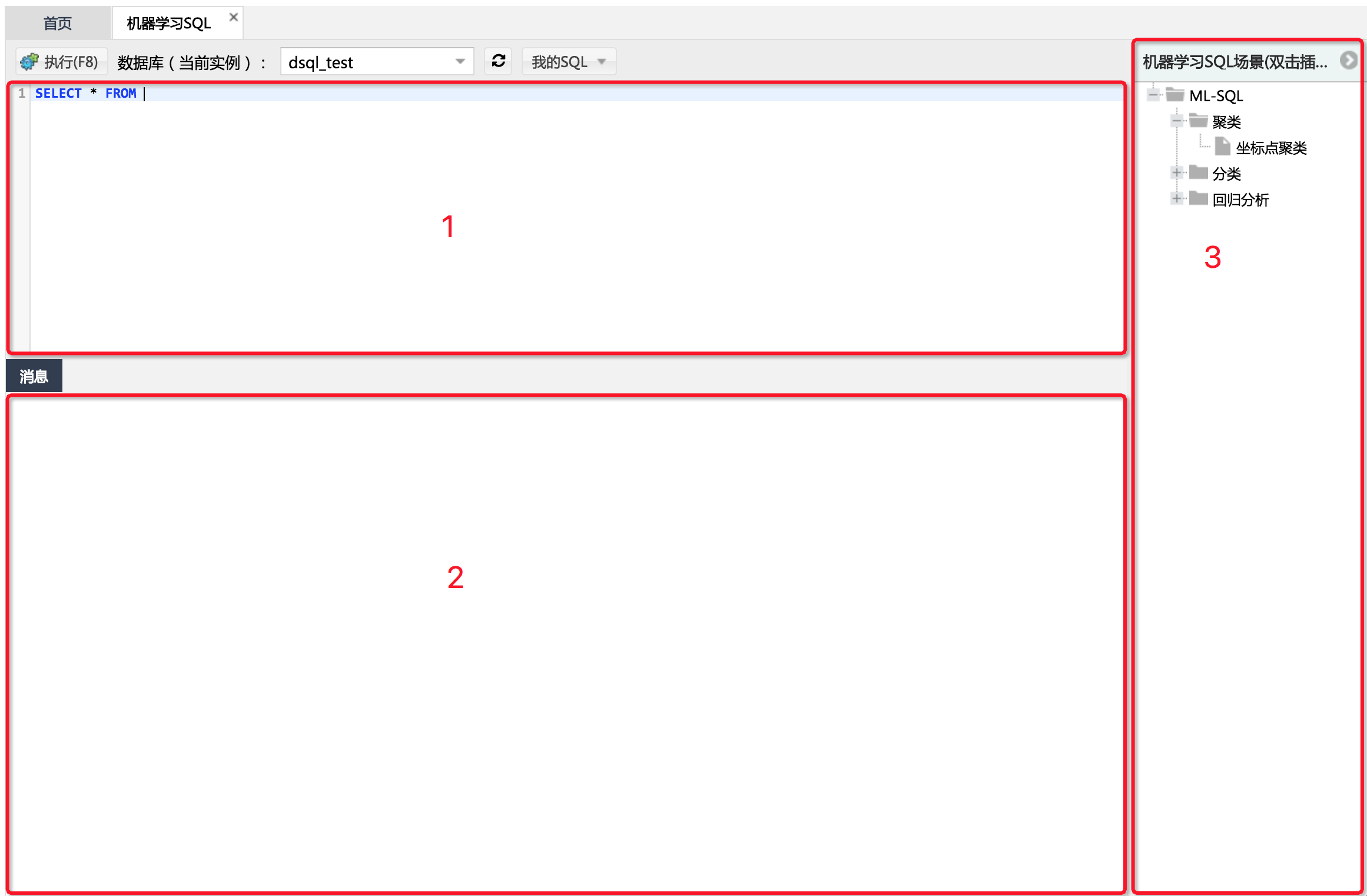
- 1:SQL编辑区。同“SQL窗口”,在这里编辑你想要执行的SQL。
- 2:执行结果区。同“SQL窗口”,在这里可以看到每一句SQL执行的结果。
- 3:机器学习场景区。为了帮助新人快速了解机器学习能解决怎样的场景问题(要记得学会举一反三哦),在这里会不定时丰富场景供用户浏览。
- 场景介绍
- 按照算法类别进行分类,单击“+”号展开场景,单击“-”号收回。
- 每种算法类别会不定时更新多种场景,双击场景的item标签即可粘贴进SQL编辑区。(如果SQL编辑区是空白的,整个场景粘贴进去后,即可按“执行”或“F8”运行起来看看效果)
使用说明
- SQL操作与SQL语法同“跨实SQL查询”窗口,不过在“机器学习SQL”窗口使用本实例就足够了。
- 如果第一次访问“机器学习SQL”窗口,会自动帮您创建一个本实例的dblink,名字前缀为
machine_learning_default_,可以在“跨实例SQL查询”窗口编辑维护。 - 除以上两点外,“机器学习SQL”窗口主要注意支持的机器学习功能即可——机器学习功能的表现形式为机器学习函数。函数的输入与输出定义、功能说明的内容,请参考“算法函数说明”一节。
- 右侧的机器学习场景会不定时丰富,您可以在此参考函数是如何使用的。
算法函数说明
| 算法 | Functions | 具体说明 |
|---|---|---|
| 聚类 | auto_cluster_learn、auto_cluster_predict | 自动智能选取最好聚类算法(Plan) |
| Kmeans | kmeans_learn、kmeans_predict | [Kmeans] |
| 回归 | auto_regression_learn、auto_regression_predict | 自动智能选取最好的回归算法(Plan) |
| Linear Regression | regression_learn、regression_predict | [Linear Regression] |
| 0/1分类 | auto_binary_classify_learn、auto_binary_classify_predict | 自动智能选取最好的二元分类算法(Plan) |
| Logistic Regression | logistic_learn、logistic_predict | [Logistic Regression] |
| Decision Tree(classify) | cla_decision_tree_learn、cla_decision_tree_predict | [Decision Tree] |
| Random Forest | random_forest_learn、random_forest_predict | [Random Forest] |
Model Functions
model_explain
- 格式:
string model_explain(model) - 输入:
名称 类型 说明 model VARBINARY 模型 - 输出:model的说明、训练结果、效果等。
算法细节
Kmeans
介绍:无监督学习的聚类算法
函数:kmeans_learn
- 格式:
model kmeans_learn (json | string | array feature, int k) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray。 K int 聚类个数 - 输出:
名称 类型 说明 model VARBINARY 模型输出
函数:kmeans_predict
- 格式:
int kmeans_predict(model, json | string | array feature) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray。 model VARBINARY 模型 - 输出:
名称 类型 说明 result int 所属的类别
Linear Regression
介绍:线性回归,可预测连续值的输出。
函数:regression_learn
- 格式:
model regression_learn(json | string | array feature, double | int label) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray。 label int 观测值 label double 观测值 - 输出:
名称 类型 说明 model VARBINARY 模型输出
函数:regression_predict
- 格式:
double regression_predict(model, json | string | array feature) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray。 model VARBINARY 模型 - 输出:
名称 类型 说明 result double 预测值
Logistic Regression
介绍:监督学习算法,用于做0/1分类。
函数:logistic_learn
- 格式:
model logistic_learn(json | string | array feature, double | int label) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray label int 观测值,一定要0或者1 label double 观测值,一定要0或者1 - 输出:
名称 类型 说明 model VARBINARY 模型输出
函数:logistic_predict
- 格式:
int logistic_predict(model, json | string | array feature) - 输入:
名称 类型 说明 feature json 向量特征,只能输入jsonarray。例: [1,2,3]、[3.5,2,5.2]。feature array 同上,例: array[1,2,3]。featureJsonStr string string表达的jsonarray model VARBINARY 模型 - 输出:
名称 类型 说明 result double 预测值,0或者1