云数据库MongoDB版(ApsaraDB for MongoDB)是基于飞天分布式系统和高可靠存储引擎的在线数据库服务,完全兼容MongoDB协议,提供稳定可靠、弹性伸缩的数据库服务。本文主要介绍如何通过DLA Serverless Spark访问云数据库MongoDB。
云原生数据湖分析(DLA)产品已退市,云原生数据仓库 AnalyticDB MySQL 版湖仓版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相关使用文档,请参见访问MongoDB数据源。
前提条件
已经开通对象存储OSS(Object Storage Service)服务。具体操作请参考开通OSS服务。
已经创建云数据库MongoDB实例。具体请参考创建实例。
创建MongoDB的连接准备数据。
通过DMS连接MongoDB分片集群实例,执行以下命令在DMS上创建数据库config,并插入以下测试数据创建连接准备数据。具体示例如下:
db.createCollection("test_collection"); db.test_collection.insert( {"id":"id01","name":"name01"}); db.test_collection.insert( {"id":"id02","name":"name02"}); db.test_collection.insert( {"id":"id03","name":"name03"}); db.test_collection.find().pretty()准备DLA Spark访问MongoDB实例所需的安全组ID和交换机ID。具体操作请参见配置数据源网络。
DLA Spark访问MongoDB实例所需的安全组ID或交换机ID,已添加到MongoDB实例的白名单中。具体操作请参见设置白名单。
操作步骤
准备以下测试代码和依赖包来访问MongoDB,并将此测试代码和依赖包分别编译打包生成jar包上传至您的OSS。
测试代码示例:
package com.aliyun.spark import com.mongodb.spark.MongoSpark import com.mongodb.spark.config.{ReadConfig, WriteConfig} import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession import org.bson.Document object SparkOnMongoDB { def main(args: Array[String]): Unit = { //获取MongoDB的connectionStringURI,database和collection。 val connectionStringURI = args(0) val database = args(1) val collection = args(2) //Spark侧的表名。 var sparkTableName = if (args.size > 3) args(3) else "spark_on_mongodb_sparksession_test01" val sparkSession = SparkSession .builder() .appName("scala spark on MongoDB test") .getOrCreate() //Spark读取MongoDB数据有多种方式。 //使用Dataset API方式: //设置MongoDB的参数。 val sparkConf = new SparkConf() .set("spark.mongodb.input.uri", connectionStringURI) .set("spark.mongodb.input.database", database) .set("spark.mongodb.input.collection", collection) .set("spark.mongodb.output.uri", connectionStringURI) .set("spark.mongodb.output.database", database) .set("spark.mongodb.output.collection", collection) val readConf = ReadConfig(sparkConf) //获取Dataframe。 val df = MongoSpark.load(sparkSession, readConf) df.show(1) //使用MongoSpark.save入库数据到MongoDB。 val docs = """ |{"id": "id105", "name": "name105"} |{"id": "id106", "name": "name106"} |{"id": "id107", "name": "name107"} |""" .trim.stripMargin.split("[\\r\\n]+").toSeq val writeConfig: WriteConfig = WriteConfig(Map( "uri" -> connectionStringURI, "spark.mongodb.output.database" -> database, "spark.mongodb.output.collection"-> collection)) MongoSpark.save(sparkSession.sparkContext.parallelize(docs.map(Document.parse)), writeConfig) //使用Sql的方式,SQL的方式有两种,指定Schema和不指定Schema。 //指定Schema的创建方式,Schema中的字段必须和MongoDB中Collection的Schema一致。 var createCmd = s"""CREATE TABLE ${sparkTableName} ( | id String, | name String | ) USING com.mongodb.spark.sql | options ( | uri '$connectionStringURI', | database '$database', | collection '$collection' | )""".stripMargin sparkSession.sql(createCmd) var querySql = "select * from " + sparkTableName + " limit 1" sparkSession.sql(querySql).show //不指定Schema的创建方式,不指定Schema,Spark会映射MOngoDB中collection的Schema。 sparkTableName = sparkTableName + "_noschema" createCmd = s"""CREATE TABLE ${sparkTableName} USING com.mongodb.spark.sql | options ( | uri '$connectionStringURI', | database '$database', | collection '$collection' | )""".stripMargin sparkSession.sql(createCmd) querySql = "select * from " + sparkTableName + " limit 1" sparkSession.sql(querySql).show sparkSession.stop() } }MongoDB依赖的pom文件:
<dependency> <groupId>org.mongodb.spark</groupId> <artifactId>mongo-spark-connector_2.11</artifactId> <version>2.4.2</version> </dependency> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>3.8.2</version> </dependency>在页面左上角,选择MongoDB实例所在地域。
单击左侧导航栏中的。
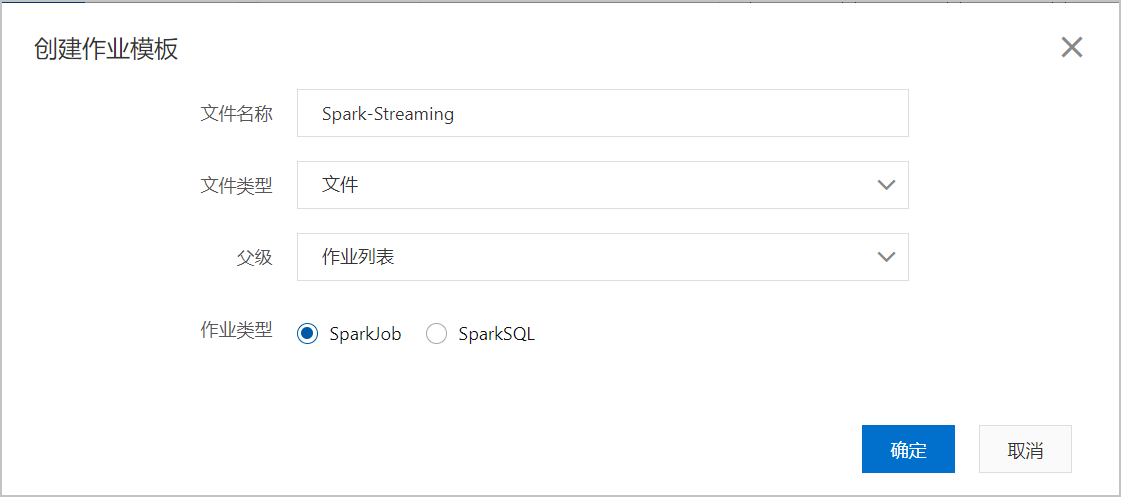
在作业编辑页面,单击创建作业。
在创建作业模板页面,按照页面提示进行参数配置后,单击确定创建Spark作业。
单击Spark作业名,在Spark作业编辑框中输入以下作业内容,并按照以下参数说明进行参数值替换。保存并提交Spark作业。
{ "args": [ "mongodb://root:xxx@xxx:3717,xxx:3717/xxx", #MongoDB集群中的“连接信息 (Connection StringURI)”。 "config", #MongoDB集群中的数据库名称。 "test_collection", #MongoDB集群中的collection名称。 "spark_on_mongodb" #Spark中创建映射MongoDB中collection的表名。 ], "file": "oss://spark_test/jars/mongodb/spark-examples-0.0.1-SNAPSHOT.jar", #存放测试软件包的OSS路径。 "name": "mongodb-test", "jars": [ "oss://spark_test/jars/mongodb/mongo-java-driver-3.8.2.jar", ##存放测试软件依赖包的OSS路径。 "oss://spark_test/jars/mongodb/mongo-spark-connector_2.11-2.4.2.jar" ##存放测试软件依赖包的OSS路径。 ], "className": "com.aliyun.spark.SparkOnMongoDB", "conf": { "spark.driver.resourceSpec": "small", "spark.executor.instances": 2, "spark.executor.resourceSpec": "small", "spark.dla.eni.enable": "true", "spark.dla.eni.vswitch.id": "vsw-xxx", #可访问MongoDB的交换机id。 "spark.dla.eni.security.group.id": "sg-xxx" #可访问MongoDB的安全组id。 } }
执行结果
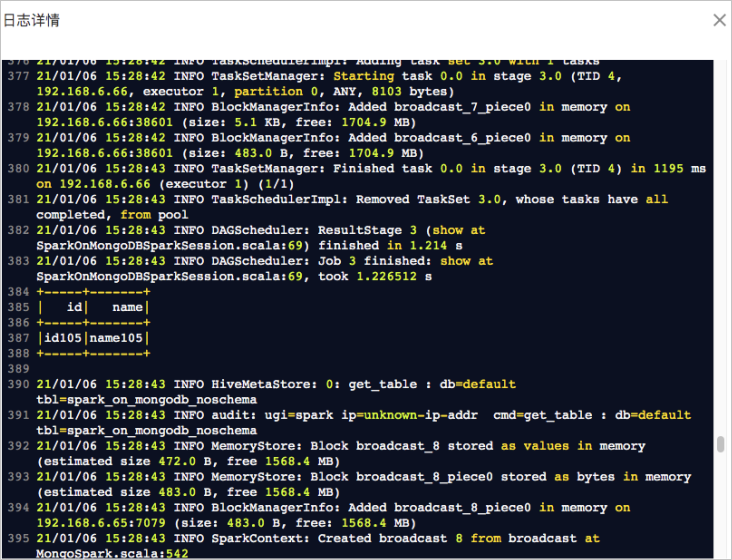
作业运行成功后,在任务列表中单击,查看作业日志。出现如下日志说明作业运行成功: