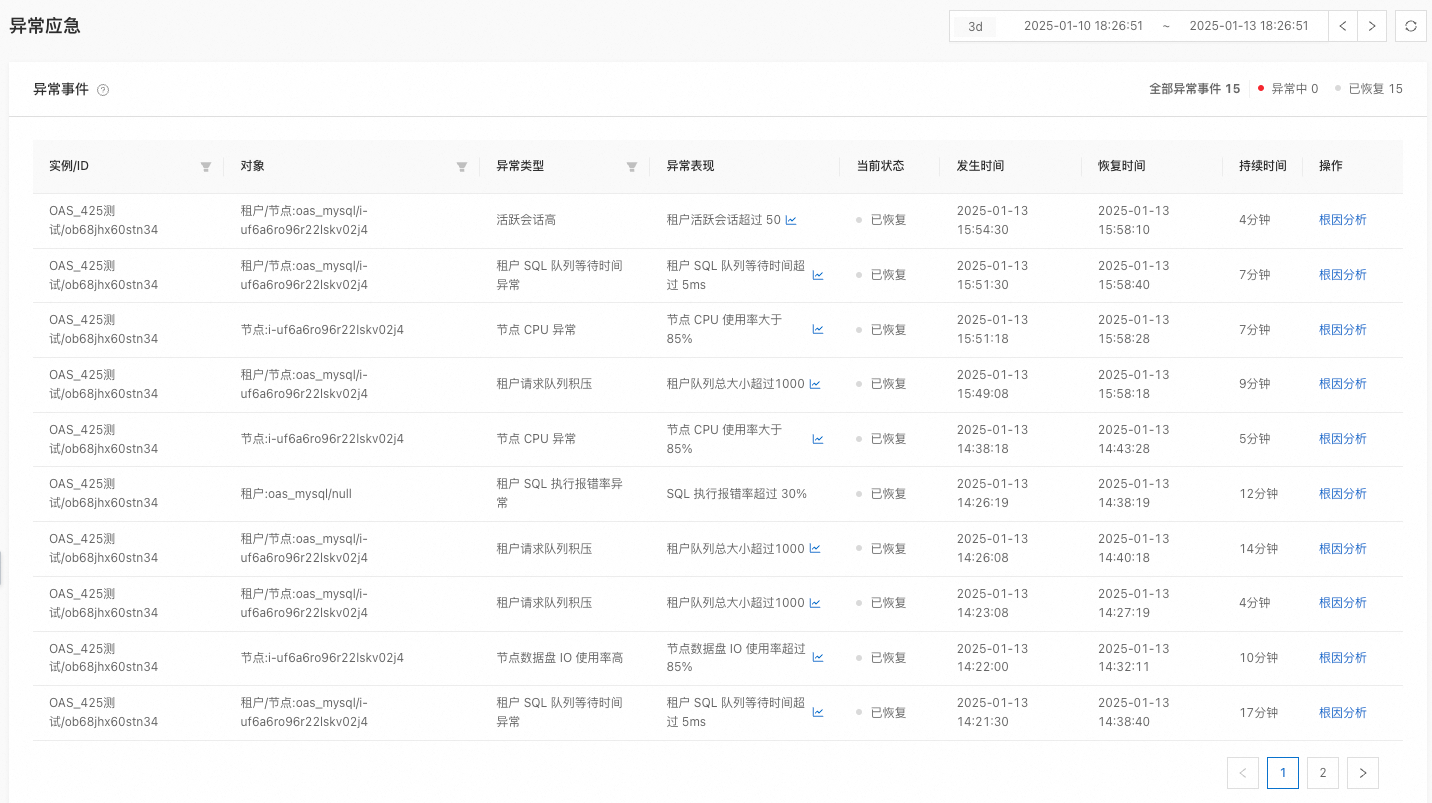
异常应急功能展示了数据库集群在最近 3 天内发生或正在发生的异常事件。您可以通过该功能快速获取集群的健康状态,并在异常事件发生时,进行根因分析,定位问题原因。
查看所有实例的异常事件列表
登录 OceanBase 管理控制台。
在左侧导航栏,选择 自治服务 > 异常应急。
在 异常事件 区域,查看所有实例的异常事件列表。
系统默认展示最近 3 天的全部异常事件,包括异常中的事件和已恢复的事件。目前支持以下异常事件类型:节点 CPU 异常、租户 CPU 异常、租户 SQL 队列等待时间异常、SQL 大量报错异常、数据盘 IO 使用率异常、租户活跃会话数异常、租户磁盘 IO 耗时异常、节点 clog 盘 IO 使用率高、节点数据盘 IO 耗时高、节点数据盘容量使用率高等。
查看单个实例的异常事件
在 异常事件 区域,单击目标实例 操作 列的 根因分析。
系统自动跳转到诊断中心的 异常应急 页面。
在 异常事件 区域,查看目标实例的异常事件,包括 对象、异常类型、异常表现、当前状态、发生时间、恢复时间、持续时间、操作。
单击单个事件 操作 列的 根因分析,查看该事件的根因分析和优化建议。
说明您可以单击 查看智能解读,查看 AI 提供的诊断结果和诊断建议。AI 智能解读内容,仅供参考。
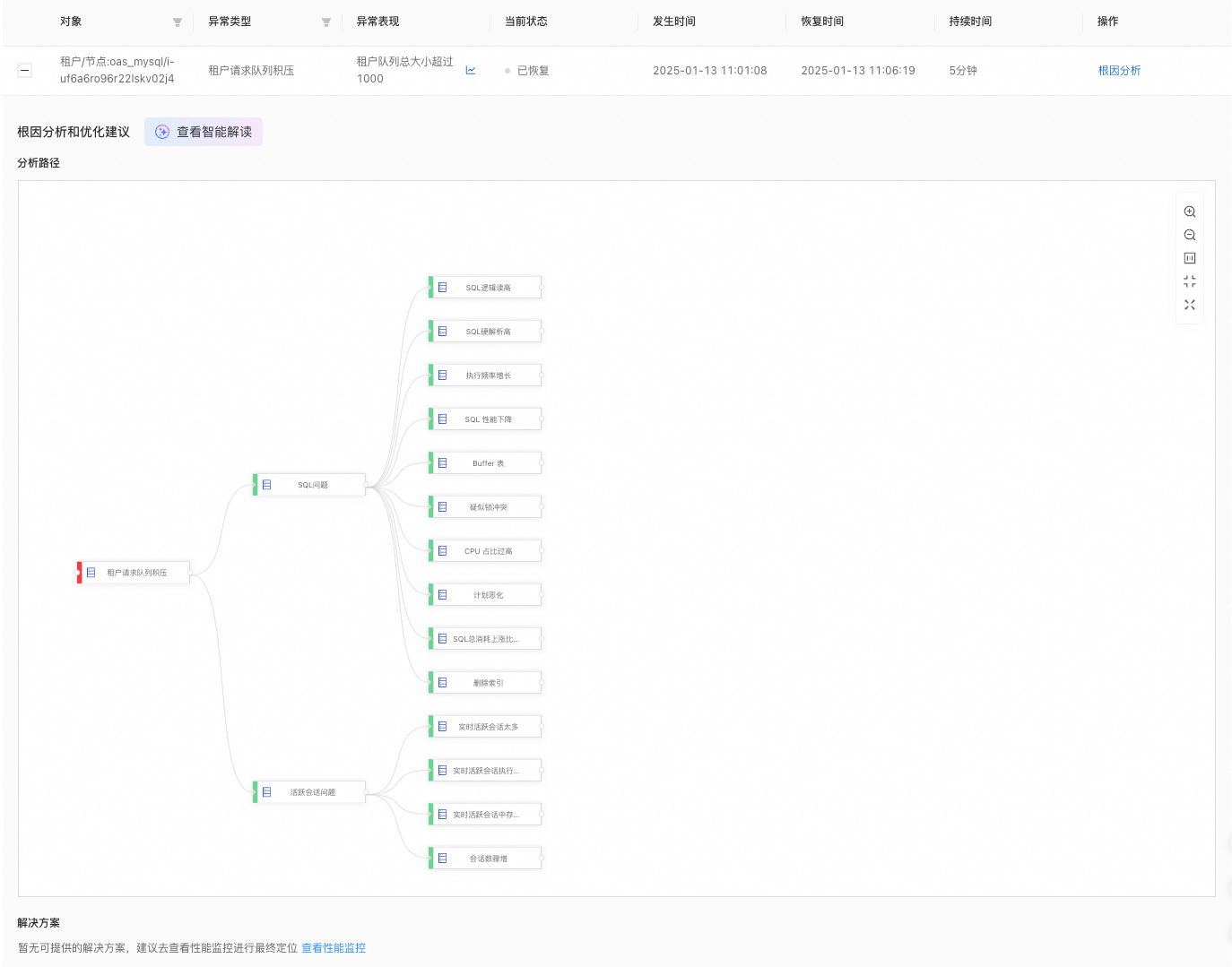
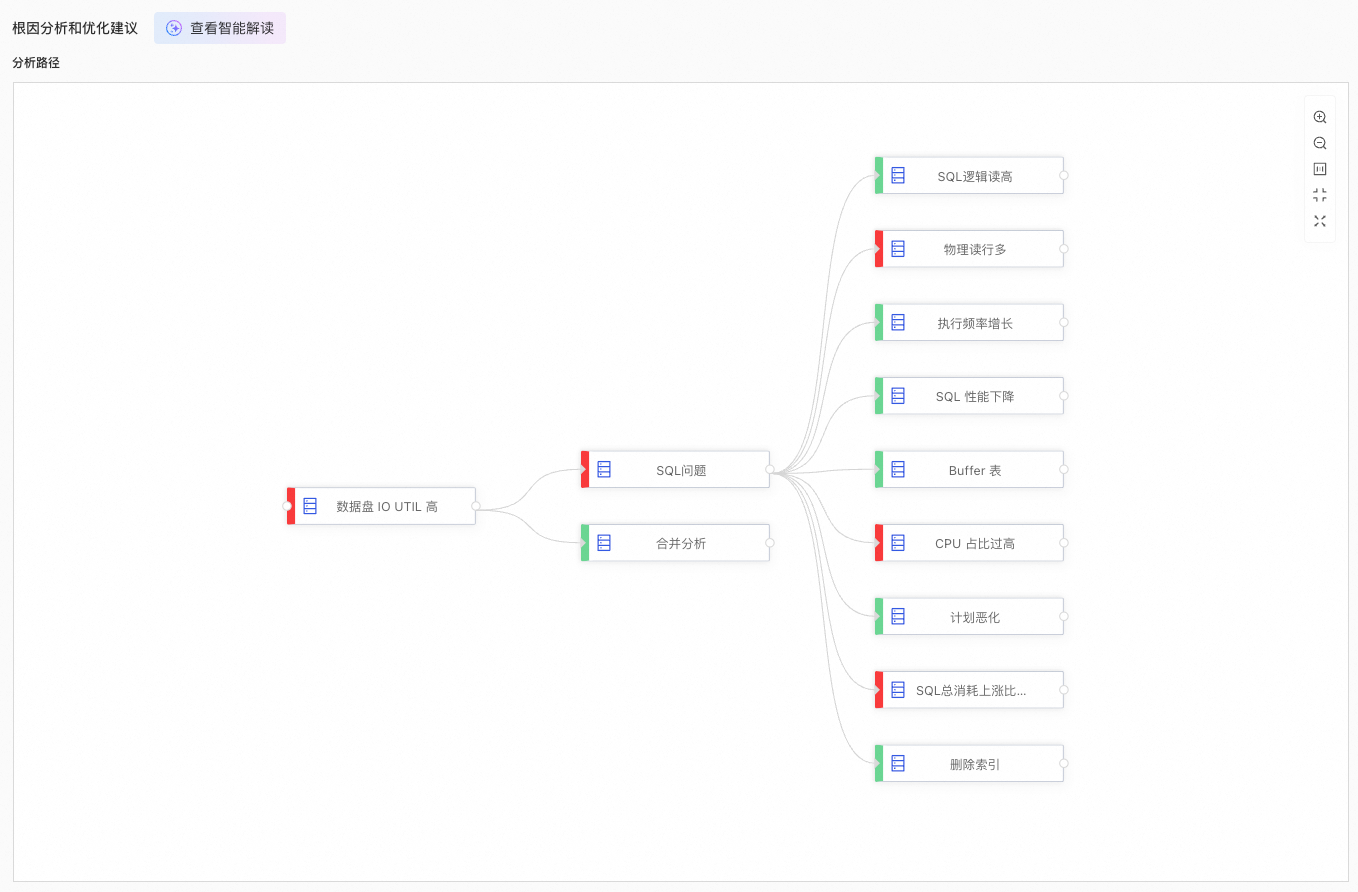
如果异常事件的原因在分析图谱中,系统会红色高亮显示该原因,并提供优化建议。
说明在分析图谱中,每个节点代表一条分析规则。当进行异常分析时,系统会遍历图谱以找到根因节点。根因节点会被红色高亮显示,而绿色节点则表示该规则未命中根因。
示例如下:
当指定时间段内 数据盘 IO UTIL 高 时,系统提供 物理读行多、CPU 占比过高 和 SQL 总消耗上涨比例超过阈值 的提示。在分析路径 区域,您可以单击红色高亮方框查看对应的根因分析。
在 SQL 汇总信息 区域,系统默认显示 SQL 汇总时间段、总执行次数、总报错次数、最大响应时间(ms)、CPU 时间(ms)、计划生成时间(ms)。您可以通过单击 列管理 查看更多信息。

在 可能的根因 SQL 区域,您可以查看可能引起该问题的 SQL,并单击 操作 列的 查看 SQL 详情。

如果异常事件的原因不在分析图谱中,系统会在 解决方案 区域提供建议。示例如下:
当发现 租户请求队列积压 时,系统仍会显示分析图谱,并在 解决方案 区域提供建议。