Spark on MaxCompute是MaxCompute提供的兼容开源Spark的计算服务。它在统一的计算资源和数据集权限体系之上,提供Spark计算框架,支持您以熟悉的开发使用方式提交运行Spark作业,满足更丰富的数据处理分析需求。
使用限制
Spark on MaxCompute支持如下场景:
离线计算场景,例如GraphX、Mllib、RDD、Spark-SQL、PySpark等。
读写MaxCompute Table。
引用MaxCompute中的文件资源。
读写VPC环境下的服务。例如,RDS、Redis、HBase、ECS上部署的服务等。
读写OSS非结构化存储。
读OSS、Hologres以及HBase外部表。
Spark on MaxCompute暂不支持如下场景:
交互式和流计算类需求,例如Spark-Shell、Spark-SQL-Shell、PySpark-Shell、Spark Streaming等。
不支持访问MaxCompute除OSS、Hologres以及HBase外部表之外的外部表、内建函数和自定义函数(MaxCompute UDF)。
不支持在使用按量计费开发者版资源的项目中执行Spark作业。按量计费开发者版仅支持MaxCompute SQL(支持使用UDF)、PyODPS作业。
不支持Checkpoint功能。
关键特性
支持原生多版本Spark作业。
MaxCompute支持社区原生Spark、完全兼容Spark的API,同时支持多个Spark版本同时运行。Spark on MaxCompute提供原生的Spark WebUI供您查看。
统一的计算资源。
Spark on MaxCompute类似MaxCompute SQL、MapReduce等作业类型,运行在MaxCompute项目统一开通的计算资源中。
统一的数据和权限管理。
完全遵循MaxCompute项目的权限体系,在访问用户权限范围内安全地查询数据。
与开源系统相同的使用体验。
Spark on MaxCompute与社区开源Spark保持相同的体验(例如开源应用的UI界面、在线交互等),完全符合Spark用户使用习惯。开源应用的调试过程中需要使用开源UI,Spark on MaxCompute提供原生的开源实时UI和查询历史日志的功能。其中,对于部分开源应用还支持交互式体验,在后台引擎运行后即可进行实时交互。
系统结构
Spark on MaxCompute是阿里云通过Spark on MaxCompute的解决方案,让原生Spark能够在MaxCompute中运行。
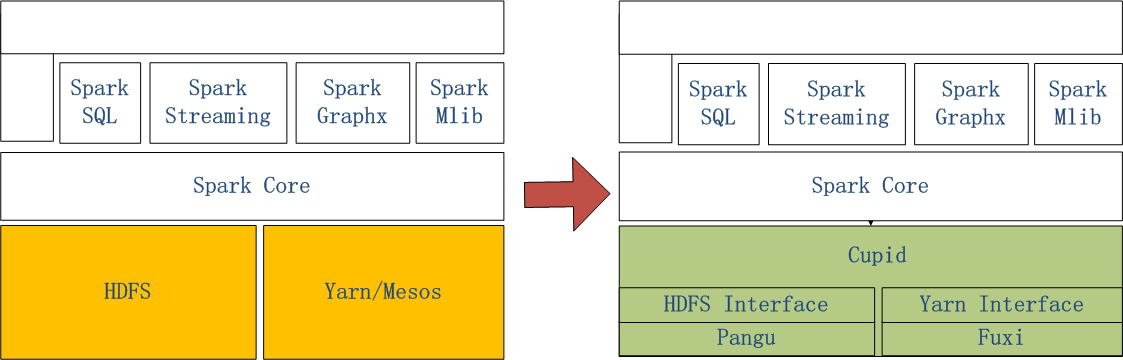
左侧是原生Spark的架构图,右侧的Spark on MaxCompute运行在阿里云自研的Cupid平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架。