
OpenTSDB是可扩展的分布式时序数据库,底层依赖HBase。作为基于通用存储开发的时序数据库典型代表,起步比较早,在时序市场的认可度相对较高。阿里云智能TSDB高度兼容OpenTSDB协议,采用自研的索引,数据模型,流式聚合等技术手段提供更强大的时序能力。本文从运维管控,功能,成本,性能等方面对比阿里云智能TSDB和OpenTSDB的优势。
背景信息
| 类别 | 子类别 | OpenTSDB | TSDB |
|---|---|---|---|
| 运维管控 | 服务可用性 | 需自行保障,自行搭建集群,自建组件依赖。 | 99.9% |
| 数据可靠性 | 需自行保障,自行搭建集群,自建组件依赖。 | 99.9999% | |
| 软硬件投入 | 数据库服务器成本相对较高。 | 无软硬件投入,按需付费。 | |
| 维护成本 | 需招聘专职TSDB DBA人员来维护,花费大量人力成本。 | 托管服务。 | |
| 部署扩容 | 需硬件采购、机房托管、机器部署等工作,周期较长。 | 即时开通,快速部署,弹性扩容。 | |
| 依赖组件繁重 | 依赖AysncHBase,HBase等运维成本高。 | 0运维。 | |
| 配置调优参数繁多 | SALT、连接数,同步刷盘参数,Compaction等等。 | 默认参数采用最佳实践。 | |
| 建表语句 | 需要运维静态建表语句。 | 建表语句托管,用户透明。 | |
| 监控报警体系 | 依赖外部搭建。 | 完整的自监控链路。 | |
| 功能 | 数据模型 | 单值模型。 | 同时支持多值模型和单值模型。 |
| SDK | 开源SDK不支持查询。 | 健壮稳定的Java SDK。 | |
| 数据类型多样性 | 数值类型。 | 支持数值,布尔,字符串等多种数据类型。 | |
| SQL查询能力 | 不具备。 | 支持SQL的分析查询。 | |
| 管理控制台 | 内置简单的图形展示。 | 支持丰富的详情展示,数据管理等。 | |
| 中文支持 | 仅支持英文字符。 | 支持英文字符和中文字符。 | |
| 单一维度(tags 可选择) | tags是必选参数。 | tags是可选参数。 | |
| TagKey个数 | 最多8个。 | 可支持16个。 | |
| 集成能力 | 开源产品,与云产品集成能力弱。 | 同Flink,物联网平台无缝对接,生态丰富。 | |
| 成本 | 数据压缩 | 通用压缩,压缩率低。 | 时序领域专用压缩,压缩率高。 |
| 稳定性 | 数据读取 | 读写耦合,容易造成连接数耗尽,读写失败概率大。 | 读写线程池分离,易于管理连接,读写稳健。 |
| 聚合器 | 内存物化聚合,容易造内存OOM。 | 流式聚合,内存管理粒度细,可控性强。 |
OpenTSDB协议兼容性
由于阿里云TSDB底层技术架构同OpenTSDB的实现区别巨大,对于OpenTSDB的一些运维接口不会兼容。比如OpenTSDB的元数据管理接口/api/tree, /api/uid等等。根据OpenTSDB的官网API Endpoints(HTTP API) ,下表列举了TSDB的兼容程度。
| OpenTSDB 协议API | TSDB是否兼容 |
|---|---|
| /s | 否 |
| /api/aggregators | 是 |
| /api/annotation | 否 |
| /api/config | 是 |
| /api/dropcaches | 否 |
| /api/put | 是 |
| /api/rollup | 否 |
| /api/histogram | 否 |
| /api/query | 是 |
| /api/query/last | 是 |
| /api/search/lookup | 是 |
| /api/serializers | 是 |
| /api/stats | 是 |
| /api/suggest | 是 |
| /api/tree | 否 |
| /api/uid | 否 |
| /api/version | 是 |
除此之外,TSDB提供了一些面向时序更友好的接口。包括
| TSDB 自定义协议API | 描述 |
|---|---|
| /api/mput | 多值写入 |
| /api/mquery | 多值查询 |
| /api/query/mlast | 多值查询最新数据点 |
| /api/dump_meta | 查询 Tagk 下的 Tagv |
| /api/ttl | 设置数据时效 |
| /api/delete_data | 清理数据 |
| /api/delete_meta | 清理时间线 |
性能对比
测试数据说明
这里介绍的是用作测试查询性能的数据集。下面将从Metric、时间线、Value和采集周期四个方面来描述:
metric
固定指定一个metric为m。
tagkv
前四个tagkv全排列,形成10 * 20 * 100 * 100 = 2000000条时间线,最后IP对应2000000条时间线从1开始自增。
| tag_k | tag_v |
|---|---|
| zone | z1~z10 |
| cluster | c1~c20 |
| group | g1~100 |
| app | a1~a100 |
| ip | ip1~ip2000000 |
value
度量值为[1, 100]区间内的随机值
interval
采集周期为 10 秒,持续摄入 3 小时,总数据量为3 * 60 * 60 / 10 * 2000000 = 2,160,000,000个数据点。
统计结果说明
压测模式如下:
| 压测参数 | 参数值 | 说明 |
|---|---|---|
| 压测持续分钟数 | 3 | |
| 压力模式 | 固定 | 不同于阶梯和脉冲模式,固定模式不会调节压测的并发量。 |
| 施压机数量 | 5 | |
| 单台施压机 TPS 值 | 1000 | |
| 获取 Connection 超时时间(毫秒) | 600000 | |
| 连接建立超时时间(毫秒) | 600000 | |
| 请求获取数据超时时间(毫秒) | 600000 | 考虑到大查询会很耗时,一旦 timeout 可能会导致 TPS 统计误差。 |
| 调用方式 | 同步 |
每次测试进行之前均重启数据库服务,避免之前的测试操作可能还占用资源。同时对测试操作进行预热,避免未预热情况下,首次请求的耗时过长,而影响到RT统计的准确性。
测试环境说明
机型配置
写入机型:2C8G
查询机型:64C256G
HBase机型:8C16G * 5
数据库版本
OpenTSDB:2.3.2+HBase 1.5.0.1
TSDB:2.4.2
写入性能对比
写入场景列表
数据点写入的压力由上述压测配置可得知,5台压测机,每台压测机设置目标TPS为1000,则可以提供5000 TPS的写入压力。同时,为了确保测试的公平性,TSDB和OpenTSDB均使用同步写入,并开启落盘功能。其中,为了体现出不同的采集周期(interval),各个场景写入数据点的时间戳(timestamp),都基于某一时刻(base_time),随着调用次数(N)的增加而递增,即可用公式表示为
timestamp = base_time + interval * N
| 采集周期(秒) | Metric | Tag | |
|---|---|---|---|
| 场景一 | 10 | 一个 | 4tagk * 2500tagv |
| 场景二 | 10 | 十个 | 4tagk * 2500tagv |
| 场景三 | 60 | 一个 | 4tagk * 2500tagv |
| 场景四 | 60 | 十个 | 4tagk * 2500tagv |
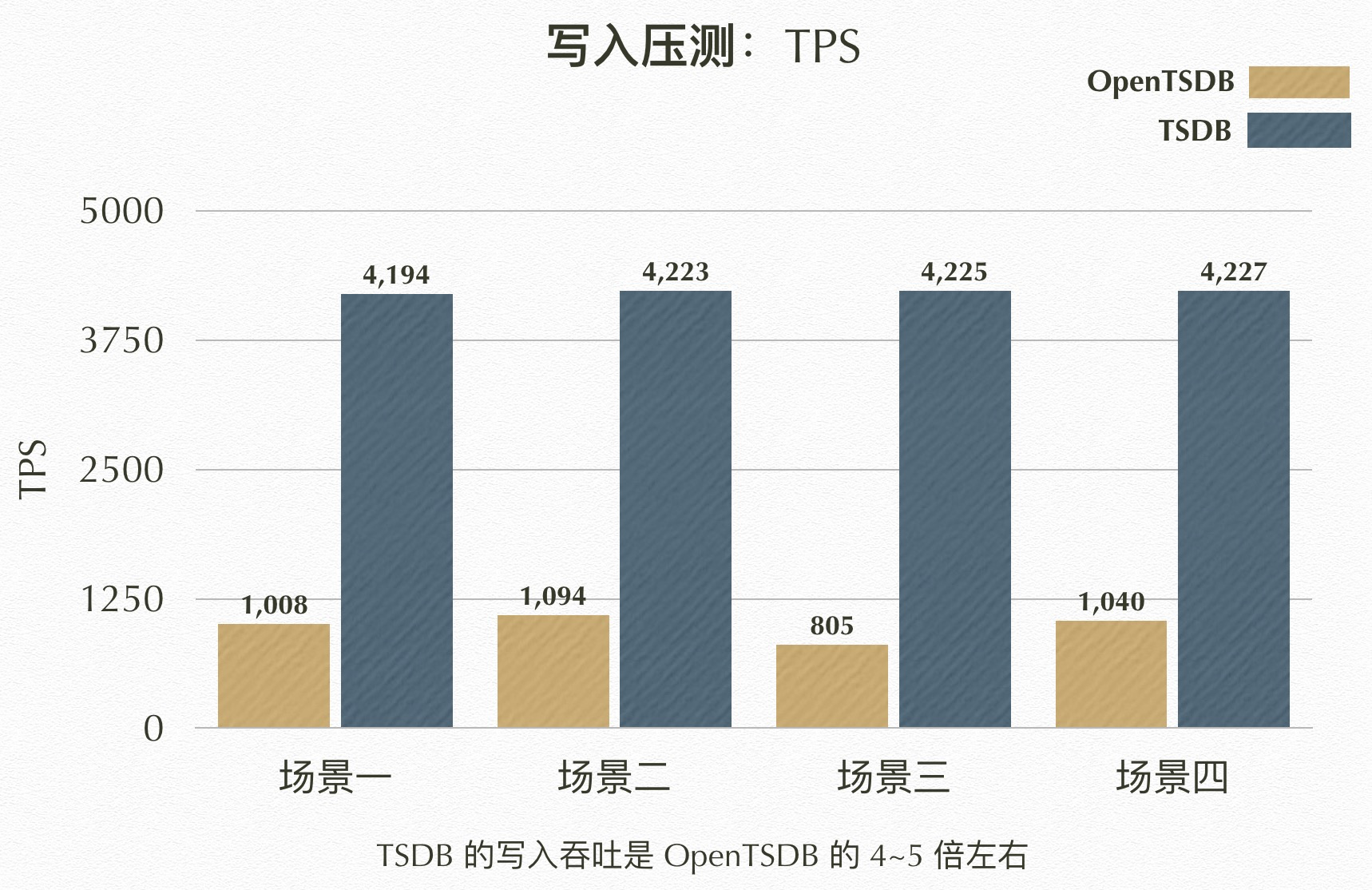
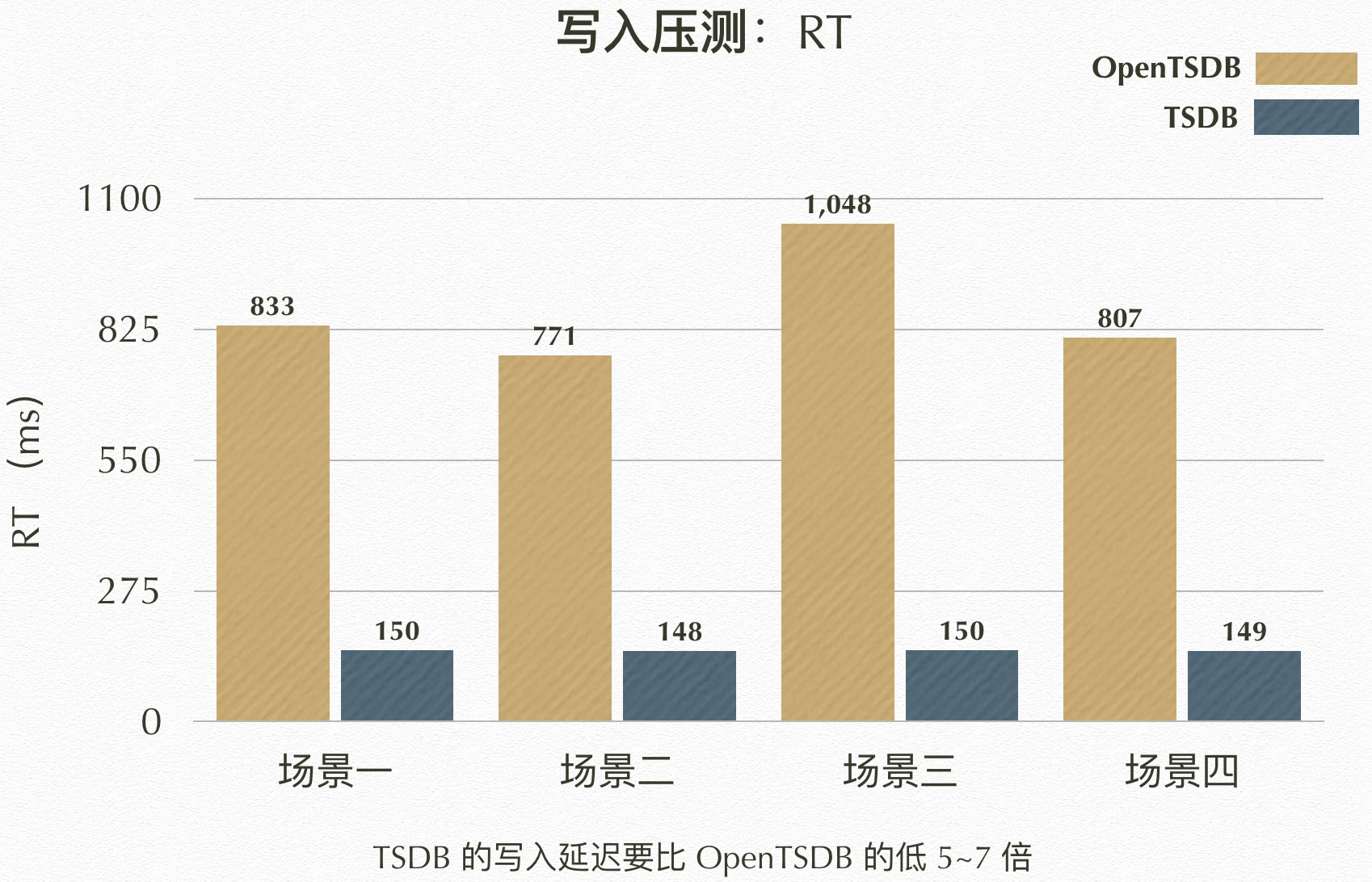
TSDB 结果
| 场景 | TPS | RT(ms) | MinRT | MaxRT | 80%RT | 95%RT | 99%RT |
|---|---|---|---|---|---|---|---|
| 场景一 | 4194.23 | 149.91 | 36.9 | 1808.0 | 210.42 | 239.11 | 250.38 |
| 场景二 | 4223.09 | 148.4 | 37.2 | 474.22 | 209.74 | 238.32 | 248.52 |
| 场景三 | 4225.24 | 150.37 | 37.09 | 645.57 | 211.22 | 239.01 | 249.88 |
| 场景四 | 4227.01 | 148.61 | 37.4 | 888.72 | 209.93 | 238.68 | 249.38 |
OpenTSDB 结果
| 场景 | TPS | RT(ms) | MinRT | MaxRT | 80%RT | 95%RT | 99%RT |
|---|---|---|---|---|---|---|---|
| 场景一 | 1008.12 | 832.68 | 47.19 | 1310.56 | 1158.44 | 1255.66 | 1283.67 |
| 场景二 | 1094.4 | 770.82 | 43.64 | 1469.04 | 1078.78 | 1238.06 | 1281.69 |
| 场景三 | 804.82 | 1047.59 | 132.18 | 1297.71 | 1188.12 | 1269.82 | 1281.32 |
| 场景四 | 1039.72 | 807.29 | 44.43 | 1421.03 | 1110.46 | 1242.02 | 1281.76 |
性能对比分析
TPS
RT
查询性能对比
查询场景列表
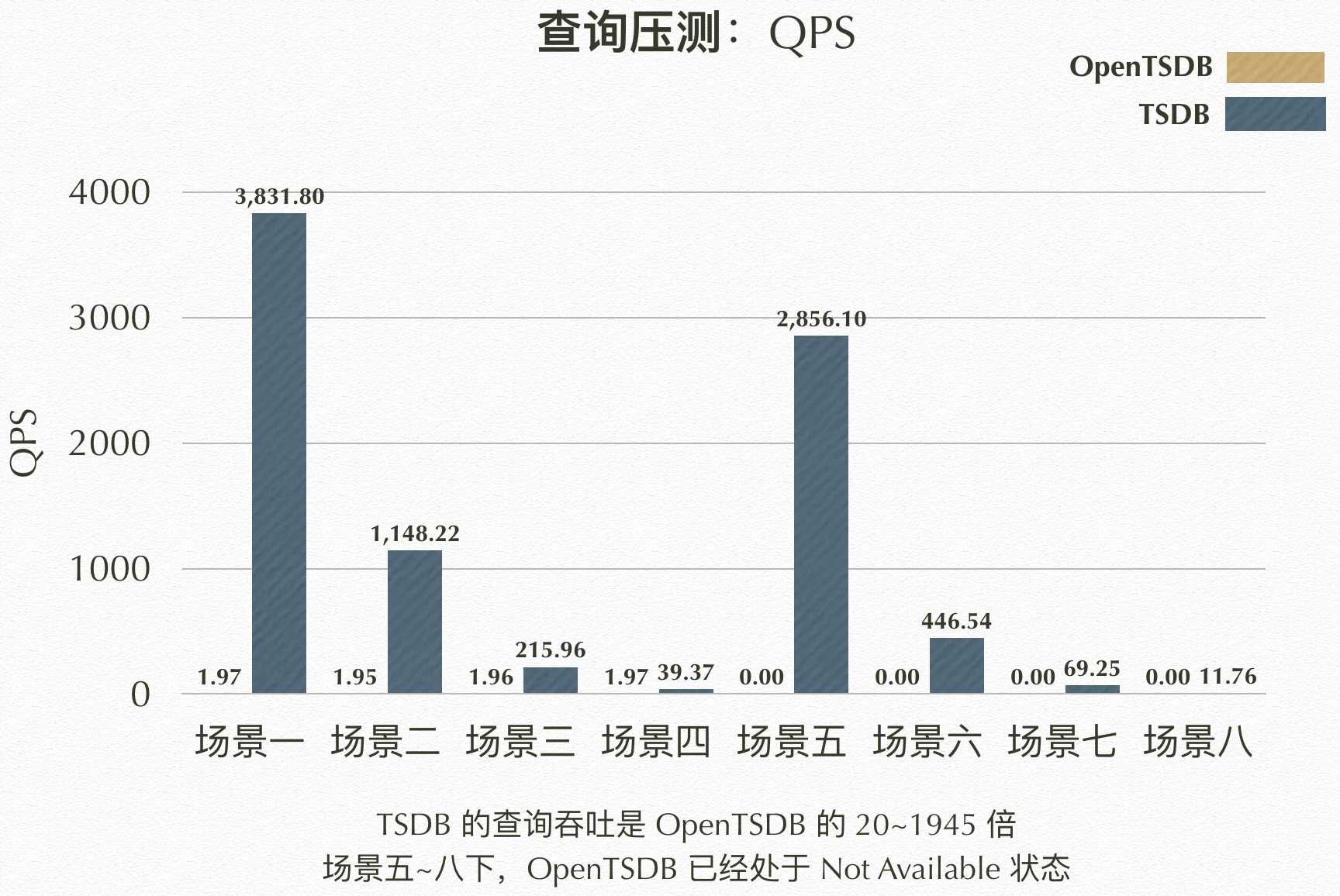
数据点查询的压力,同样可由上述压测配置可得知,5 台压测机,每台压测机设置目标 QPS 为 1000,则可以提供 5000 QPS 的查询压力。和写入不同的是,因为查询的目标数据集相对而言更庞大,如果直接使用 5000 的 QPS 进行压测,可能会因为查询队列满,出现空跑的情况。因此,为了测试的准确性,这里的 5000 实际上是 QPS 的上限,所有的查询压测开始之前,都通过观察数据库服务端日志和资源消耗情况,确保数据库能正常运作的情况下,进行压测的。而针对场景五到场景八,这四种涵盖整个数据集的查询场景,即便将压测并发量从 5000 降低到 500、50、5、1 之后,仍然会导致 OpenTSDB 不可用,我们这里使用 N/A 来表示 Not Available 状态,并在后续分析图表中,使用 0 替代表示。
| Metric | Tag(tagk,tagv组合) | 时间范围 | |
|---|---|---|---|
| 场景一 | 一个 | 1个Tag | 5min |
| 场景二 | 一个 | 10个Tag | 5min |
| 场景三 | 一个 | 100个Tag | 5min |
| 场景四 | 一个 | 1000个Tag | 5min |
| 场景五 | 一个 | 1个Tag | 3hour |
| 场景六 | 一个 | 10个Tag | 3hour |
| 场景七 | 一个 | 100个Tag | 3hour |
| 场景八 | 一个 | 1000个Tag | 3hour |
对应查询语句
# 5min
{"start":1546272000,"end":1546272300,"queries":[{"aggregator":"count","metric":"m","tags":{"ip":"i1"}}]}
{"start":1546272000,"end":1546272300,"queries":[{"aggregator":"count","metric":"m","tags":{"cluster":"c1","group":"h1","app":"a1"}}]}
{"start":1546272000,"end":1546272300,"queries":[{"aggregator":"count","metric":"m","tags":{"zone":"z1","cluster":"c1","group":"h1"}}]}
{"start":1546272000,"end":1546272300,"queries":[{"aggregator":"count","metric":"m","tags":{"cluster":"c1","group":"h1"}}]}
# 3hour
{"start":1546272000,"end":1546282800,"queries":[{"aggregator":"count","metric":"m","tags":{"ip":"i1"}}]}
{"start":1546272000,"end":1546282800,"queries":[{"aggregator":"count","metric":"m","tags":{"cluster":"c1","group":"h1","app":"a1"}}]}
{"start":1546272000,"end":1546282800,"queries":[{"aggregator":"count","metric":"m","tags":{"zone":"z1","cluster":"c1","group":"h1"}}]}
{"start":1546272000,"end":1546282800,"queries":[{"aggregator":"count","metric":"m","tags":{"cluster":"c1","group":"h1"}}]}TSDB 结果
| 场景 | TPS | RT(ms) | MinRT | MaxRT | 80%RT | 95%RT | 99%RT |
|---|---|---|---|---|---|---|---|
| 场景一 | 3831.8 | 44.14 | 36.94 | 416.98 | 44.51 | 46.73 | 75.5 |
| 场景二 | 1148.22 | 657.77 | 105.96 | 1054.96 | 715.5 | 745.87 | 796.8 |
| 场景三 | 215.96 | 3522.96 | 557.81 | 4067.14 | 3679.5 | 3786.29 | 3854.57 |
| 场景四 | 39.37 | 19692.53 | 1784.93 | 22370.1 | - | - | - |
| 场景五 | 2856.1 | 262.76 | 41.29 | 847.01 | 296.99 | 443.52 | 489.4 |
| 场景六 | 446.54 | 1684.15 | 67.75 | 2161.85 | 1802.8 | 1898.0 | 1959.02 |
| 场景七 | 69.25 | 11237.9 | 1873.55 | 12776.56 | 11917.05 | 12133.61 | 12316.79 |
| 场景八 | 11.76 | 65615.45 | 5742.12 | 86952.76 | - | - | - |
OpenTSDB 结果
| 场景 | TPS | RT(ms) | MinRT | MaxRT | 80%RT | 95%RT | 99%RT |
|---|---|---|---|---|---|---|---|
| 场景一 | 1.97 | 77842.67 | 10486.16 | 109650.51 | - | - | - |
| 场景二 | 1.95 | 78062.6 | 12723.96 | 119911.53 | - | - | - |
| 场景三 | 1.96 | 78865.02 | 15942.89 | 141365.75 | - | - | - |
| 场景四 | 1.97 | 77331.91 | 7780.02 | 113582.65 | - | - | - |
| 场景五 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| 场景六 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| 场景七 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| 场景八 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
性能对比分析
QPS
RT

在高并发情况下(>500),OpenTSDB几乎处于不可用状态,而TSDB仍然可以稳定运行。