在阿里巴巴的数据体系中,我们建议将数据仓库分为三层,自下而上为:数据引入层(ODS,Operation Data Store)、数据公共层(CDM,Common Data Model)和数据应用层(ADS,Application Data Service)。
数据仓库的分层和各层级用途如下图所示。
数据引入层ODS(Operation Data Store):存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到MaxCompute的职责,同时记录基础数据的历史变化。
数据公共层CDM(Common Data Model,又称通用数据模型层),包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念,建立整个企业的一致性维度。降低数据计算口径和算法不统一风险。
公共维度层的表通常也被称为逻辑维度表,维度和维度逻辑表通常一一对应。
公共汇总粒度事实层(DWS):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表。
公共汇总粒度事实层的表通常也被称为汇总逻辑表,用于存放派生指标数据。
明细粒度事实层(DWD):以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细层事实表。可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
明细粒度事实层的表通常也被称为逻辑事实表。
数据应用层ADS(Application Data Service):存放数据产品个性化的统计指标数据。根据CDM与ODS层加工生成。
该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。整体数据分类架构如下图所示。 在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
在本教程中,从交易数据系统的数据经过DataWorks数据集成,同步到数据仓库的ODS层。经过数据开发形成事实宽表后,再以商品、地域等为维度进行公共汇总。
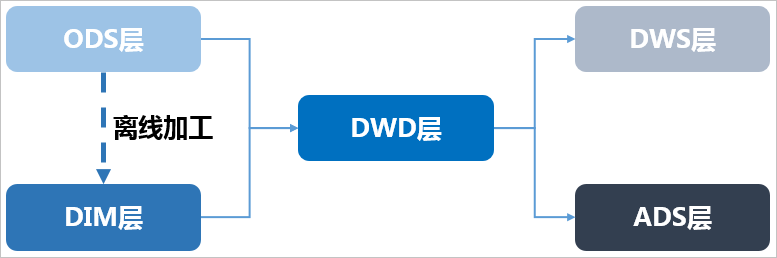
整体的数据流向如下图所示。其中,ODS层到DIM层的ETL(萃取(Extract)、转置(Transform)及加载(Load))处理是在MaxCompute中进行的,处理完成后会同步到所有存储系统。ODS层和DWD层会放在数据中间件中,供下游订阅使用。而DWS层和ADS层的数据通常会落地到在线存储系统中,下游通过接口调用的形式使用。