简介
消息队列 Kafka 是一个分布式的、高吞吐量、高可扩展性消息队列服务,广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,是大数据生态中不可或缺的产品之一。这里主要介绍通过“数据工作台”使用SparkStreaming对接Kafka 0.10的方法。
前置条件
Spark集群和Kafka集群在同一个VPC下。
进入Spark分析集群页面,选择“数据库连接”>“连接信息”,查看Spark集群的VPC ID信息。如下图:然后部署Kafka时选择和Spark相同的VPC ID。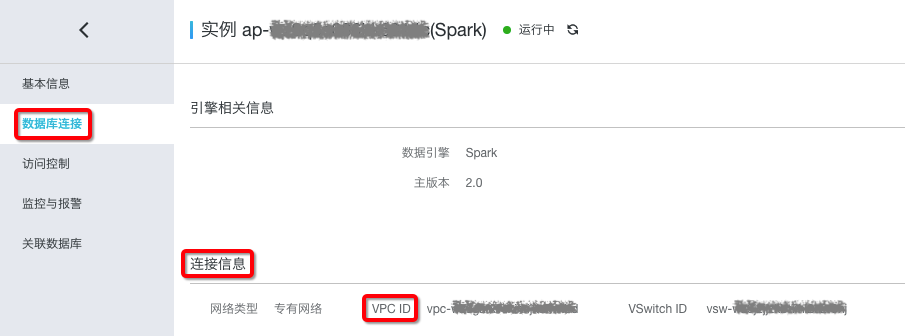
Kafka的购买和部署流程
进入 Kafka 售卖页购买 Kafka 实例,进入Kafka购买链接。具体 Kafka 的部署请参照Kafka部署参考。Kafka集群已配置Spark集群的白名单。
首先在阿里云控制台进入“专有网络VPC”,找到Spark集群的VPC ID对应的IPv4网段。如下图:然后进入Kafka集群配置白名单,添加上述IPv4网段。如下图: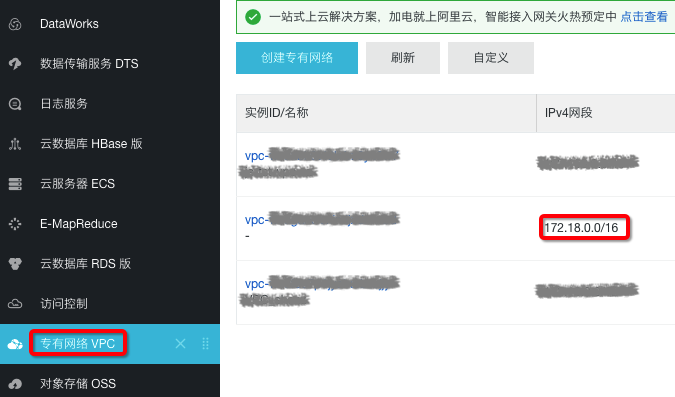

- Kafka集群已经创建Topic、Consumer Group。
本例使用的Topic名称为:topic01,Consumer Group名称为:testgroup和spark-executor-testgroup。
注意:因为SparkStreaming在消费Kafka时,Spark的executor会在Group前面加上“spark-executor-”,所以需要在Kafka集群创建两个Consumer Group。 - 发送数据到Topic01。
下载Jar包到ECS机器上(和Kafka集群在相同的VPC下;Kafka集群开通了ECS机器白名单):
下载的jar包分别放入到如下目录:wget https://spark-home.oss-cn-shanghai.aliyuncs.com/common_test/common-test-0.0.1-SNAPSHOT.jarwget https://spark-home.oss-cn-shanghai.aliyuncs.com/kafka010/kafka-clients-0.10.2.2.jarwget https://spark-home.oss-cn-shanghai.aliyuncs.com/kafka010/slf4j-api-1.7.16.jar
然后运行如下命令,向Topic01发送数据。/opt/jars/kafka/kafka-clients-0.10.2.2.jar/opt/jars/kafka/slf4j-api-1.7.16.jar/opt/jars/test/common-test-0.0.1-SNAPSHOT.jar
其中:xxx1:9092,xxx2:9092,xxx3:9092是Kafka集群的“默认接入点”。java -cp /opt/jars/kafka/*:/opt/jars/test/common-test-0.0.1-SNAPSHOT.jar com.aliyun.kafka.KafkaProducerDemo_java xxx1:9092,xxx2:9092,xxx3:9092 topic01
使用“数据工作台”>“作业管理”运行样例
步骤 1:通过“资源管理”上传样例代码Jar包
下载样例代码jar包“sparkstreaming-0.0.1-SNAPSHOT.jar”以及依赖的jar包到本地目录。
wget https://spark-home.oss-cn-shanghai.aliyuncs.com/spark_example/sparkstreaming-0.0.1-SNAPSHOT.jarwget https://spark-home.oss-cn-shanghai.aliyuncs.com/kafka010/kafka-clients-0.10.2.2.jarwget https://spark-home.oss-cn-shanghai.aliyuncs.com/kafka010/spark-streaming-kafka-0-10_2.11-2.3.2.jar
在“数据工作台”>“资源管理”中添加文件夹“sparkstreaming”。
上传下载的jar包到此文件夹。如下图:

步骤 2:通过“作业管理”创建并编辑作业内容
在“数据工作台”>“作业管理”中创建Spark作业,作业内容如下:
--class com.aliyun.spark.SparkStreamingOnKafka010--jars /sparkstreaming/spark-streaming-kafka-0-10_2.11-2.3.2.jar,/sparkstreaming/kafka-clients-0.10.2.2.jar--driver-memory 1G--driver-cores 1--executor-cores 2--executor-memory 2G--num-executors 1--name sparkstreaming/sparkstreaming/sparkstreaming-0.0.1-SNAPSHOT.jarxxx1:9092,xxx2:9092,xxx3:9092 topic01 testgroup
作业内容参数说明:
| 参数 | 说明 |
| xxx1:9092,xxx2:9092,xxx3:9092 | Kafka集群的“默认接入点”。 |
| topic01 testgroup | 分别是Kafka集群创建的Topic和Consumer Group。 |
如下图:
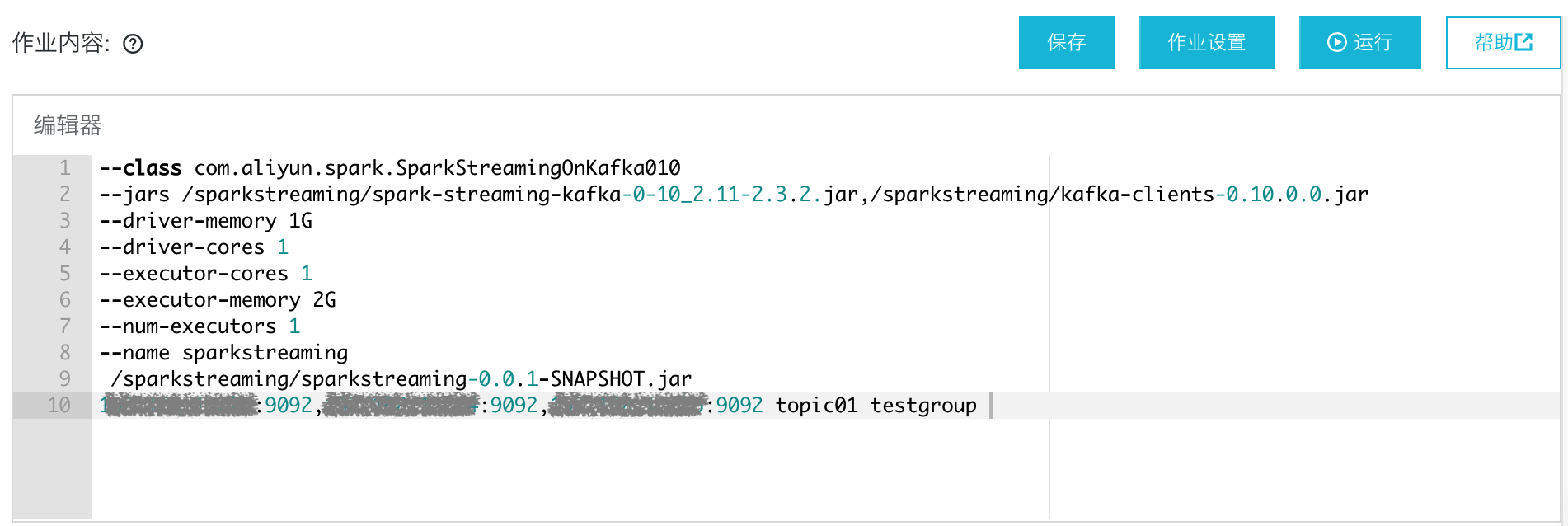
步骤 3:通过“作业管理”运行作业并查看结果
作业编辑完成后点击“运行”,选择Spark集群。运行状态会在下侧显示,如图:

运行成功后点击“YarnUI”,翻到最后看到如下结果表明Spark读取Kafka成功。如下:
-------------------------------------------Time: 1555384700000 ms-------------------------------------------(this,1)(is,1)(value,1)(message's,1)(the,1)
小结
- 本例代码可参考:SparkStreamingOnKafka010.scala
- 更多样例代码可参考:Spark样例代码
该文章对您有帮助吗?