
功能优势
分析型数据库MySQL版向量分析功能在通用性、性能优化和产品化上与普通向量检索系统相比有以下优势。
高维向量数据的高准度和高性能
以典型的人脸512维向量为例,分析型数据库MySQL版向量分析提供百亿向量100 QPS、50毫秒响应时间(RT)约束下99%的数据召回率;两亿向量1000 QPS、1秒 RT约束下99%的数据召回率。
结构化和非结构化混合检索
例如,可以检索与输入图片中的连衣裙相似度最高、价格在100元到200元之间且上架时间在最近1个月以内的产品。
支持数据实时更新
传统的向量分析系统中数据只能按照T+1更新,不支持数据实时写入。分析型数据库MySQL版向量分析支持数据实时更新和查询。
支持向量分析碰撞
分析型数据库MySQL版向量分析支持KNN-Join SQL,即比较一批向量与另外一批向量的相似度,类似于Spark中的KNN-Join操作。
典型的应用场景有商品去重,计算新加入的商品与历史商品库中有哪些是相似的。人脸聚类,计算一段时间内的人脸库中,哪些人脸是同一个人。
易用性
分析型数据库MySQL版向量分析申请即可使用,支持标准SQL,简化开发流程。同时,分析型数据库MySQL版向量分析内置常用特征提取和属性提取,也支持集成第三方特征提取服务。
高维向量数据的高准度和高性能
分析型数据库MySQL版向量分析支持两种模式:无损模式和微损模式。无损模式下,保证100%的数据召回率。微损模式下,分析型数据库MySQL版会为向量构建索引,索引会带来召回率的轻微下降,保证99%的数据召回率。您可以参考下表合理选择向量分析模式。
特点及场景 | 模式 | 数据召回率 | 数据量 | QPS |
小数据量(写入数据较少)、高QPS、精度无损。典型应用场景:
| 无损 | 100% | 百万级别 | 单节点100 QPS,利用维度表实现线性扩展。 |
中等规模数据量、高QPS、有较少精度损失。典型应用场景:
| 微损 | 99% | 亿级别 | 1000 QPS |
海量数据(写入较多)、低QPS、精度有损。典型应用场景: 历史库 | 微损 | 99% | 百亿级别 | 100 QPS |
结构化和非结构化混合检索
以检索与输入图片中的连衣裙相似度最高、价格在100元到200元之间且上架时间在最近1个月以内的产品为例,介绍结构化和非结构化混合检索。
有下列商品库,其中商品表products的字段如下所示。
字段 | 类型 | 说明 |
Id | Char(64) | 商品 |
Name | Varchar(256) | 商品名字 |
Price | Float | 价格 |
InTime | DateStamp | 入库时间 |
Url | Varchar(256) | 图片链接 |
Feature | Float(512) | 图片特征 |
向量检索SQL如下:
SelectId,Pricefrom ann
(SELECT *
FROM products
WHERE price >100
AND price <=200
AND InTime>‘2019-03-0100:00:00’
AND InTime<=‘2019-03-3100:00:00’,Feature,‘{1.0,2.0,…,512.0}’,100,'DISTANCE_THRESHOLD=0.2');其中ann为向量检索自定义函数,包含下列五个参数:
子查询:
SELECT * FROM products WHERE price >100 AND price <=200 AND InTime>‘2019-03-0100:00:00’ AND InTime<=‘2019-03-3100:00:00’;向量列名:
Feature查询向量:
‘{1.0,2.0,…,512.0}’Topk:100
参数列表:
DISTANCE_THRESHOLD=0.2,距离阈值为0.2。
数据实时更新
分析型数据库MySQL版向量分析支持数据实时更新,写入数据后可以立即进行查询。数据的写入方式与传统数据库一样,使用INSERT语句插入向量数据。写入性能可线性扩展,单个H8节点每秒可写入1000条记录。
向量分析碰撞
以上述商品库为例,为实现商品去重,需要检索最近一天加入的商品与上个月的商品库中有哪些商品是相似的。SQL如下所示。
SELECT A.id AS ida,
B.id AS idb from(select*from products
WHERE inTime >'2019-03-31 00:00:00') A
CROSS JOIN (SELECT * FROM products WHERE InTime>='2019-02-01 00:00:00' and InTime<'2019-02-29 00:00:00') B WHERE Vector_Distance(A.feature, B.feature,'DotProduct')>0.9SQL详解:
上述SQL把'2019-03-31 00:00:00'之后写入的数据与二月份的数据做笛卡尔积,把向量点积大于0.9的商品的对应ID提取出来。
易用性
向量分析完整继承了分析型数据库MySQL版的所有商业工具和生态,并支持常用的特征提取模型和第三方特征提取服务。
申请即可使用:开通分析型数据库MySQL版服务即可使用向量分析。
分析型数据库MySQL版全面兼容MySQL协议和SQL 2003,降低开发成本。
内置常用特征提取模块,支持集成第三方特征提取服务。
为了让您对非结构化数据拥有更多的自主控制权,您可以把非结构化数据保存在OSS或者图片服务器上(下图使用OSS),非结构化数据的保存地址即URL存储在分析型数据库MySQL版中,整体架构如下所示。
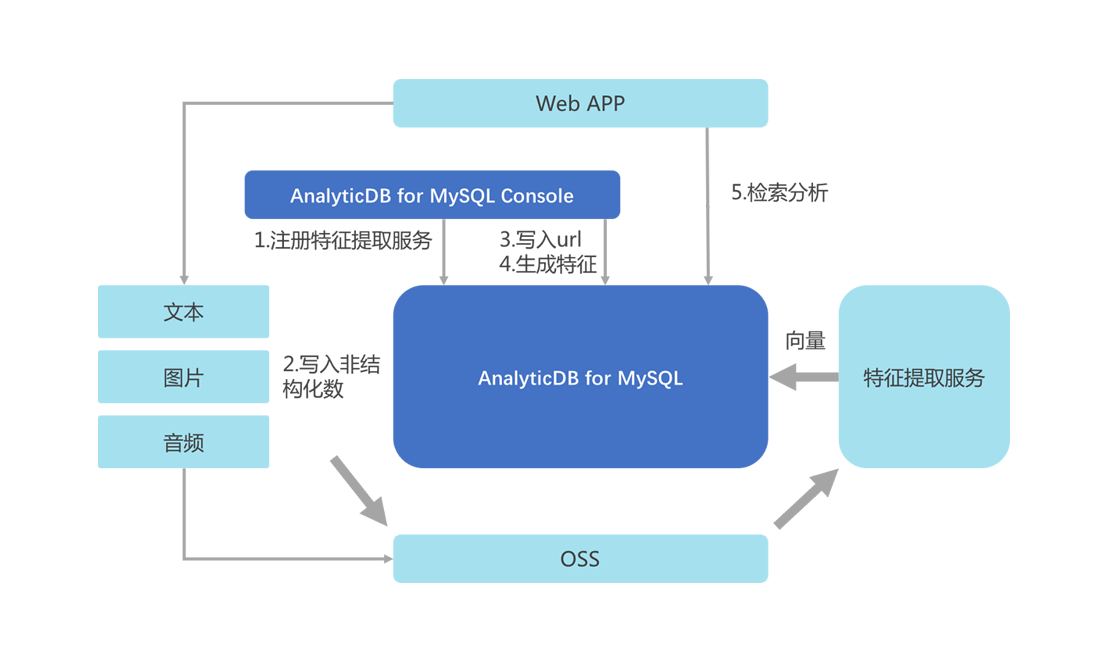
通过分析型数据库MySQL版控制台注册特征提取服务。
非结构化数据保存到OSS,同时返回访问的URL。
非结构化数据的存储地址即URL保存在分析型数据库MySQL版中。
通过Web App调用分析型数据库MySQL版的自定义函数生成向量特征,分析型数据库MySQL版后台通过调用特征提取服务从OSS读取非结构化数据,提取特征,并把特征向量保存在分析型数据库MySQL版中。所有这些操作只需要一条SQL便可轻松完成,SQL语句示例如下。
SELECT CLOTHES_FEATURE_EXTRACT_V1('https://xxx/1036684144_687583347.jpg'); INSERT INTO product(id, url, feature) VALUES (0, 'http://xxx/1036684144_687583347.jpg', CLOTHES_FEATURE_EXTRACT_V1(url));SQL详解:
CLOTHES_FEATURE_EXTRACT_V1为商品特征提取的自定义函数,传入商品图片URL,提取商品特征向量,该向量可以用来做商品检索和属性提取。对于常用的人脸特征提取、文本特征提取BERT模型以及服装特征提取也已经内置分析型数据库MySQL版服务中,您也可以使用您自己的特征提取服务。