

本文介绍如何将E-MapReduce HDFS上的数据迁移到文件存储 HDFS 版文件系统。
背景信息
阿里云E-MapReduce是构建在阿里云云服务器ECS上的开源Hadoop、Spark、Hive、Flink生态大数据PaaS产品。提供用户在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。
前提条件
已开通并创建E-MapRedece集群。具体操作,请参见创建集群。
说明当使用阿里云文件存储 HDFS 版替换E-MapReduce HDFS服务时,您可以选择使用高效云盘、SSD云盘或者本地盘作为Shuffle数据的临时本地存储。关于存储规划的更多信息,请参见存储说明。
已开通文件存储 HDFS 版服务,并创建文件系统实例、添加挂载点,创建权限组和权限组规则。具体操作,请参见文件存储HDFS版快速入门。
配置挂载点时选择的专有网络和交换机要与E-MapReduce集群侧的配置保持一致。您可以通过以下方法获取专有网络和交换机信息。
在集群管理页面,找到需要挂载文件存储 HDFS 版的目标E-MapReduce集群,单击管理。
单击集群基础信息,在网络信息区域中获取专有网络和交换机信息。
数据迁移
在集群管理页面,找到需要挂载文件存储 HDFS 版的目标E-MapReduce集群,单击管理。
配置链接。
选择,单击配置。
在服务配置中,选择core-site,并单击自定义配置。
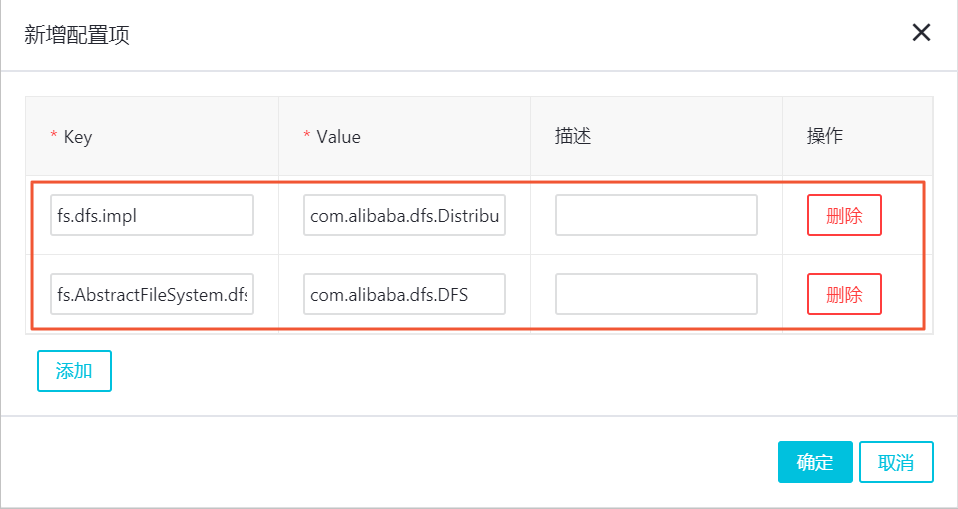
新增如下配置项,单击确定。
(必须配置)配置项fs.dfs.impl,其值为com.alibaba.dfs.DistributedFileSystem。
(必须配置)配置项fs.AbstractFileSystem.dfs.impl,其值为com.alibaba.dfs.DFS。
(可选)配置项io.file.buffer.size,其值为4194304。
(可选)配置项dfs.connection.count,其值为1。
确认自定义配置成功后,单击保存,在确认保存对话框中,输入执行原因,单击确定。
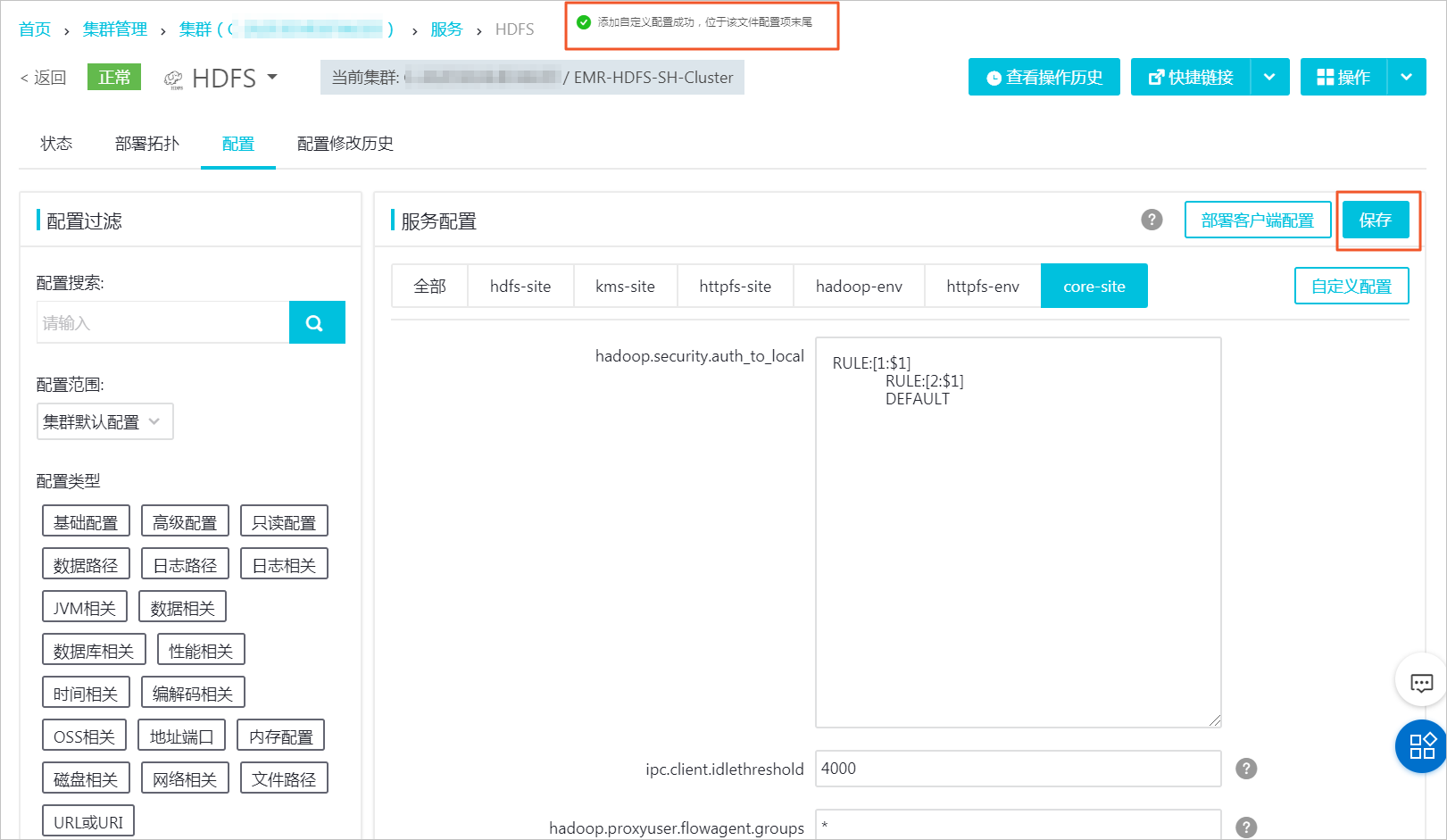
单击部署客户端配置,在确认保存对话框中,输入执行原因,单击确定。
执行以下命令将文件存储 HDFS 版最新的SDK包,放置到E-MapReduce HDFS服务存放jar包的路径下。更多信息,下载最新版本SDK安装包。
cp ~/aliyun-sdk-dfs-1.0.2-beta.jar /opt/apps/ecm/service/hadoop/2.8.5-1.3.1/package/hadoop-2.8.5-1.3.1/share/hadoop/hdfs/在E-MapReduce服务中,对应的路径为/opt/apps/ecm/service/hadoop/x.x.x-x.x.x/package/hadoop-x.x.x-x.x.x/share/hadoop/hdfs。
说明集群中的每台机器都需要在相同位置添加该SDK包。
暂停服务。
为了保证在数据迁移过程中数据不丢失,需要暂停数据处理服务(如:YARN服务、Hive服务、Spark服务、HBase服务等),HDFS服务仍需保持运行。此处以暂停Spark服务为例进行说明。
选择。
在页面右侧的操作栏中,单击停止All Components。
在执行集群操作对话框中,填写执行原因,并单击确定。
当组件前面的图标变成红色,表示该组件服务已停止。直到Spark服务运行的组件全部停止后,再进行其他服务的组件停止操作。无需关注xxx Client组件的状态。
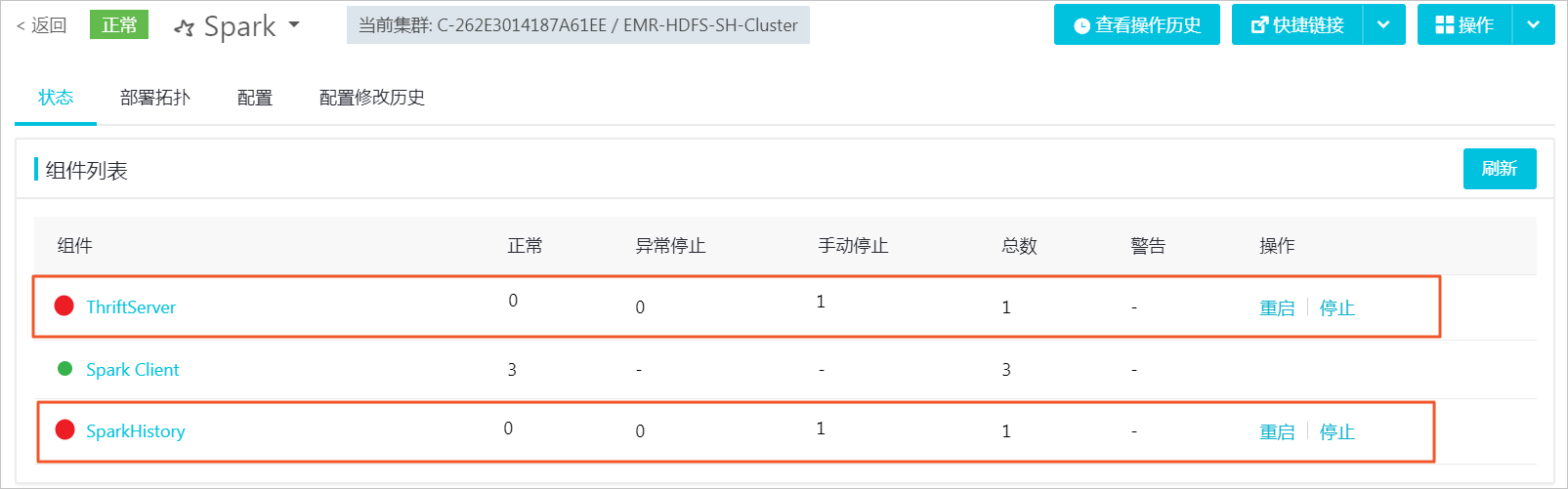
重复上述步骤,停止剩余服务。
说明只保留HDFS服务正常运行,以方便进行数据迁移。但是如果要迁移的数据量大,请开启YARN服务,以便使用hadoop的数据迁移工具hadoop distcp进行快速地数据迁移。
迁移数据。
建议将/user、/hbase、/spark-history、/apps等服务目录和相关的数据目录全量迁移至文件存储 HDFS 版。
如果涉及将云下集群的数据迁移到阿里云文件存储 HDFS 版文件系统,请参见迁移开源HDFS的数据到文件存储HDFS版。
如果E-MapReduce HDFS文件系统上的数据量较小,可以使用
hadoop fs -cp命令进行数据迁移。为了避免因为权限问题导致数据迁移失败,建议使用root用户执行命令。
hadoop fs -cp /user dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/其中
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点域名,请根据实际情况进行修改。如果E-MapReduce HDFS文件系统上的数据量较大,需要使用数据迁移工具hadoop distcp进行数据迁移。具体操作,请参见迁移开源HDFS的数据到文件存储HDFS版。
hadoop distcp hdfs://emr-header-1.cluster-xxxx:9000/ dfs://f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com:10290/其中
f-xxxxxxxxxxxxxxx.cn-xxxxxxx.dfs.aliyuncs.com为您的文件存储 HDFS 版挂载点域名,请根据实际情况进行修改。
后续步骤
- 本页导读 (1)