
本文介绍如何将E-MapReduce提供的分布式文件存储系统上的数据迁移到文件存储 HDFS 版文件系统。
背景信息
开源大数据开发平台E-MapReduce(简称EMR)是运行在阿里云平台上的一种大数据处理系统解决方案。EMR on ECS是指EMR在ECS上运行的方式。
您可以在文件存储 HDFS 版上使用EMR on ECS,利用文件存储 HDFS 版高吞吐、低延迟等特性,实现更高性能的大数据计算,应对灵活多变的业务需求的挑战。
前提条件
已开通并创建E-MapReduce集群,并同时满足以下条件。具体操作,请参见创建集群。
EMR集群的产品版本为EMR-3.XX.X系列。
EMR集群中安装的JDK版本为1.8或以上版本。
EMR集群中安装的Hadoop版本为2.7.2或以上版本。
已开通文件存储 HDFS 版服务,并创建文件系统实例、添加挂载点,创建权限组和权限组规则。具体操作,请参见文件存储HDFS版快速入门。
配置挂载点时选择的专有网络和交换机要与E-MapReduce集群侧的配置保持一致。您可以通过以下方法获取专有网络和交换机信息。
在顶部菜单栏,单击地域。
在概览页面,找到需要挂载文件存储 HDFS 版的目标E-MapReduce集群,单击节点管理。
单击目标节点组前的
 图标,展开节点组列表。
图标,展开节点组列表。单击目标节点ID,进入该节点的实例详情页面并在配置信息区域获取专有网络和虚拟交换机信息。
本文使用的EMR集群版本为EMR-3.51.0,业务场景为数据湖(DataLake)。
数据迁移
在顶部菜单栏,单击地域。
在概览页面,找到需要挂载文件存储 HDFS 版的目标E-MapReduce集群,单击集群服务。
暂停服务。
为了保证在数据迁移过程中数据不丢失,需要暂停数据处理服务(如:YARN服务、Hive服务、Spark服务等)。此处以暂停Spark3服务为例进行说明。
在集群服务页签,将光标移至Spark3卡片,选择
 图标>停止。
图标>停止。在弹出对话框填写执行原因,并单击确定。
当组件的健康状态图标变成黑色时,表示该组件服务已停止。直到Spark服务运行的组件全部停止后,再进行其他服务的组件停止操作。

重复上述步骤,停止剩余服务。
重要如果您的EMR集群使用的分布式文件存储系统是HDFS,请不要停止HDFS服务,否则无法迁移数据。
配置Hadoop-Common服务。
在集群服务页签,将光标移至Hadoop-Common卡片,单击配置。
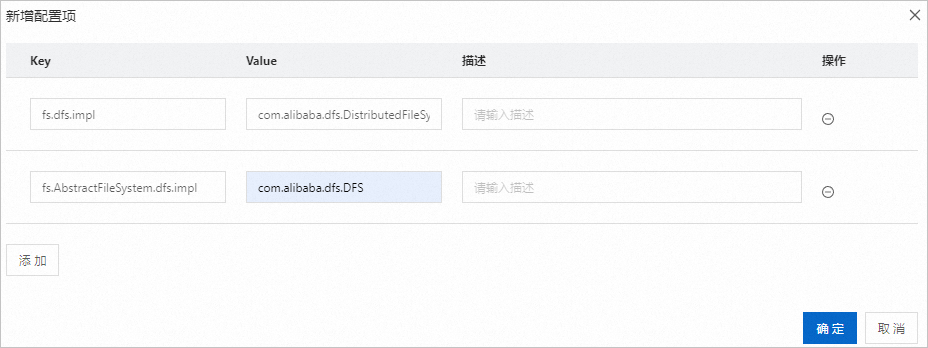
选择core-site.xml,并单击新增配置项。
新增如下配置项,单击确定。
配置项fs.dfs.impl,其值为com.alibaba.dfs.DistributedFileSystem。
配置项fs.AbstractFileSystem.dfs.impl,其值为com.alibaba.dfs.DFS。
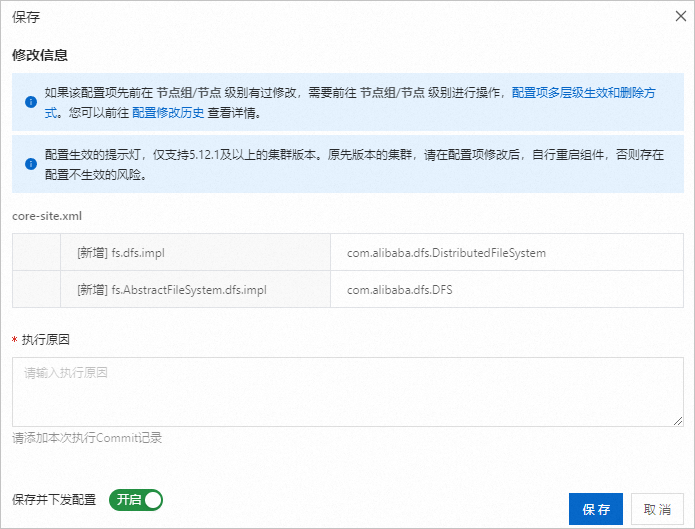
在保存对话中确认新增配置项信息并输入执行原因,然后单击保存。
单击部署客户端配置,输入执行原因,单击确定。
部署文件存储HDFS版的Java SDK。
将文件存储HDFS版的Java SDK放置到EMR集群各节点的Hadoop-Common服务HDFS依赖目录下。
# 请将aliyun-sdk-dfs-x.y.z.jar替换为您下载的文件存储HDFS版 Java SDK sudo cp aliyun-sdk-dfs-x.y.z.jar ${HADOOP_HOME}/share/hadoop/hdfs/说明集群中的每台机器都需要在相同位置添加该SDK包。
将文件存储HDFS版的Java SDK放置到EMR集群各节点的YARN服务HDFS依赖目录下。
# 请将aliyun-sdk-dfs-x.y.z.jar替换为您下载的文件存储HDFS版 Java SDK sudo cp aliyun-sdk-dfs-x.y.z.jar /opt/apps/YARN/yarn-current/share/hadoop/hdfs/ sudo chown hadoop:hadoop /opt/apps/YARN/yarn-current/share/hadoop/hdfs/aliyun-sdk-dfs-x.y.z.jar说明集群中的每台机器都需要在相同位置添加该SDK包。
配置用户和用户组的映射关系。
通过调用CreateUserGroupsMapping接口,分别为以下用户和用户组创建映射关系。
说明用户和用户组的映射功能目前还在邀测中,如需使用,请提交工单申请。
在文件存储 HDFS 版中supergroup为超级用户组,如果您使用其他服务时遇到权限问题,可以尝试创建相应用户与用户组supergroup的映射关系。
创建用户
emr-user与用户组emr-user、supergroup的映射关系。创建用户
admin与用户组admin、supergroup的映射关系。创建用户
hadoop、hdfs、hive、spark与用户组hadoop、supergroup的映射关系。
迁移数据。
建议将EMR on ECS上分布式文件系统中的所有业务数据全部迁移到文件存储 HDFS 版。
如果迁移的数据量较小,可以使用
hadoop fs -cp命令进行数据迁移。# 请将xxx://xxxx.xxxxx.xxx/*替换为原数据路径。 # 请将f-095d7371d****.cn-****.dfs.aliyuncs.com替换为您的文件存储HDFS版挂载点域名。 hadoop fs -cp -p xxx://xxxx.xxxxx.xxx/* dfs://f-095d7371d****.cn-****.dfs.aliyuncs.com:10290/如果迁移的数据量较大,可以使用数据迁移工具Hadoop DistCp。
启动YARN服务。
使用Hadoop DistCp迁移数据。
# 请将xxx://xxxx.xxxxx.xxx/*替换为原数据路径。 # 请将f-095d7371d****.cn-****.dfs.aliyuncs.com替换为您的文件存储HDFS版挂载点域名。 hadoop distcp -pugpt xxx://xxxx.xxxxx.xxx/* dfs://f-095d7371d****.cn-****.dfs.aliyuncs.com:10290/
迁移成功后,可以执行
hadoop fs -ls dfs://f-095d7371d****.cn-****.dfs.aliyuncs.com:10290/验证数据是否已迁移至文件存储HDFS版文件系统中。