简介
Spark ThriftServer是一个JDBC接口,用户可以通过JDBC连接ThriftServer来访问Spark SQL的数据。连接后可以直接通过编写SQL语句访问Spark SQL的数据。
购买Spark集群后,Spark ThriftServer会作为默认服务自动启动且长期运行。可通过如下方式查看启动的ThriftServer服务:
打开Spark集群详细页面进入:“数据库连接” > “UI访问” > “引擎软件UI” > “YARN”。进入YARN界面后点击“RUNNING”可查看到ThriftServer,如下图: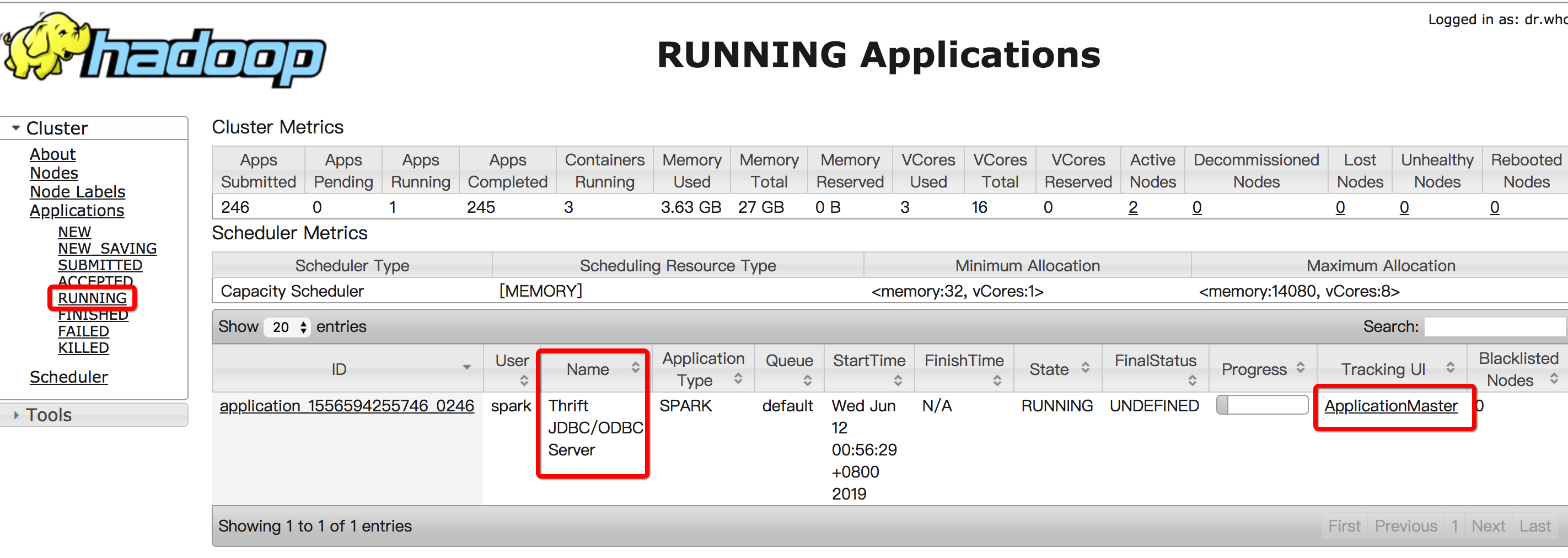 点击最右边的“ApplicationMaster”可以进入Spark Jobs页面,如下图:
点击最右边的“ApplicationMaster”可以进入Spark Jobs页面,如下图: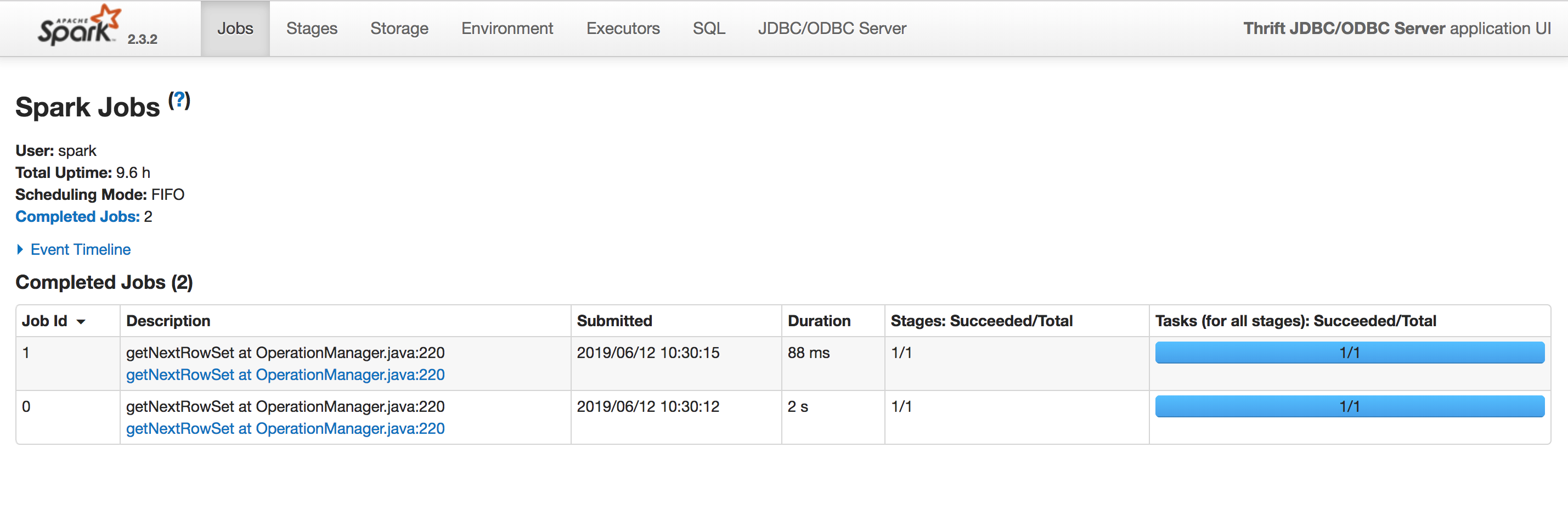 本文主要介绍如何通过ECS连接到Spark ThriftServer。
本文主要介绍如何通过ECS连接到Spark ThriftServer。
前置条件
- ECS和Spark集群网络打通。
- 通过命令行连接Spark ThriftServer需要购买一台和Spark集群同一个VPC下的ECS。Spark集群VPC信息查看方法:
进入Spark集群页面,进入“数据库连接” > “连接信息”,查看Spark集群的VPC ID信息。如下图: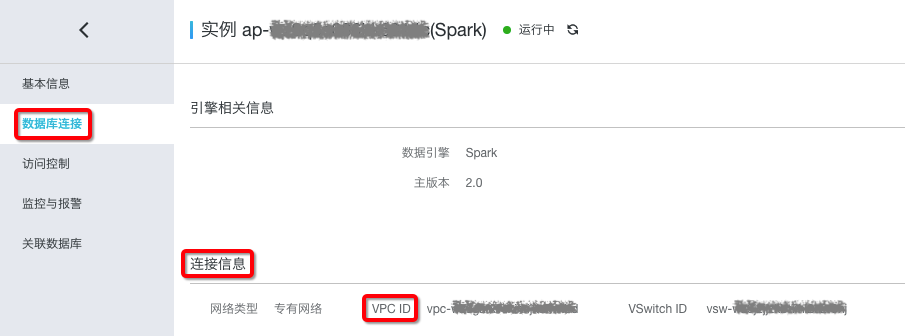
- 购买ECS后需要把ECS的内网IP地址加入到Spark的白名单中。
- ECS的安全组规则配置可以访问Spark集群的地址和端口。
- 通过命令行连接Spark ThriftServer需要购买一台和Spark集群同一个VPC下的ECS。Spark集群VPC信息查看方法:
使用命令行Beeline连接Spark ThriftServer
步骤 1:进入ECS机器下载Spark安装包进行部署、连接。
下载Spark安装包“spark-2.3.3-bin-hadoop2.7.tgz”到ECS机器,本例下载目录为:/opt/test/。
cd /opt/test/wget http://mirror.bit.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.7.tgz
解压安装包:
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz
解压后在命令行输入:
/opt/test/spark-2.3.3-bin-hadoop2.7/bin/beeline -u jdbc:hive2://ap-xxx-master2-001.spark.rds.aliyuncs.com:10000
其中:“jdbc:hive2://ap-xxx-master2-001.spark.rds.aliyuncs.com:10000” 为Spark ThriftServer的访问地址。获取方式:打开Spark集群详细页面进入:“数据库连接” > “连接信息”。 如下图: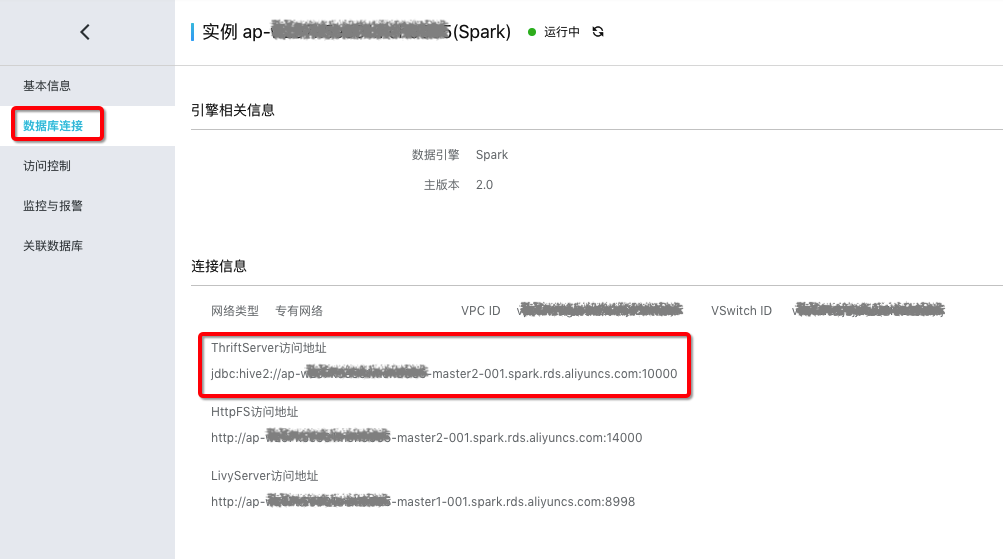
输入命令行看下如下信息说明连接ThriftServer成功:
步骤 2:通过Beenline编写SQL语句操作Spark SQL数据。
通过Beeline进入Spark ThriftServer后可在控制台直接编写SQL语句操作Spark SQL数据。例如:创建Spark parquet格式表,输入如下命令:
#使用parquet格式建表drop table if exists test_parquet;create table test_parquet(id int,name string,value double) using parquet;#插入数据insert into test_parquet values(1001, 'name1001', 95.49);insert into test_parquet values(1002, 'name1002', 73.25);insert into test_parquet values(1003, 'name1003', 25.65);insert into test_parquet values(1004, 'name1004', 23.39);insert into test_parquet values(1005, 'name1005', 8.64);insert into test_parquet values(1006, 'name1006', 52.60);insert into test_parquet values(1007, 'name1007', 42.16);insert into test_parquet values(1008, 'name1008', 85.39);insert into test_parquet values(1009, 'name1009', 7.22);insert into test_parquet values(1010, 'name1010', 10.43);#查询数据select * from test_parquet where id = 1003;select sum(value) from test_parquet;#使用parquet格式+分区建表drop table if exists test_parquet_pt;create table test_parquet_pt(dt date,id int,name string,value double) using parquetpartitioned by(dt);#插入数据insert into test_parquet_pt values(1001, 'name_pt_1001', 55.85, '2019-01-02');insert into test_parquet_pt values(1002, 'name_pt_1002', 71.71, '2019-01-02');insert into test_parquet_pt values(1003, 'name_pt_1003', 19.58, '2019-01-02');insert into test_parquet_pt values(1004, 'name_pt_1004', 53.50, '2019-01-02');insert into test_parquet_pt values(1005, 'name_pt_1005', 24.11, '2019-01-03');insert into test_parquet_pt values(1006, 'name_pt_1006', 79.21, '2019-01-03');insert into test_parquet_pt values(1007, 'name_pt_1007', 2.20 , '2019-01-03');insert into test_parquet_pt values(1008, 'name_pt_1008', 90.78, '2019-01-03');insert into test_parquet_pt values(1009, 'name_pt_1009', 30.34, '2019-01-03');insert into test_parquet_pt values(1010, 'name_pt_1010', 33.60, '2019-01-03');#查询数据select * from test_parquet_pt where dt = '2019-01-02';select avg(value) from test_parquet_pt;#多表joinselect * from test_parquet t1 join test_parquet_pt t2 on t1.id = t2.id;
SQL的运行明细、性能分析可以进入Spark Jobs页面进行查看,如下图: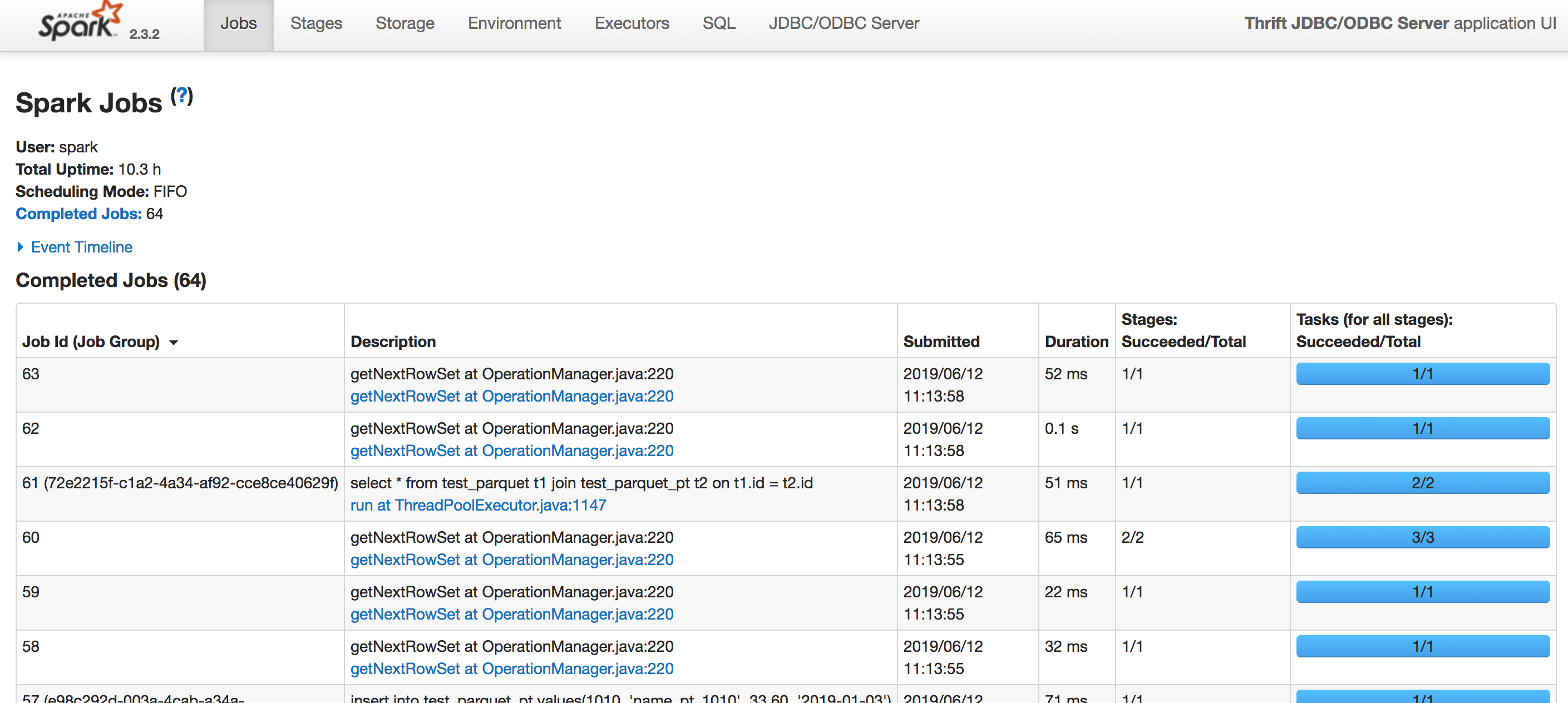
Spark Jobs页面可以查看每个SQL的运行明细,包括SQL的DAG、启动了多少Task,每个Task的运行时间等信息,方便对SQL语句运行性能的分析。
小结
- 本实例列举通过Beenline连接ThriftServer的操作SQL的基本方法,Spark也提供了数据工作台方便用户提交Spark 任务。使用可参考:数据工作台。
- 本页导读 (1)