
重要
由于开源HBase API的一些限制,使用HBase API兼容的二级索引存在一系列限制和问题,因此该功能不再维护,不推荐新用户使用。欢迎大家通过Lindorm SQL使用二级索引,相关内容请参见二级索引。
二级索引简介
HBase原生提供了主键索引,即按Rowkey的二进制排序的索引。Scan可基于此Rowkey索引高效的执行整行匹配、前缀匹配、范围查询等操作。但若需要使用Rowkey之外的列进行查询,则只能使用filter在指定的Rowkey范围内进行逐行过滤。若无法指定Rowkey范围,则需进行全表扫描,不仅浪费大量资源,查询RT也无法保证。
有多种解决方案可解决HBase的多维查询的问题。例如以要查询的列再单独写一张表(用户自己维护二级索引),或者将数据导出到Solr或者ES这样的外部系统进行索引。
Solr/ES固然强大,但对于大部分列较少且有固定查询模式的场景来说,有”杀鸡用牛刀”之感。为此,HBase增强版推出了原生的全局二级索引解决方案,以更低的成本解决此类问题。因内置于HBase,提供了强大的吞吐与性能。这个索引方案在阿里内部使用多年,经历了多次双11考验,尤其适合解决海量数据的全局索引场景。下图给出了HBase增强版与Phoenix在索引场景下的性能对比: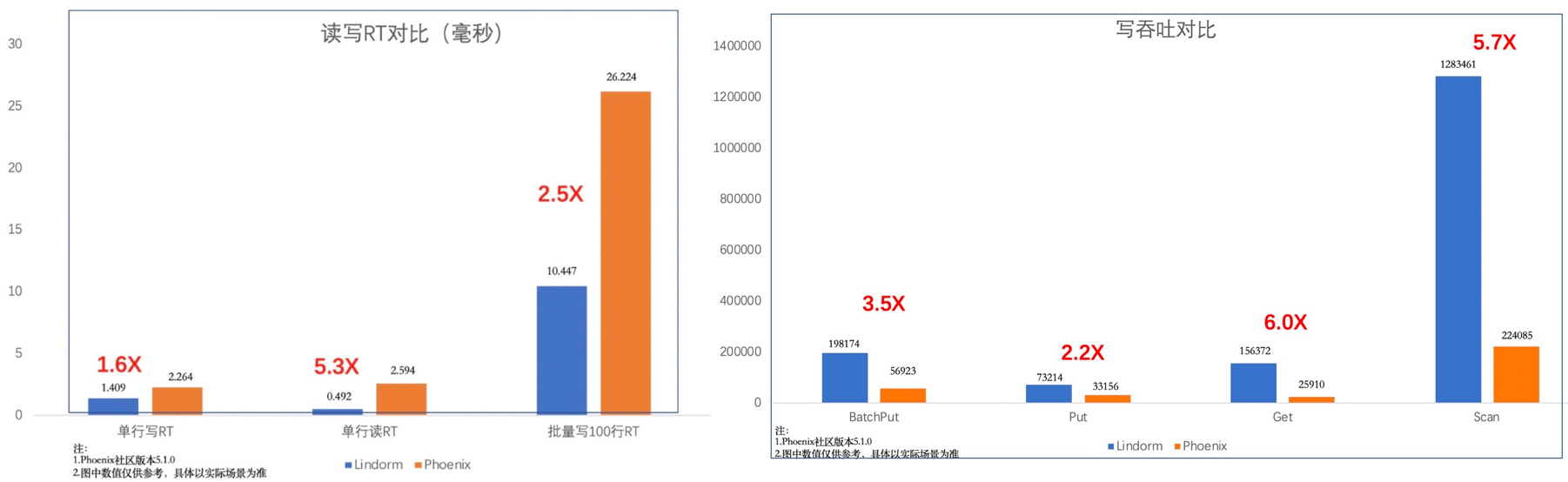
该文章对您有帮助吗?