Kafka插件基于Kafka SDK实时读取Kafka数据。
背景信息
说明
- 支持阿里云Kafka,以及>=0.10.2且<=2.2.x的自建Kafka版本。
- 对于<0.10.2版本Kafka,由于Kafka不支持检索分区数据offset,且Kafka数据结构可能不支持时间戳,因此会引发同步任务延时统计错乱,造成无法正确重置同步位点。
操作步骤
进入数据开发页面。
登录DataWorks控制台。
在左侧导航栏,单击工作空间列表。
选择工作空间所在地域后,单击相应工作空间后的。
鼠标悬停至
 图标,单击。
图标,单击。 您也可以展开业务流程,右键单击目标业务流程,选择。
在新建节点对话框中,选择同步方式为单表(Topic)到单表(Topic)ETL,输入名称,并选择路径。
重要节点名称必须是大小写字母、中文、数字、下划线(_)以及英文句号(.),且不能超过128个字符。
单击确认。
- 在实时同步节点的编辑页面,鼠标单击并拖拽至编辑面板。
- 单击Kafka节点,在节点配置对话框中,配置各项参数。
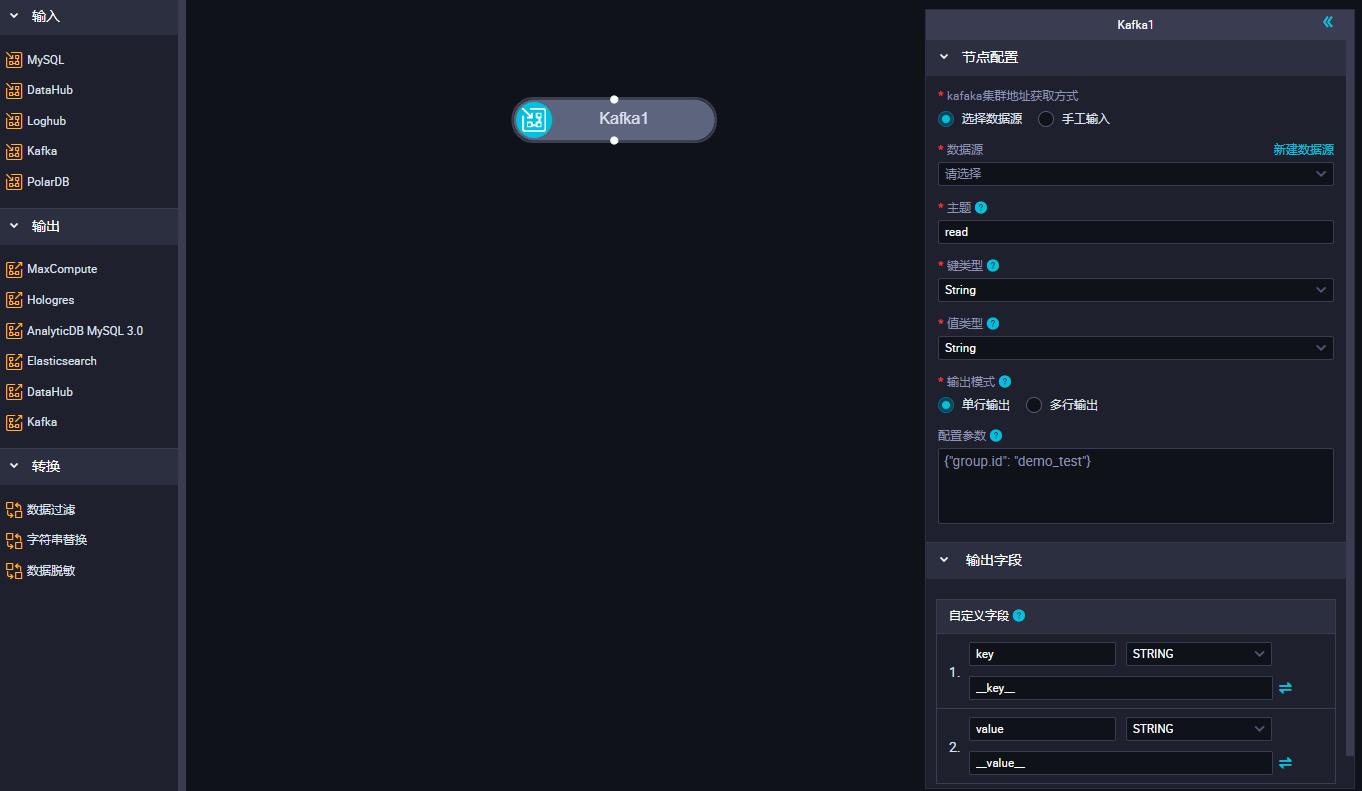
参数 描述 数据源 选择已经配置好的Kafka数据源,此处仅支持Kafka数据源。如果未配置数据源,请单击右侧的新建数据源,跳转至 页面进行新建。详情请参见:配置Kafka数据源。 主题 Kafka的Topic名称,是Kafka处理资源的消息源的不同分类。 每条发布至Kafka集群的消息都有一个类别,该类别被称为Topic,一个Topic是对一组消息的归纳。
说明 一个Kafka输入仅支持一个Topic。键类型 Kafka的Key的类型,决定了初始化KafkaConsumer时的key.deserializer配置,可选值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 值类型 Kafka的Value的类型,决定了初始化KafkaConsumer时的value.deserializer配置,可选值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 输出模式 定义解析kafka记录的方式 - 单行输出:以无结构字符串或者JSON对象解析kafka记录,一个kafka记录解析出一个输出记录。
- 多行输出:以JSON数组解析kafka记录,一个JSON数组元素解析出一个输出记录,因而一个kafka记录可能解析出多个输出记录。
说明 目前只在部分地域支持该配置项,如发现无该配置项请耐心等待功能在对应地域发布。数组所在位置路径 当输出模式设置为多行输出时,指定JSON数组在kafka记录value中的路径,路径支持以 a.a1的格式引用特定JSON对象中的字段或者以a[0].a1的格式引用特定JSON数组中的字段,如果该配置项为空,则将整个kafka记录value作为一个JSON数组解析。注意解析的目标JSON数组必须是对象数组,例如
[{"a":"hello"},{"b":"world"}],不能是数值或字符串数组,例如["a","b"]。配置参数 创建Kafka数据消费客户端KafkaConsumer 可以指定扩展参数,例如,bootstrap.servers、auto.commit.interval.ms、session.timeout.ms等,各版本Kafka集群支持的KafkaConsumer 参数可以参考Kafka官方文档,您可以基于kafkaConfig控制KafkaConsumer读取数据的行为。实时同步Kafka输入节点,KafkaConsumer默认使用随机字符串设置 group.id,如果希望同步位点上传到Kafka集群指定群组,可以在配置参数中手动指定group.id。实时同步Kafka输入节点不依赖Kafka服务端维护的群组信息管理位点,所以对配置参数中group.id的设置不会影响同步任务启动、重启、Failover等场景下的读取位点。输出字段 您可以自定义Kafka数据对外输出的字段名: - 单击添加更多字段,输入字段名,并选择类型,即可新增自定义字段。取值方式支持从kafka记录中取得字段值的方式,单击右侧
 按钮可以在两类取值方式间切换。
按钮可以在两类取值方式间切换。- 预置取值方式:提供6种可选预置从kafka记录中取值的方式:
- value:消息体
- key:消息键
- partition:分区号
- offset:偏移量
- timestamp:消息的毫秒时间戳
- headers:消息头
- JSON解析取值:可以通过.(获取子字段)和[](获取数组元素)两种语法,获取复杂JSON格式的内容,同时为了兼容历史逻辑,支持在选择JSON解析取值时使用例如__value__这样以两个下划线开头的字符串获取kafka记录的特定内容作为字段值。Kafka的数据示例如下。
{ "a": { "a1": "hello" }, "b": "world", "c":[ "xxxxxxx", "yyyyyyy" ], "d":[ { "AA":"this", "BB":"is_data" }, { "AA":"that", "BB":"is_also_data" } ] }- 不同情况下,输出字段的取值为:
- 如果同步kafka记录value,取值方式填写__value__。
- 如果同步kafka记录key,取值方式填写__key__。
- 如果同步kafka记录partition,取值方式填写__partition__。
- 如果同步kafka记录offset,取值方式填写__offset__。
- 如果同步kafka记录timestamp,取值方式填写__timestamp__。
- 如果同步kafka记录headers,取值方式填写__headers__。
- 如果同步a1的数据"hello",取值方式填写a.a1。
- 如果同步b的数据"world,取值方式填写b。
- 如果同步c的数据"yyyyyyy",取值方式填写c[1]。
- 如果同步AA的数据"this",取值方式填写d[0].AA。
- 不同情况下,输出字段的取值为:
- 预置取值方式:提供6种可选预置从kafka记录中取值的方式:
- 鼠标悬停至相应字段,单击显示的
 图标,即可删除该字段。
图标,即可删除该字段。
当数组所在位置路径填写{ "c": { "c0": [ { "AA": "this", "BB": "is_data" }, { "AA": "that", "BB": "is_also_data" } ] } }c.c0,输出字段定义两个字段,一个字段名为AA,取值方式为AA,一个字段名为BB,取值方式为BB,那么该条Kafka记录将解析得到如下两条记录:
- 单击工具栏中的
 图标。说明 一个Kafka输入仅支持一个Topic。
图标。说明 一个Kafka输入仅支持一个Topic。
反馈
- 本页导读 (1)
文档反馈