Kafka输出节点只需要选择表,进行字段映射即可完成配置。
前提条件
配置Kafka输出节点前,您需要先配置好相应的输入或转换数据源,实时同步支持的数据源。
背景信息
写入数据不支持去重,即如果任务重置位点或者Failover后再启动,会导致有重复数据写入。
操作步骤
登录DataWorks控制台,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
鼠标悬停至
 图标,单击。
图标,单击。 您也可以展开业务流程,右键单击目标业务流程,选择。
在新建节点对话框中,选择同步方式为单表(Topic)到单表(Topic)ETL,输入名称,并选择路径。
重要节点名称必须是大小写字母、中文、数字、下划线(_)以及英文句号(.),且不能超过128个字符。
单击确认。
在实时同步节点的编辑页面,鼠标单击并拖拽至编辑面板,连线已配置好的输入或转换节点。
单击Kafka节点,在节点配置对话框中,配置各项参数。
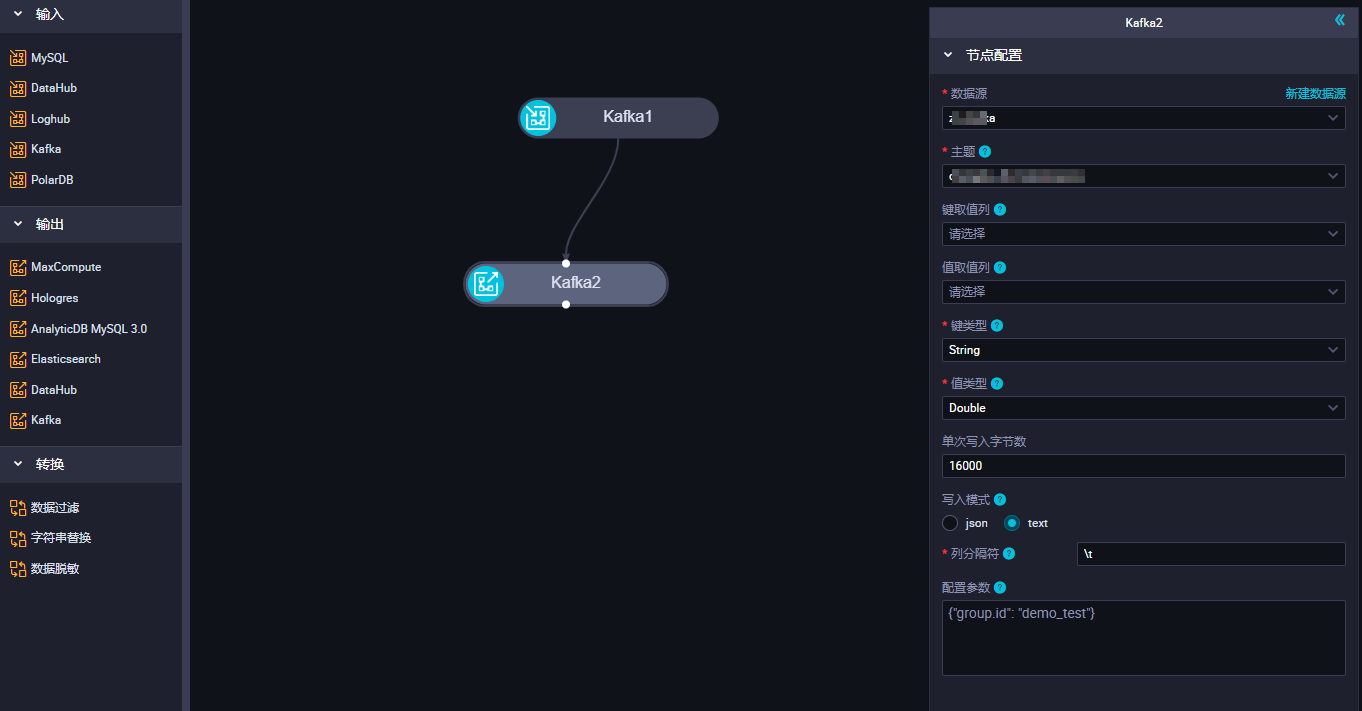
参数
描述
数据源
选择已经配置好的Kafka数据源,此处仅支持Kafka数据源。如果未配置数据源,请单击右侧的新建数据源,跳转至 页面进行新建。详情请参见:配置Kafka数据源。
主题
Kafka的Topic名称,是Kafka处理资源的消息源(feeds of messages)的不同分类。
每条发布至Kafka集群的消息都有一个类别,该类别被称为Topic,一个Topic是对一组消息的归纳。
说明一个Kafka输入仅支持一个Topic。
键取值列
指定哪些源端列的值拼接后作为Kafka记录Key,如果选择多列,使用逗号作为分隔符拼接列值。如果不选,则Key为空。
值取值列
指定哪些源端列的值拼接后作为Kafka记录Value。如果不填写,默认将所有列拼起来作为Value。拼接方式取决于选择的写入模式,详情请参见:Kafka Writer的参数说明。
键类型
Kafka的Key的类型,决定了初始化KafkaProducer时的key.serializer配置,可选值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。
值类型
Kafka的Value的类型,决定了初始化KafkaProducer时的value.serializer配置,可选值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。
单次写入字节数
一次写入请求包含的字节数,建议设置大于16000。
写入模式
该配置项决定将源端列拼接作为写入Kafka记录Value的格式,可选值为text和JSON。
配置为text,将所有列按照列分隔符进行拼接。
配置为JSON,将所有列拼接为JSON字符串。
例如,列配置为col1、col2和col3,源端某记录这三列的值为a、b和c,写入模式配置为text、列分隔符配置为
#时,对应写入Kafka的记录Value为字符串a#b#c;写入模式配置为JSON时,写入Kafka的记录Value为字符串{"col1":"a","col2":"b","col3":"c"}。列分隔符
当写入模式配置为text,将源端列按照该配置项指定列分隔符拼接作为写入Kafka记录的Value,支持配置单个或者多个字符作为分隔符,支持以
\u0001格式配置unicode字符,支持\t、\n等转义字符。默认值为\t。配置参数
创建Kafka数据消费客户端KafkaConsumer可以指定扩展参数,例如bootstrap.servers、acks、linger.ms等,您可以基于kafkaConfig控制KafkaConsumer消费数据的行为。实时同步Kafka输出节点,KafkaConsumer的默认acks参数为all,如果对性能有更高要求可以在配置参数中指定acks覆盖默认值。acks取值如下:
0:不进行写入成功确认。
1:确认主副本写入成功。
all:确认所有副本写入成功。
单击工具栏中的
 图标。
图标。
- 本页导读 (1)