
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍基于reindex将阿里云Elasticsearch 5.x实例中的多type数据,迁移到高版本Elasticsearch 6.x实例的单type索引中。
注意事项
2020年10月阿里云ES进行了网络架构调整,新网络架构下的集群跨集群reindex需依赖Privatelink打通阿里云ES集群私网。您可以参见下表,依据您的业务场景选择解决方案进行处理。
2020年10月之前创建的ES集群属于旧网络架构,2020年10月及之后创建的ES集群属于新网络架构。
使用场景 | ES集群所处网络架构 | 解决方案 |
阿里云ES集群间的数据迁移 | 两个ES集群均创建于旧网络架构下。 | reindex方式:阿里云ES间跨集群reindex。 |
其中一个ES集群创建于新网络架构下。 说明 另一个ES集群可以创建于新网络架构,也可以创建于旧网络架构。 |
| |
将ECS上自建的ES集群中的数据迁移至阿里云ES集群中 | 阿里云ES集群创建于旧网络架构下。 | reindex方式:通过reindex将自建ES数据迁移至阿里云。 |
阿里云ES集群创建于新网络架构下。 | reindex方式:通过实例私网打通将自建Elasticsearch数据迁移至阿里云。 |
操作流程
准备阿里云Elasticsearch和Logstash实例,确保两者在同一专有网络下。
阿里云Elasticsearch实例:存储索引数据。
阿里云Logstash实例:通过管道配置功能,迁移处理后的数据。
通过reindex,将阿里云Elasticsearch 5.x实例中的多type索引转换为单type索引。您可以通过以下两种方式来实现:
合并type方式:将Elasticsearch 5.x实例中的单索引多type数据,通过reindex script方式合并成一个单索引单type数据。
拆分type方式:将Elasticsearch 5.x实例中的单索引多type数据,按照不同的type,通过reindex拆分成多个单索引单type数据的方式。
使用阿里云Logstash,将处理后的索引数据迁移至高版本Elasticsearch 6.x实例中。
在Kibana中查看迁移成功的索引。
准备工作
准备低版本(5.5.3)和高版本(6.7.0)的阿里云Elasticsearch实例,并准备待迁移的多type数据。
创建实例的具体操作,请参见创建阿里云Elasticsearch实例。
创建阿里云Logstash实例,要求与阿里云Elasticsearch实例处于同一专有网络下。
具体操作,请参见步骤二:创建阿里云Logstash实例。
步骤一:转换索引类型
以下步骤介绍通过合并type方式,将单索引多type数据合并成一个单索引单type数据。
开启Elasticsearch实例的自动创建索引功能。
在左侧导航栏,单击Elasticsearch实例。
在顶部菜单栏处,选择资源组和地域。
在实例列表中,单击低版本的实例ID。
在左侧导航栏,单击ES集群配置。
单击YML文件配置右侧的修改配置。
在YML文件配置页面,设置自动创建索引为允许自动创建索引。
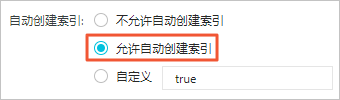 警告
警告修改自动创建索引方式会触发实例重启,请确认后再操作。
勾选该操作会重启实例,请确认后操作,单击确定。
登录低版本Elasticsearch实例的Kibana控制台。
具体操作,请参见登录Kibana控制台。
在左侧导航栏,单击Dev Tools(开发工具)。
在Console中,执行以下命令,将单索引多type数据合并成单索引单type数据。
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new1" }, "script": { "inline": """ ctx._id = ctx._type + "-" + ctx._id; ctx._source.type = ctx._type; ctx._type = "doc"; """, "lang": "painless" } }以上示例通过自定义type的方式,指定ctx._source.type在new1索引中添加type字段,将其设置为原始_type的值。并且new1索引的_id由_type-_id组成,防止存在不同类型的文档具有相同的ID而发生冲突的情况。
执行
GET new1/_mapping命令,查看合并后的Mapping结构。执行以下命令,查看合并后的索引数据。
GET new1/_search { "query":{ "match_all":{ } } }
以下步骤介绍通过拆分type方式,将单索引多type数据,按照不同的type,通过reindex拆分成多个单索引单type数据。
在Console中,执行以下命令,将单索引多type拆分单索引单type。
POST _reindex { "source": { "index": "twitter", "type": "tweet", "size": 10000 }, "dest": { "index": "twitter_tweet" } } POST _reindex { "source": { "index": "twitter", "type": "user", "size": 10000 }, "dest": { "index": "twitter_user" } }以上示例将twitter索引按照不同type,分别拆分成twitter_tweet和twitter_user索引。
执行以下命令,查看拆分后的索引数据。
GET twitter_tweet/_search { "query":{ "match_all":{ } } }GET twitter_user/_search { "query":{ "match_all":{ } } }
步骤二:通过Logstash迁移数据
- 进入阿里云Elasticsearch控制台的Logstash页面。
- 进入目标实例。
- 在顶部菜单栏处,选择地域。
- 在Logstash实例中单击目标实例ID。
在左侧导航栏,单击管道管理。
单击创建管道。
在创建管道任务页面,输入管道ID并配置管道。
本文使用的管道配置如下。
input { elasticsearch { hosts => ["http://es-cn-0pp1f1y5g000h****.elasticsearch.aliyuncs.com:9200"] user => "elastic" index => "*" password => "your_password" docinfo => true } } filter { } output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm000c****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "your_password" index => "test" } }管道配置参数详情,请参见Logstash配置文件说明。
单击下一步,配置管道参数。
参数
说明
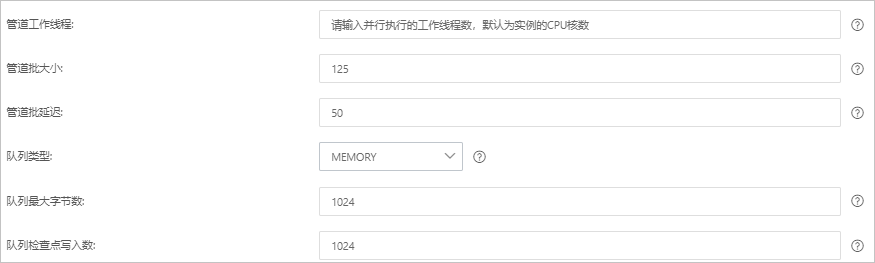
管道工作线程
并行执行管道的Filter和Output的工作线程数量。当事件出现积压或CPU未饱和时,请考虑增大线程数,更好地使用CPU处理能力。默认值:实例的CPU核数。
管道批大小
单个工作线程在尝试执行Filter和Output前,可以从Input收集的最大事件数目。较大的管道批大小可能会带来较大的内存开销。您可以设置LS_HEAP_SIZE变量,来增大JVM堆大小,从而有效使用该值。默认值:125。
管道批延迟
创建管道事件批时,将过小的批分派给管道工作线程之前,要等候每个事件的时长,单位为毫秒。默认值:50ms。
队列类型
用于事件缓冲的内部排队模型。可选值:
MEMORY:默认值。基于内存的传统队列。
PERSISTED:基于磁盘的ACKed队列(持久队列)。
队列最大字节数
队列允许存储的最大数据量,单位为
MB。取值范围为:1~253-1的整数,默认值为1024MB。说明请确保该值小于您的磁盘总容量。
队列检查点写入数
启用持久性队列时,在强制执行检查点之前已写入事件的最大数目。设置为0,表示无限制。默认值:1024。
警告配置完成后,需要保存并部署才能生效。保存并部署操作会触发实例重启,请在不影响业务的前提下,继续执行以下步骤。
单击保存或者保存并部署。
保存:将管道信息保存在Logstash里并触发实例变更,配置不会生效。保存后,系统会返回管道管理页面。可在管道列表区域,单击操作列下的立即部署,触发实例重启,使配置生效。
保存并部署:保存并且部署后,会触发实例重启,使配置生效。
步骤三:查看数据迁移结果
登录高版本Elasticsearch实例的Kibana控制台。
具体操作,请参见登录Kibana控制台。
在左侧导航栏,单击Dev Tools。
在Console中,执行以下命令,查看迁移成功的索引。
GET _cat/indices?v