
JindoCube在E-MapReduce 3.24.0及之后版本中可用。本文主要介绍E-MapReduce JindoCube的安装、部署和使用等。
前提条件
已创建表或者视图。
概述
JindoCube是E-MapReduce Spark支持的高级特性,通过预计算加速数据处理,实现十倍甚至百倍的性能提升。您可以将任意View表示的数据进行持久化,持久化的数据可以保存在HDFS或OSS等任意Spark支持的DataSource中。EMR Spark自动发现可用的已持久化数据,并优化执行计划,对用户完全透明。JindoCube主要用于查询模式相对比较固定的业务场景,通过提前设计JindoCube,对数据进行预计算和预组织,从而加速业务查询的速度,常见的使用场景包括MOLAP多维分析、报表生成、数据Dashboard和跨集群数据同步等。
JindoCube的安装与部署
JindoCube作为EMR Spark组件的高级特性,所有使用EMR Spark提交的Dataset、DataFrame API、SQL任务,均可以基于JindoCube进行加速,无须额外的组件部署与维护。
-
UI页面展示。
JindoCube主要通过Spark的UI页面进行管理,包括JindoCube的创建、删除和更新等。通过UI创建JindoCube完成后,即可自动用于该集群所有Spark任务的查询加速。通过spark.sql.cache.tab.display参数可以控制是否在Spark UI页面展示JindoCube的Tab,可以通过EMR控制台在Spark服务中配置相关参数,或者在Spark提交命令中指定参数值,该参数默认值为false。

JindoCube还提供了spark.sql.cache.useDatabase参数,可以针对业务方向,按不同的业务建立database,把需要建cache的view放在这个database中。对于分区表JindoCube还提供了spark.sql.cache.cacheByPartition参数,可指定cache使用分区字段进行存储。
参数
说明
示例值
spark.sql.cache.tab.display
显示Cube Managment页面。
true
spark.sql.cache.useDatabase
cube存储数据库。
db1,db2,dbn
spark.sql.cache.cacheByPartition
按照分区字段存储cube。
true
-
优化查询。
spark.sql.cache.queryRewrite用于控制是否允许使用JindoCube中的Cache数据加速Spark查询任务,用户可以在集群、session、SQL等层面使用该配置,默认值为true。
JindoCube的使用
-
创建JindoCube。
-
通过阿里云账号登录E-MapReduce控制台。
-
单击集群管理页签。
-
单击待操作集群所在行的集群ID。
-
单击左侧导航栏的访问链接与端口。
-
在公网访问链接页面,单击YARN UI所在行的链接,进入Knox代理的YARN UI页面。
Knox相关使用说明请参见Knox。
-
单击Name为Thrift JDBC/ODBC Server,Application Type为SPARK所在行的ApplicationMaster。
-
单击上方的Cube Management页签。
-
单击New Cache。
您可以选择某一个表或视图,单击action中的链接继续创建Cache。可以选择的Cache类型分为两类:
-
Raw Cache:某一个表或者视图的raw cache,表示将对应表或视图代表的表数据按照指定的方式持久化。
在创建Raw Cache时,需要指定如下信息:
参数
描述
是否必选
Cache Name
指定Cache的名字,支持字母、数字、连接号(–)和下划线(_)的组合。
必选
Column Selector
选择需要Cache哪些列的数据。
必选
Rewrite
是否允许该Cache被用作后续查询的执行计划优化。
必选
Provider
Cache数据的存储格式,支持JSON、PARQUET、ORC等所有Spark支持的数据格式。
必选
Partition Columns
Cache数据的分区字段。
可选
ZOrder Columns
ZOrder是一种支持多列排序的方法,Cache数据按照ZOrder字段排序后,对于基于ZOrder字段过滤的查询会有更好的加速效果。
可选
-
Cube Cache:基于某一个表或者视图的原始数据,按照用户指定的方式构建cube,并将cube数据持久化。
在创建Cube Cache时,用户需要指定如下信息:
参数
描述
是否必选
Cache Name
指定Cache的名字,支持字母、数字、连接号(–)和下划线(_)的组合。
必选
Dimension Selector
选择构建Cube时的维度字段。
必选
Measure Selector
选择构建Cube时的measure字段和measure预计算函数。
必选
Rewrite
是否允许该Cache被用作后续查询的执行计划优化。
必选
Provider
Cache数据的存储格式,支持JSON、PARQUET、ORC等所有Spark支持的数据格式。
必选
Partition Columns
Cache数据的分区字段。
可选
ZOrder Columns
ZOrder是一种支持多列排序的方法,Cache数据按照ZOrder字段排序后,对于基于ZOrder字段过滤的查询会有更好的加速效果。
可选
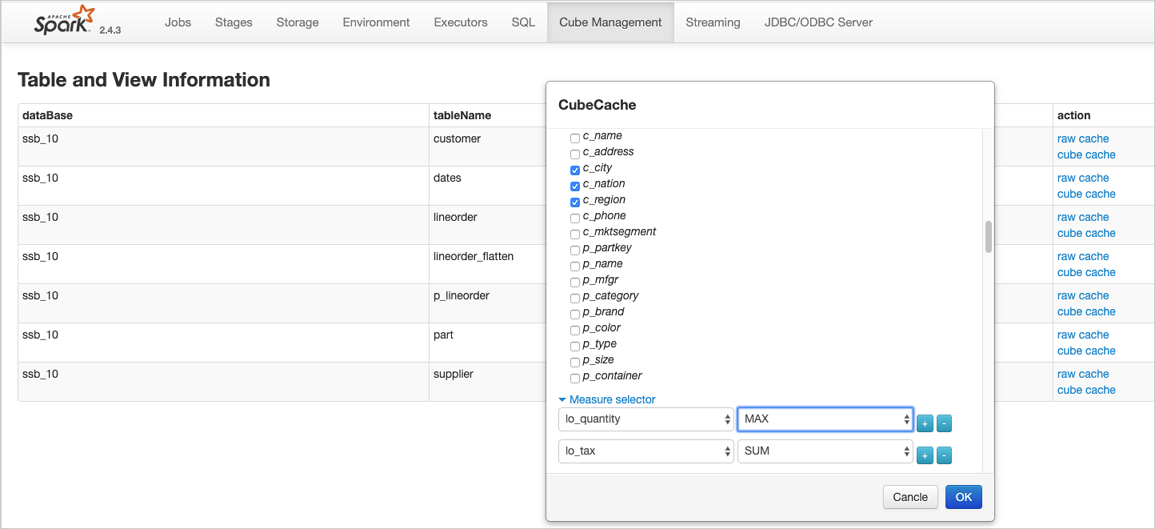
JindoCube通过用户指定的Dimension和Measure信息来构建Cube,对于上图的示例,创建的Cube Cache可以用SQL表示为:
SELECT c_city, c_nation, c_region, MAX(lo_quantity), SUM(lo_tax) FROM lineorder_flatten GROUP BY c_city, c_nation, c_region;JindoCube计算Cube的最细粒度维度组合,在优化使用更粗粒度的维度组合的查询时,基于Spark强大的现场计算能力,通过重聚合实现。在定义Cube Cache时,必须使用JindoCube支持的预计算函数。JindoCube支持的预计算函数和其对应的聚合函数类型如下:
聚合函数类型
预计算函数
COUNT
COUNT
SUM
SUM
MAX
MAX
MIN
MIN
AVG
COUNT,SUM
COUNT(DISTINCT )
PRE_COUNT_DISTINCT
APPROX_COUNT_DISTINCT
PRE_APPROX_COUNT_DISTINCT
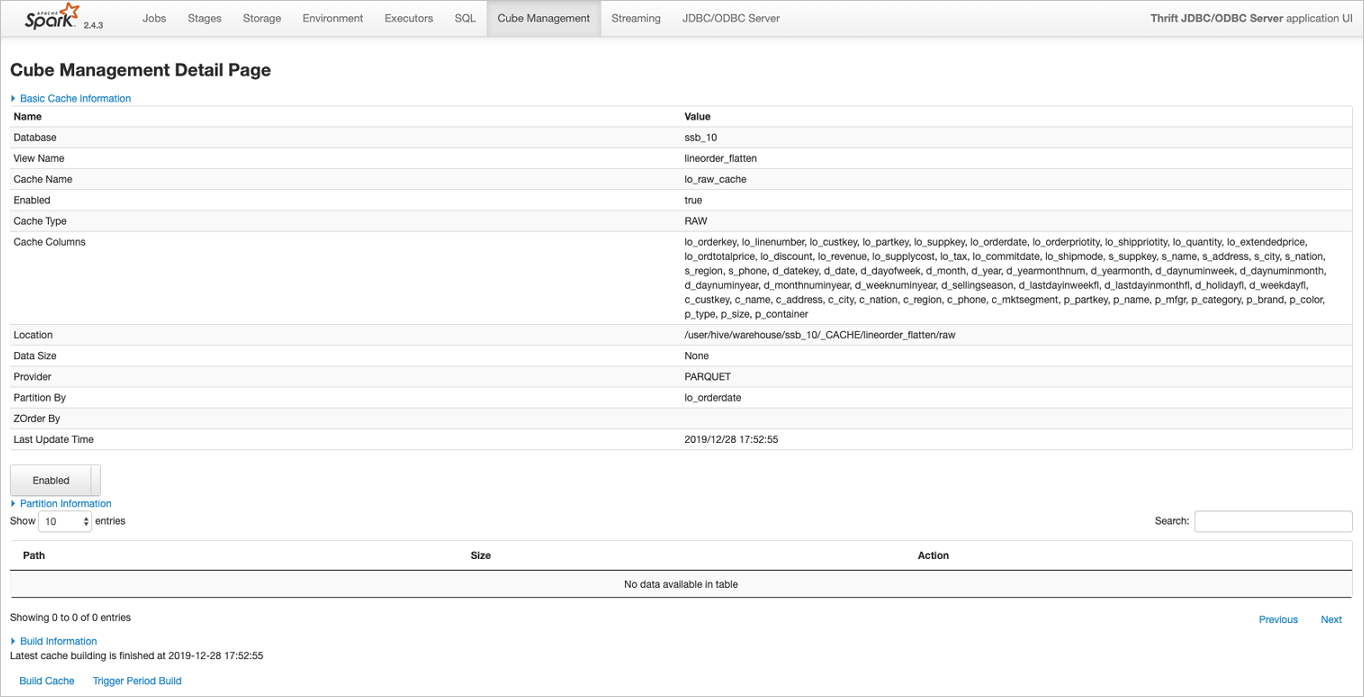
在Cube Management页面,展示所有的Cache列表。单击Detail进入Cache的详细页面,在Cache详细页会展示Cache的详细信息、包括基本信息、Cache数据分区信息、构建Cache信息以及构建历史信息等。
-
-
-
构建JindoCube。
创建JindoCube Cache只是进行元数据操作,Cache表示的数据并未持久化,需要继续构建Cache,从而持久化Cache数据到HDFS或OSS等存储中。此外Cache对应的源表数据可能会新增或者更新,需要更新Cache中的数据从而保持一致。JindoCube支持两类构建操作:
-
Build Cache。
通过Build Cache链接,用户可以主动触发一次构建操作,构建页面相关信息如下:
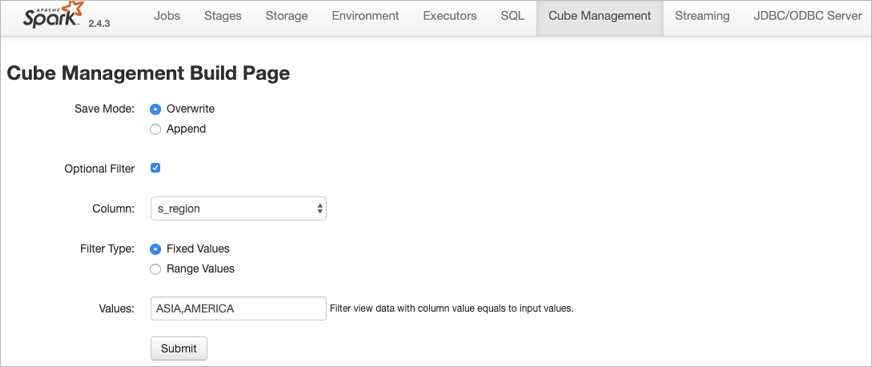
在构建JindoCube的Cache时,相关用户选项如下:
参数
描述
Save Mode
支持Overwrite和Append两种模式。
-
Overwrite:会覆盖之前曾经构建的Cache数据。
-
Append:会新增数据到Cache中。
Optional Filter
用户可以选择额外的过滤条件,在构建时,将该Cache表示的数据过滤后再持久化。
-
Column:过滤字段。
-
Filter Type:过滤类型,支持固定值和范围值两种。
-
Fixed Values:指定过滤值,可以多个,以“,”分隔。
-
Range Values:指定范围值的最小和最大值,最大值可以为空,过滤条件包含最小值,不包含最大值。
-
上图中构建任务想要构建lineorder_flatten视图的Raw Cache数据,要写入Cache中的数据可以使用如下SQL表示:
SELECT * FROM lineorder_flatten WHERE s_region == 'ASIA' OR s_region == 'AMERICA';单击Submit,提交构建任务,返回到Cache详细页面,对应的构建任务会提交到Spark集群中执行,在Build Information中可以看到当前是否正在构建Cache的信息。在Cache构建完成后,可以在Build History中看到相关的信息。
说明Cache数据由Spark任务写到一个指定目录中,和普通的Spark写表或者写目录一样,对于Parquet、Json、ORC等数据格式,并发构建同一个Cache可能导致Cache数据不准确,不可用,应避免这种情况。如果无法避免并发构建、更新Cache,可以考虑使用delta等支持并发写的数据格式。
-
-
Trigger Period Build。
定期更新功能可以方便用户设置自动更新Cache的策略,保持Cache数据和源表数据的一致。相关页面如下:
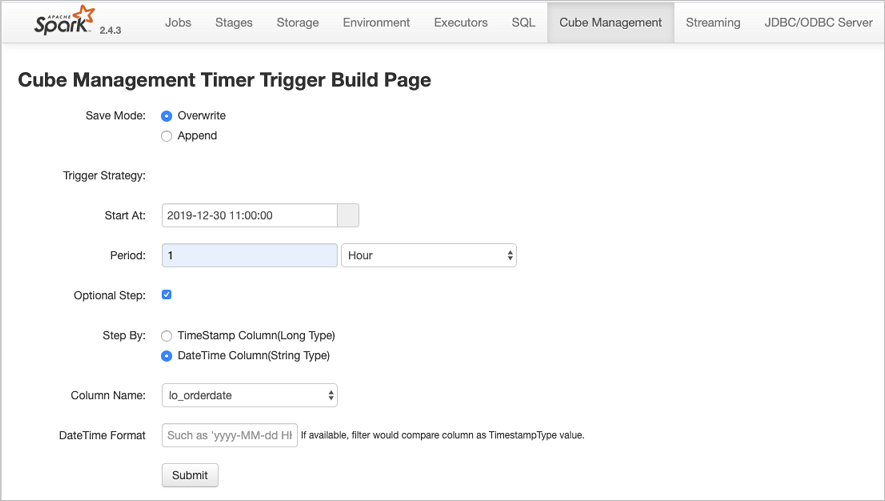
定期更新的相关用户选项如下:
参数
描述
Save Mode
支持Overwrite和Append两种模式。
-
Overwrite:会覆盖之前曾经构建的Cache数据。
-
Append:会新增数据到Cache中。
Trigger Strategy
触发策略,设置触发构建任务的开始时间和间隔时间。
-
Start At:通过时间控件选择或者手工输入第一次触发构建任务的时间点,日期格式为yyyy-MM-dd hh:mm:ss。
-
Period:设置触发构建任务的间隔时间。
Optional Step
设置每次触发构建任务的数据筛选条件,通过指定时间类型的字段,配合触发策略中的间隔时间,可以实现按照时间间隔增量的更新Cache。如果不选择,每次全量更新Cache。
-
Step By:选择增量更新字段类型,只支持时间类型字段,包括Long类型的timestamp字段,以及指定dateformat信息的String类型字段。
-
Column Name:增量更新字段名称。
在Cache详细页面中,可以看到当前设置的定期更新策略,用户可以随时通过Cancel Period Build取消定期更新。所有触发的构建任务信息在完成后也可以在Build History列表中看到。
说明-
定期更新任务是Spark集群级别的,相关设置保存在SparkContext中,并由Spark Driver定期触发,当Spark集群关闭后,定期更新任务也随之关闭。
-
当前Spark集群所有的构建任务完成后,都会展示在Build History列表中,包含开始/结束时间、SaveMode、构建条件,任务最终状态等。Build History也是Spark集群级别的信息,当Spark集群关闭后,相关信息也随之释放。
-
-
-
管理JindoCube。
创建和构建JindoCube的Cache数据后,通过Cube Management的UI页面,可以对JindoCube的Cache数据进行进一步的管理。
-
删除cache。
在JindoCube Cache列表页面,可以通过action列的Drop删除对应Cache,删除成功后,Cache的相关元数据和存储数据都会被清理。

-
开启或关闭Cache优化。
JindoCube支持在Cache级别,设置是否允许用于Spark查询的优化,在Cache的详细页面,您可以通过基本信息中的Enabled或Disabled,启用或者停用该Cache,控制是否允许该Cache用于查询加速。

-
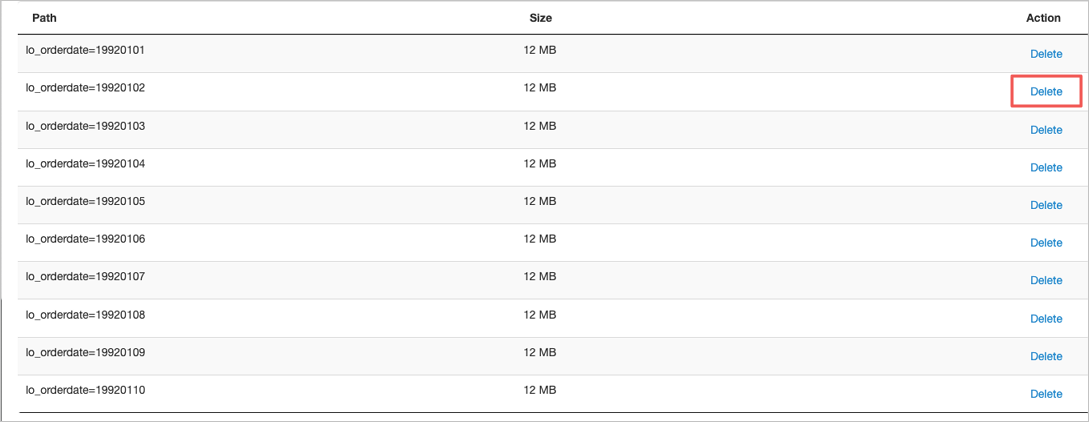
删除分区数据。
如果Cache的数据是按照分区存储的,当确认某些分区数据不再需要时,删除这些分区数据可以节省大量存储空间。在Cache的详细页面,分区Cache的相关分区会通过列表展示,用户可以通过Delete删除特定分区的数据。
说明在删除Cache分区数据之前,请谨慎确认,确保该分区数据不会被使用。如果用户的查询经过优化需要用到该Cache被删除的分区数据,会导致错误的查询结果。
-
-
查询优化。
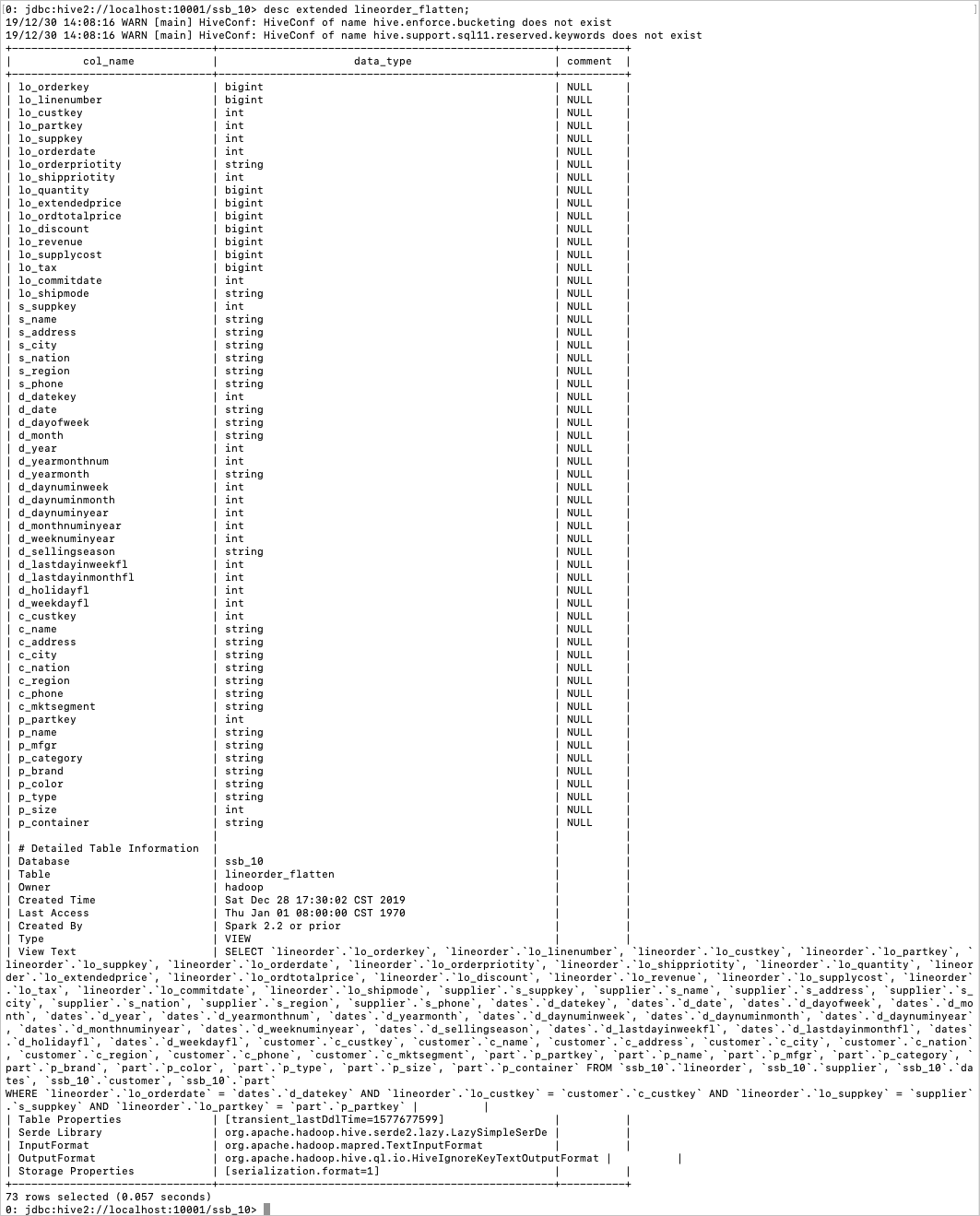
目前JindoCube支持基于View的查询优化,当用户使用某个视图创建了Raw Cache或者Cube Cache后,后续的查询使用到了该视图,EMR Spark会在满足逻辑语义的前提下,尝试使用Cache重写查询的执行计划,新的执行计划直接访问Cache数据,从而加速查询速度。以如下场景为例,lineorder_flatten视图是将lineorder和其他维度表关联之后的大宽表视图,其相关定义如下:
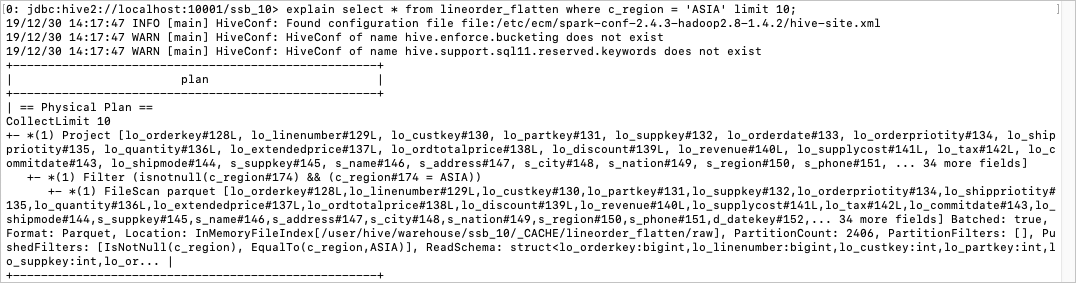
基于lineorder_flatten视图简单查询的执行计划如下:
在为line order_flatten视图创建Raw Cache并构建完成后,执行相同查询,EMR Spark会自动使用Cache数据优化执行计划,优化后的执行计划如下:
可以看到,优化后的执行计划省去了lineorder_flatten视图的所有计算逻辑,直接访问HDFS中Cache的数据。

注意事项
-
JindoCube并不保证Cache数据和源表数据的一致性,而是需要用户通过手工触发或者设置定期策略触发更新任务同步Cache中的数据,用户需要根据查询对于数据一致性的需求,触发Cache的更新任务。
-
在对查询的执行计划进行优化的时候,JindoCube根据视图的元数据判断是否可以使用Cache优化查询的执行计划。优化后,如果Cache的数据不完整,可能会影响查询结果的完整性或正确性。可能导致Cache数据不完整的情况包括:用户在Cache详情页主动删除查询需要的Cache Partition数据,构建、更新Cache时指定的过滤条件过滤掉了查询需要的数据,查询需要的数据还未及时更新到Cache等。