超级计算集群结合ACK实现NLP训练
更新时间:
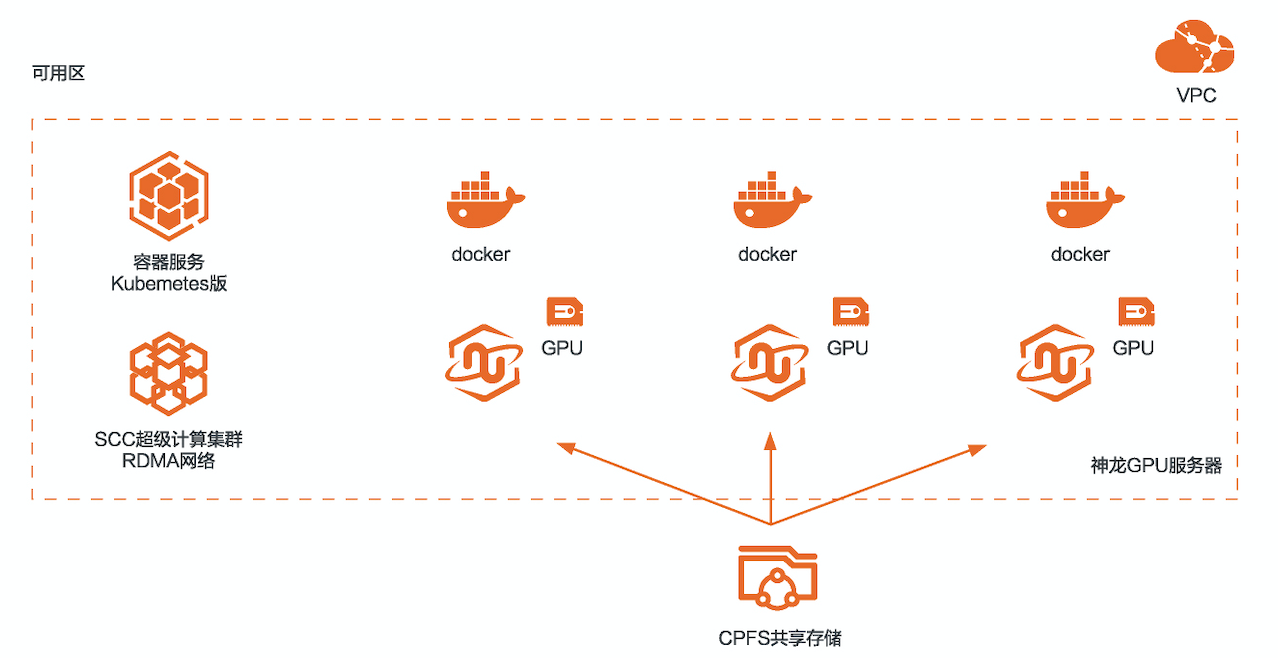
使用裸金属GPU服务器、RDMA网络、CPFS和Perseus框架搭建容器化NLP训练环境。
直达最佳实践
场景描述
本方案适用于自然语言处理的训练场景,使用神龙GPU云服务器(SCCGN6)+CPFS+容器服务Kubernetes版(ACK)进行NLP的训练,采用Bert模型,使用飞天AI加速训练工具可以有效提升多机多卡的训练效率。
解决的问题
- 使用神龙+ACK搭建NLP训练环境
- 使用SCC的RDMA网络
- 使用CPFS存储训练数据
- 使用飞天AI加速训练工具加速训练
部署架构图
反馈
- 本页导读
文档反馈