案例背景
小打卡目前已为3000万用户提供体验服务3.4亿人次,内容消费7.4亿人次。在庞大的用户量背后,MaxCompute产品的搭建显得尤为重要。
为什么选择阿里云
小打卡致力于帮助用户成为更好的自己。目前,已为3000万用户提供体验服务3.4亿人次,内容消费7.4亿人次。 在小打卡上线初期,业务分析所需的数据主要是通过查询mysql库表。
现在,小打卡的主要业务分析需求,包括业务报表,用户行为分析,A/B/n实验评估,个性化推荐,数据服务等全部是借助于阿里云的大数据平台来满足。 选择阿里云大数据产品的原因:
- 成本低:享用阿里云超大规模的云计算资源,按照实际需要采购存储和计算资源。 企业无需组建专门的大数据平台部署和运维团队,在业务发展初期,极大的降低了拥有大数据平台的各项成本。
- 效率高:企业通过阿里云官网了解并采购所需的大数据产品,快速搭建适合业务的平台架构。 阿里云大数据提供开发生产环境隔离的集成开发环境,以及完善的调度/监控/数据管理等工具能力,提高数据仓库的开发效率。企业可以快速构建大数据平台的功能模块,快速相应业务需求。
- 性能按需采购:阿里云大数据的I/O 及计算能力弹性伸缩,可以支持TB/PB/EB 级数据规模, 千万级别复杂任务调度和万兆的网络同步速率。
- 安全:阿里云大数据提供云上数据的安全,以及企业租户之间的安全隔离,大数据项目不同角色的权限管理和各种数据资源的权限管理。
系统架构
小打卡基于阿里云大数据产品实现的离线数仓架构: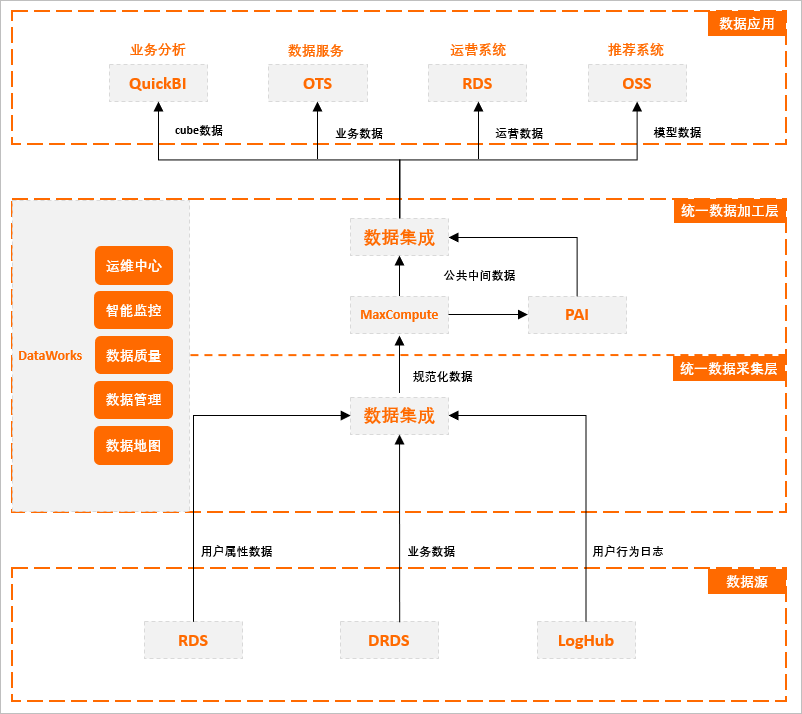
面向小打卡的各项业务场景,所需的基本产品搭配:
- 用户行为分析 :DataWorks + 数据集成 + MaxCompute + Quick BI
- 数据化运营:DataWorks + 数据集成 + MaxCompute + RDS
- 线上数据服务:DataWorks + 数据集成 + MaxCompute + OTS/API 网关
- 推荐系统:DataWorks + 数据集成 + MaxCompute + PAI + OSS
案例实践
背景信息:
- 业务分析需求:监控每小时访问小打卡小程序的新增用户数及活跃用户数。
- 阿里云大数据产品搭配:DataWorks + 数据集成 + MaxCompute + Quick BI。
操作步骤:
- 在DataWork 控制台创建工作空间。
小打卡将原始数据的采集层和中间公共数据的加工层分别部署在独立的项目中。
- 在DataWorks平台中进行一站式的开发。
- 在DataStudio(大数据集成开发环境工具)中建设数据仓库、创建业务流程、物理模型、数据集成任务及ETL任务。
业务流程帮助企业总结业务的一般流程,来有效组织相互依赖的数据流,数据集成任务,ETL任务,数据表和UDF等其他资源。
数据集成可以帮助企业从异构数据源采集数据并沉淀到数据仓库。阿里云的数据集成提供丰富的数据源支持:- 文本存储(FTP/SFTP/OSS/多媒体文件等)
- 数据库(RDS/DRDS/MySQL/PostgreSQL等)
- NoSQL(Memcache/Redis/MongoDB/HBase 等)
- 大数据(MaxCompute/AnalyticDB/HDFS等)
- MPP数据库(HybridDB for MySQL等)
- 继续在DataStudio中开发物理模型和ETL任务。
- 发布任务流程,并在运维中心中调度和监控。
- 在DataStudio(大数据集成开发环境工具)中建设数据仓库、创建业务流程、物理模型、数据集成任务及ETL任务。
- 将数据接入Quick BI,交付业务部门使用。
目前由于小打卡分析业务的团队规模较小,仅有10-20 人的规模,所以当前的架构是直接读取MaxCompute 中的数据。这样做的好处是省钱,非常省钱,部署也是非常的快速。 但是缺点则是查询速度较慢,只能维持在秒级,且报表的查询并法度有瓶颈。后续随着分析团队规模的增加,会适时的优化架构,引入分析型数据库产品ADB 来提供毫秒级的速度和高并发的查询性能。