您可以在ACK集群中快速启用阿里云Prometheus,以实时监控集群和容器的健康状况,并查看可视化的Grafana监控数据大盘。您还可按需配置联系人接收监控告警、配置Prometheus抓取自定义的监控指标等。
索引
功能项 | 功能链接 |
管理组件 | |
监控大盘 | |
配置告警 | |
自定义指标 | |
常见问题 | |
功能扩展 |
阿里云Prometheus监控介绍
阿里云Prometheus监控全面对接开源Prometheus生态,支持类型丰富的组件监控,提供多种开箱即用的预置监控大盘,且提供全面托管的Prometheus服务。借助阿里云Prometheus监控,您无需自行搭建Prometheus监控系统,无需关心底层数据存储、数据展示、系统运维等问题。
阿里云Prometheus服务提供的容器监控能力分为基础版和Pro版。相较于容器集群监控基础版,容器集群监控Pro版提供丰富的Grafana监控大盘、提供容器服务各组件的默认告警规则、额外提供Remote Write和数据投递能力(通过EventBridge)等。关于容器集群监控Pro版的更多优势,请参见基础版与Pro版区别。
相关计费
阿里云Prometheus基础指标费用
启用阿里云Prometheus监控功能后,ACK将采集集群中的容器监控指标。默认采集的指标均为阿里云Prometheus基础指标,在默认情况下不会产生费用。关于阿里云Prometheus基础指标的说明,请参见指标说明。
默认采集的基础指标
启用功能后自动上报的基础指标
容器基础资源监控kubelet
集群应用状态监控kube-state-metrics
集群节点基础资源监控node-exporter
集群节点GPU监控ack-gpu-exporter
托管版集群控制面组件监控指标API Server、etcd、kube-scheduler、kube-controller-manager、cloud-controller-manager
集群CoreDNS基础监控指标
集群Ingress-Controller基础监控指标
重要如您调整了指标存储时长,或上报了自定义指标,将会产生额外计费。关于如何调整指标的存储时长,请参见如何调整指标的存储时长?;关于阿里云Prometheus的计费说明,请参见Prometheus 实例计费。
阿里云Grafana费用
启用阿里云Prometheus监控功能后,默认使用免费的共享版Grafana展示上报的监控数据。关于Grafana的计费说明,请参见计费规则。
开启阿里云Prometheus监控
创建集群时开启


在已有集群中开启
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,按照页面提示完成相关组件的安装和监控大盘的检查。
控制台会自动安装组件、检查监控大盘。安装完成后,您可以单击各个页签查看相应监控数据。
查看阿里云Prometheus Grafana大盘
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Prometheus 监控页面,单击需要查看监控大盘,即可查看相应的监控数据。

配置Prometheus监控告警
为监控任务创建告警可在满足告警条件时通过邮件、短信、钉钉等渠道实时告警,主动帮助您发现异常。告警规则被触发时,系统会向您指定的告警通知对象发送通知。
1、创建通知对象
2、配置告警规则
登录ARMS控制台。在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
在页面顶部选择目标ACK集群所在的地域,然后单击目标实例名称进入对应实例页面。
在左侧导航栏,单击告警规则,在告警规则列表为目标通知对象配置告警规则。具体操作,请参见创建Prometheus告警规则。
自定义Prometheus监控指标并通过Grafana展示
您可以配置Pod Annotation,使用默认服务发现自定义指标监控;也可以配置Service标签,通过ServiceMonitor自定义指标监控。如果同时使用了两种不同的配置方法,可能会导致数据源被多次采集。
Pod Annotation:当您为Pod添加特定的Annotation时,阿里云Prometheus监控可以自动发现这些Pod并开始采集它们暴露的指标。
Service标签:定义一个
Service对象,并为其添加特殊的标签,然后创建一个ServiceMonitor资源来指定如何监控这个Service背后的所有Pod。
Pod Annotation
您可以在Deployment Pod Template中加入Annotation,以实现自定义监控。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载>无状态,按照控制台指引创建一个工作负载。
下方以Deployment为例,介绍主要配置项。详细信息,请参见创建无状态工作负载Deployment。
在容器配置页面,配置容器镜像和所需资源,创建一个Web应用,暴露5000端口,然后单击下一步。
在高级配置页面,创建Service并添加Pod Annotation,然后按照页面提示提交Deployment的创建。
创建Service。
在服务(Service)区域,单击创建,然后按页面提示配置Service信息。配置服务类型为负载均衡,并设置端口映射。
在注解区域,添加以下3个Annotation,然后提交Service的创建。
prometheus.io/scrape:设置为true,表示Prometheus将自动抓取(scrape)指标。prometheus.io/port:本文设置为5000,表示Prometheus要抓取(scrape)的Endpoint端口为5000。prometheus.io/path:本文设置为/access,表示Prometheus要抓取(scrape)的Endpoint路径为/access。
配置自定义指标。
登录ARMS控制台。
在左侧导航栏,单击接入管理。
在已接入环境页签,查看容器环境列表,单击目标容器环境操作列的指标采集,进入指标采集页面。
在指标采集页签,通过添加ServiceMonitor、PodMonitor配置可观测监控Prometheus版的采集规则。
详细信息,请参见管理容器环境自定义采集规则。
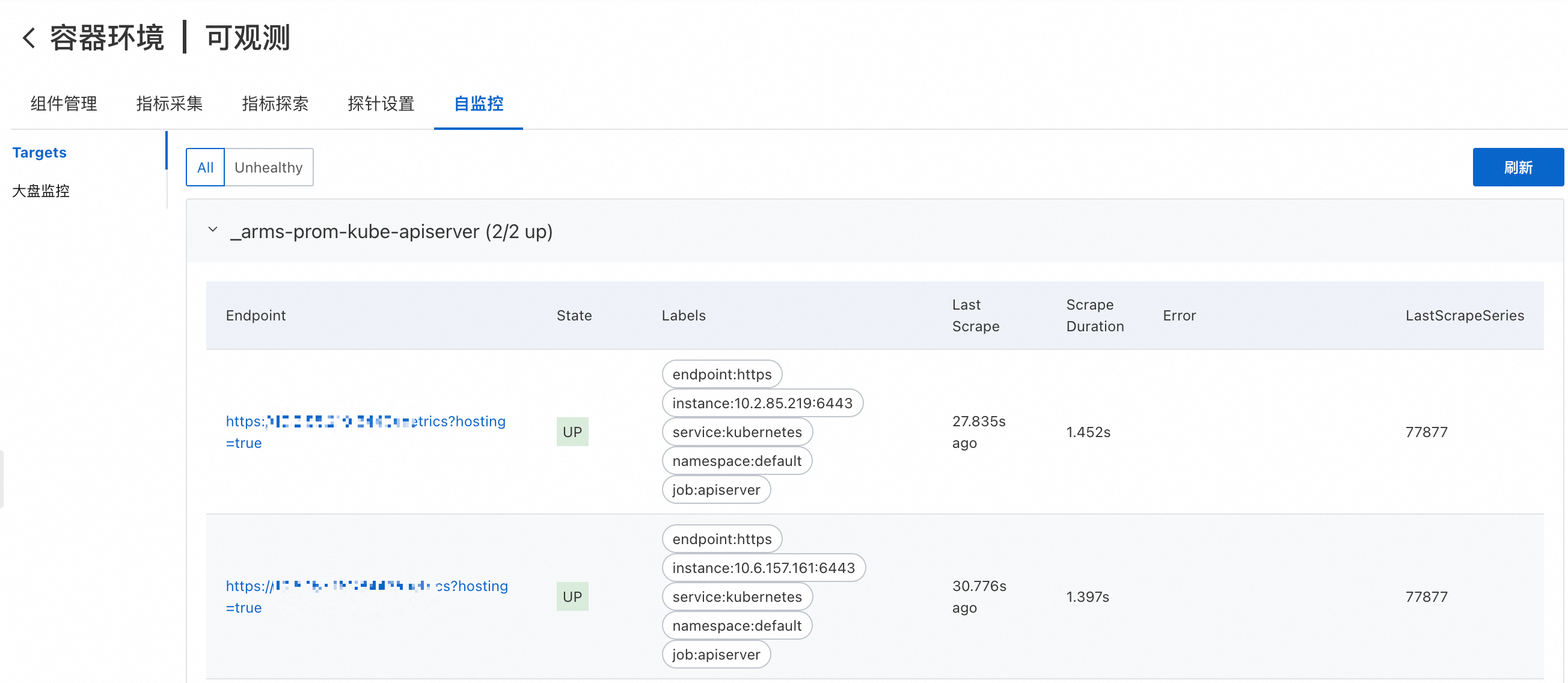
配置完成后,在接入管理的自监控页签下单击Targets,查看自定义的指标是否配置成功,然后单击Endpoint列的链接,增加访问指标值。
关于指标配置的更多信息,请参见DATA MODEL。
自定义指标监控。
在接入管理的指标探索页签,您可以通过选择指标或者编写PromQL查看、验证您的监控数据。具体操作,请参见指标探索。
在接入管理的自监控页签下单击大盘监控,查看自定义指标的Grafana大盘。
Service标签
通过ServiceMonitor方式自定义指标监控时,您部署应用时无需配置Pod Annotation,可以通过为Service对象添加标签来实现。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载>无状态,按照控制台指引创建一个工作负载。
下方以Deployment为例,介绍主要配置项。详细信息,请参见创建无状态工作负载Deployment。
在容器配置页面,配置容器镜像和所需资源,并创建一个Web应用,暴露5000端口,然后单击下一步。
在高级配置页面,单击服务(Service)区域的创建,根据页面提示创建Service。
配置服务类型为负载均衡,并设置端口映射,同时为Service添加标签,例如Key为
app,Value为custom-metrics-pindex。该标签将用于ServiceMonitor的Selector。
配置自定义指标。使Prometheus获得Service的Scrape Endpoint。
登录ARMS控制台。
在左侧导航栏,单击接入管理。
在已接入环境页签,查看容器环境列表,单击目标容器环境操作列的指标采集,进入指标采集页面。
在指标采集页签,单击Service Monitor,进入Service Monitor配置页面,然后单击新增,根据页面展示信息创建ServiceMonitor,然后单击创建。
关于配置自定义指标的更多操作,请参见管理Kubernetes集群服务发现。
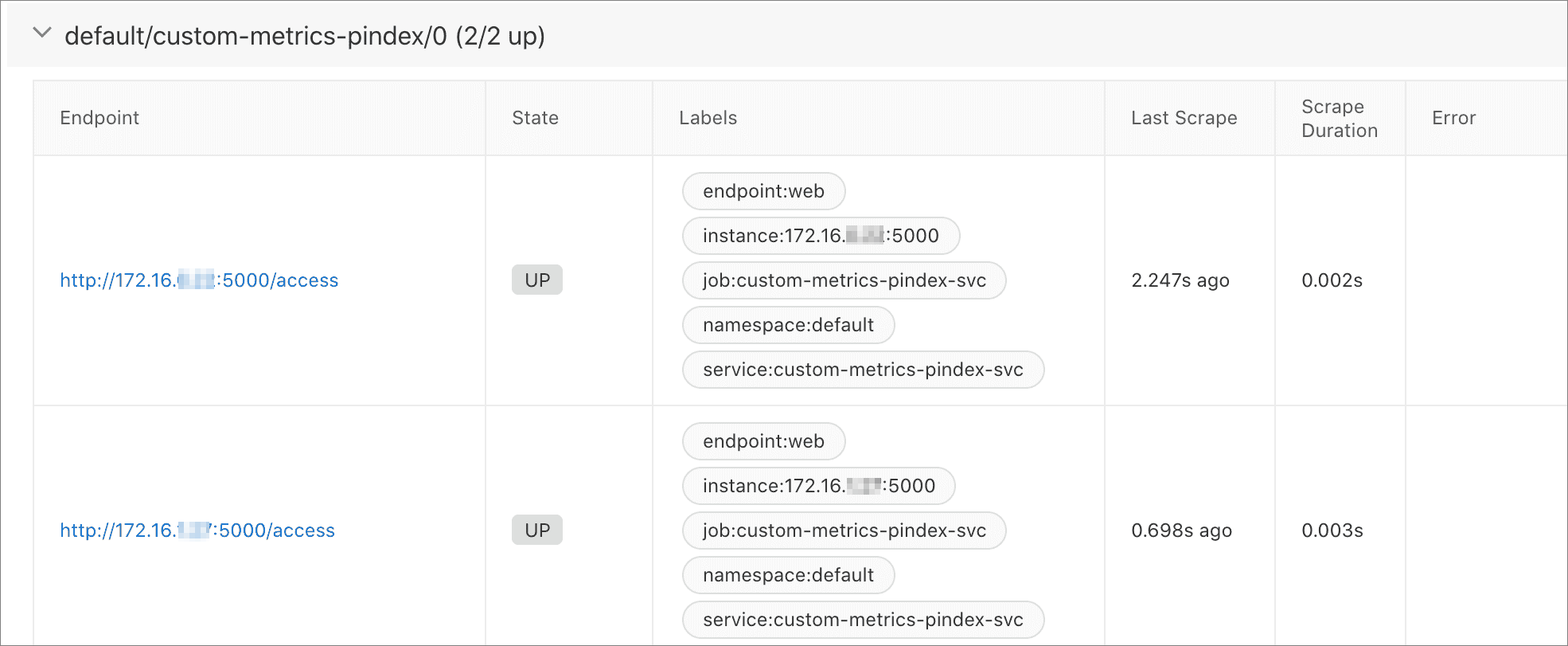
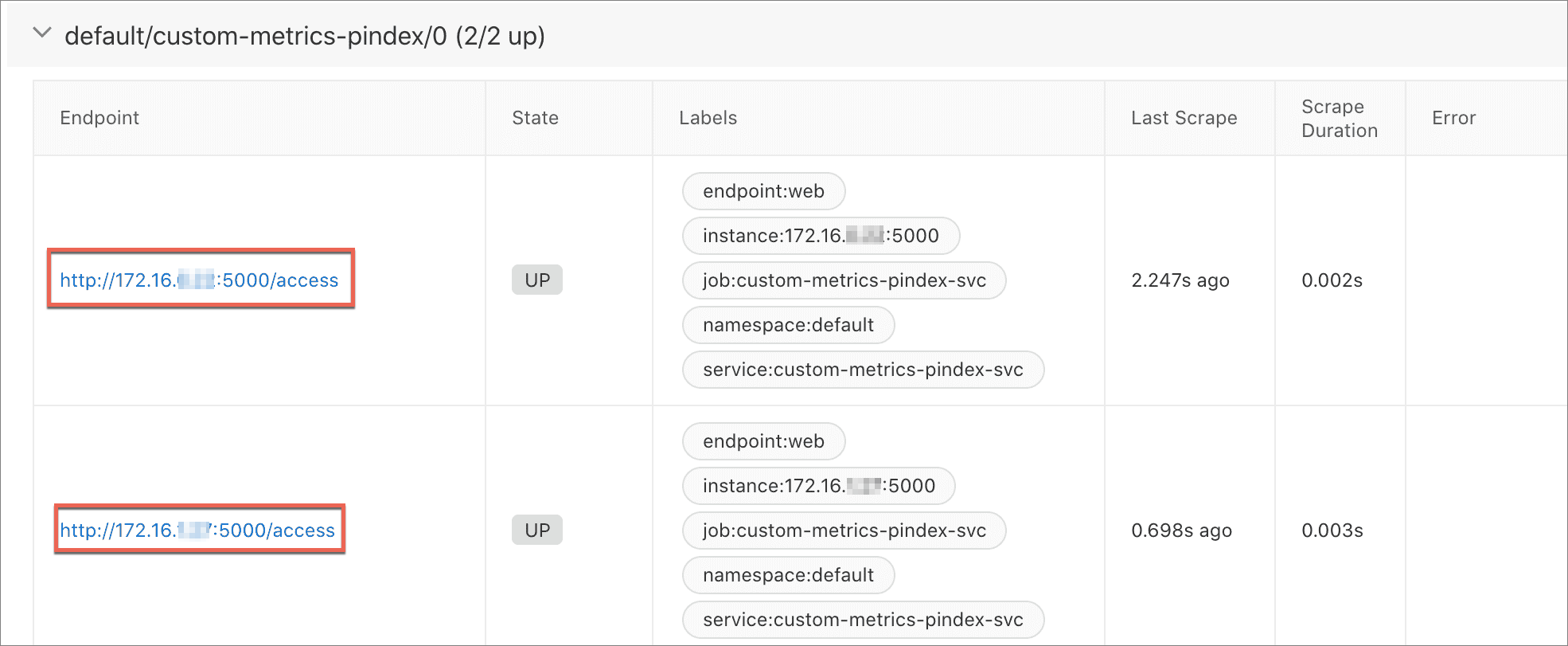
在接入管理的自监控页签下,单击Targets页签,可见Prometheus已经获得服务Scrape Endpoint。
 说明
说明相较于Annotation的实现方式,通过ServiceMonitor定义自定义指标时,Label能够展示Namespace和Service名称。
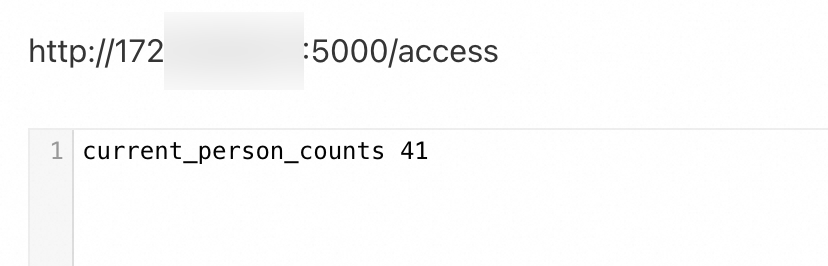
单击Endpoint列的链接,增加访问指标值。
关于指标配置的更多信息,请参见DATA MODEL。
自定义指标监控。
在接入管理的指标探索页签,您可以通过选择指标或者编写PromQL查看、验证您的监控数据。具体操作,请参见指标探索。
在接入管理的自监控页签下单击大盘监控,可观察自定义指标的Grafana图形。
卸载阿里云Prometheus(数据无残留)
您可以通过控制台卸载阿里云Prometheus,卸载后不会有数据残留。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在Helm页面,定位arms-prometheus组件,然后单击操作列的删除,按照页面提示删除Helm Release并清除发布记录。
常见问题
Prometheus监控页面显示未找到相关监控大盘
如果您开启阿里云Prometheus监控后,在容器服务管理控制台的页面上,看到未找到相关监控大盘的提示,按照以下操作步骤解决。

重新安装Prometheus监控组件。
卸载组件:
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在组件管理页面,单击日志与监控页签,找到ack-arms-prometheus组件。单击卸载,然后在弹框中单击确认,
重新安装组件:
确认卸载完成后,单击安装,然后在弹框中单击确认。
等待安装完成后。返回到Prometheus监控页面查看问题是否已解决。
如果问题仍未解决,请继续以下操作。
检查Prometheus实例接入。
登录ARMS控制台。
在左侧导航栏,单击接入管理。
在已接入环境页签,查看容器环境列表,确认是否存在与集群名称相同的容器环境。
没有相应容器环境:参见通过ARMS或Prometheus控制台接入。
有相应容器环境:单击目标容器环境操作列的探针设置,进入探针设置页面。
检查安装探针是否正常运行。
如何查看ack-arms-prometheus组件版本?
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在组件管理页面,单击日志与监控页签,找到ack-arms-prometheus组件。
在组件下方显示当前版本信息,如有新版本需要升级,可单击版本右侧升级完成组件升级。
说明当已安装的组件版本不是最新版本时,才会显示升级操作。
为什么GPU监控无法部署?
如果您的GPU节点上存在污点,可能导致GPU监控无法部署。您可以通过以下步骤查看GPU节点的污点情况。
执行以下命令,查看目标GPU节点的污点情况。
如果您的GPU节点拥有自定义的污点,可找到污点相关的条目。本文以
key为test-key、value为test-value、effect为NoSchedule为例说明:kubectl describe node cn-beijing.47.100.***.***预期输出:
Taints:test-key=test-value:NoSchedule通过以下两种方式处理GPU节点的污点。
执行以下命令,删除GPU节点的污点。
kubectl taint node cn-beijing.47.100.***.*** test-key=test-value:NoSchedule-对GPU节点的污点进行容忍度声明,允许Pod调度到该污点的节点上。
# 1.执行以下命令,编辑ack-prometheus-gpu-exporter。 kubectl edit daemonset -n arms-prom ack-prometheus-gpu-exporter # 2. 在YAML中添加如下字段,声明对污点的容忍度。 #省略其他字段。 #tolerations字段添加在containers字段上面,且与containers字段同级。 tolerations: - key: "test-key" operator: "Equal" value: "test-value" effect: "NoSchedule" containers: #省略其他字段。
手动删除资源或将导致重新安装阿里云Prometheus失败,如何完整地手动删除ARMS-Prometheus?
只删除阿里云Prometheus的命名空间,会导致资源删除后有残留配置,影响再次安装。您可以执行以下操作,完整地手动删除ARMS-Prometheus残余配置。
删除arms-prom命名空间。
kubectl delete namespace arms-prom删除ClusterRole。
kubectl delete ClusterRole arms-kube-state-metrics kubectl delete ClusterRole arms-node-exporter kubectl delete ClusterRole arms-prom-ack-arms-prometheus-role kubectl delete ClusterRole arms-prometheus-oper3 kubectl delete ClusterRole arms-prometheus-ack-arms-prometheus-role kubectl delete ClusterRole arms-pilot-prom-k8s kubectl delete ClusterRole gpu-prometheus-exporter kubectl delete ClusterRole o11y:addon-controller:role kubectl delete ClusterRole arms-aliyunserviceroleforarms-clusterrole删除ClusterRoleBinding。
kubectl delete ClusterRoleBinding arms-node-exporter kubectl delete ClusterRoleBinding arms-prom-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding arms-prometheus-oper-bind2 kubectl delete ClusterRoleBinding arms-kube-state-metrics kubectl delete ClusterRoleBinding arms-pilot-prom-k8s kubectl delete ClusterRoleBinding arms-prometheus-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding gpu-prometheus-exporter kubectl delete ClusterRoleBinding o11y:addon-controller:rolebinding kubectl delete ClusterRoleBinding arms-kube-state-metrics-agent kubectl delete ClusterRoleBinding arms-node-exporter-agent kubectl delete ClusterRoleBinding arms-aliyunserviceroleforarms-clusterrolebinding删除Role及RoleBinding。
kubectl delete Role arms-pilot-prom-spec-ns-k8s kubectl delete Role arms-pilot-prom-spec-ns-k8s -n kube-system kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s -n kube-system
手动删除ARMS-Prometheus资源后,请在容器服务管理控制台的运维管理>组件管理中,重新安装ack-arms-prometheus组件。
安装ack-arms-prometheus组件时报错xxx in use
登录容器服务管理控制台,在左侧导航栏单击集群列表。
在集群列表页面中,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页面左侧导航栏选择,检查是否存在ack-arms-prometheus。
存在:在Helm页面删除ack-arms-prometheus,并在组件管理页面重新安装ack-arms-prometheus。关于安装ack-arms-prometheus的具体操作,请参见管理组件。
不存在:
若没有ack-arms-prometheus,表明删除ack-arms-prometheus helm有资源残留,需要手动清理。关于删除ack-arms-prometheus残留资源的具体操作,请参见阿里云Prometheus监控常见问题。
在组件管理页面安装ack-arms-prometheus。关于安装ack-arms-prometheus的具体操作,请参见管理组件。
提示Component Not Installed后继续安装ack-arms-prometheus组件,安装失败
检查是否已经安装ack-arms-prometheus组件。
登录容器服务管理控制台,在左侧导航栏单击集群列表。
在集群列表页面中,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页面左侧导航栏选择应用>Helm。
在Helm页面检查是否存在ack-arms-prometheus组件。
已有ack-arms-prometheus:在Helm页面删除ack-arms-prometheus,并在组件管理页面重新安装ack-arms-prometheus。关于安装ack-arms-prometheus的具体操作,请参见管理组件。
没有ack-arms-prometheus组件:需进行以下操作。
若没有ack-arms-prometheus,说明删除ack-arms-prometheus helm有资源残留,需要手动清理。关于删除ack-arms-prometheus残留资源的具体操作,请参见阿里云Prometheus监控常见问题。
在组件管理页面安装ack-arms-prometheus。操作入口,请参见管理组件。
检查ack-arms-prometheus的日志是否有报错。
登录容器服务管理控制台,在左侧导航栏单击集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在无状态页面顶部设置命名空间为arms-prom,然后单击arms-prometheus-ack-arms-prometheus。
单击日志页签,查看日志中是否有报错。
检查Agent是否安装报错。
登录ARMS控制台。
在左侧导航栏,单击接入管理。
在已接入环境页签,查看容器环境列表,单击目标容器环境操作列的探针设置,进入探针设置页面。