
如果您的文档格式比较固定,需要抽取的字段有明确和固定的上下文,我们还提供了一些规则设置方法对模型进行补充支持,进一步提升实体抽取模型的表现。这种方式不需要大量标注,准确率也非常高,如果您的界面上看不到规则配置的入口,请联系我们为您开通白名单。另外,我们在高级设置中还预设了一些字段(手机号等),用户无需任何标注就可以自动抽取。在创建模型时可以配置。规则引擎的界面如下:
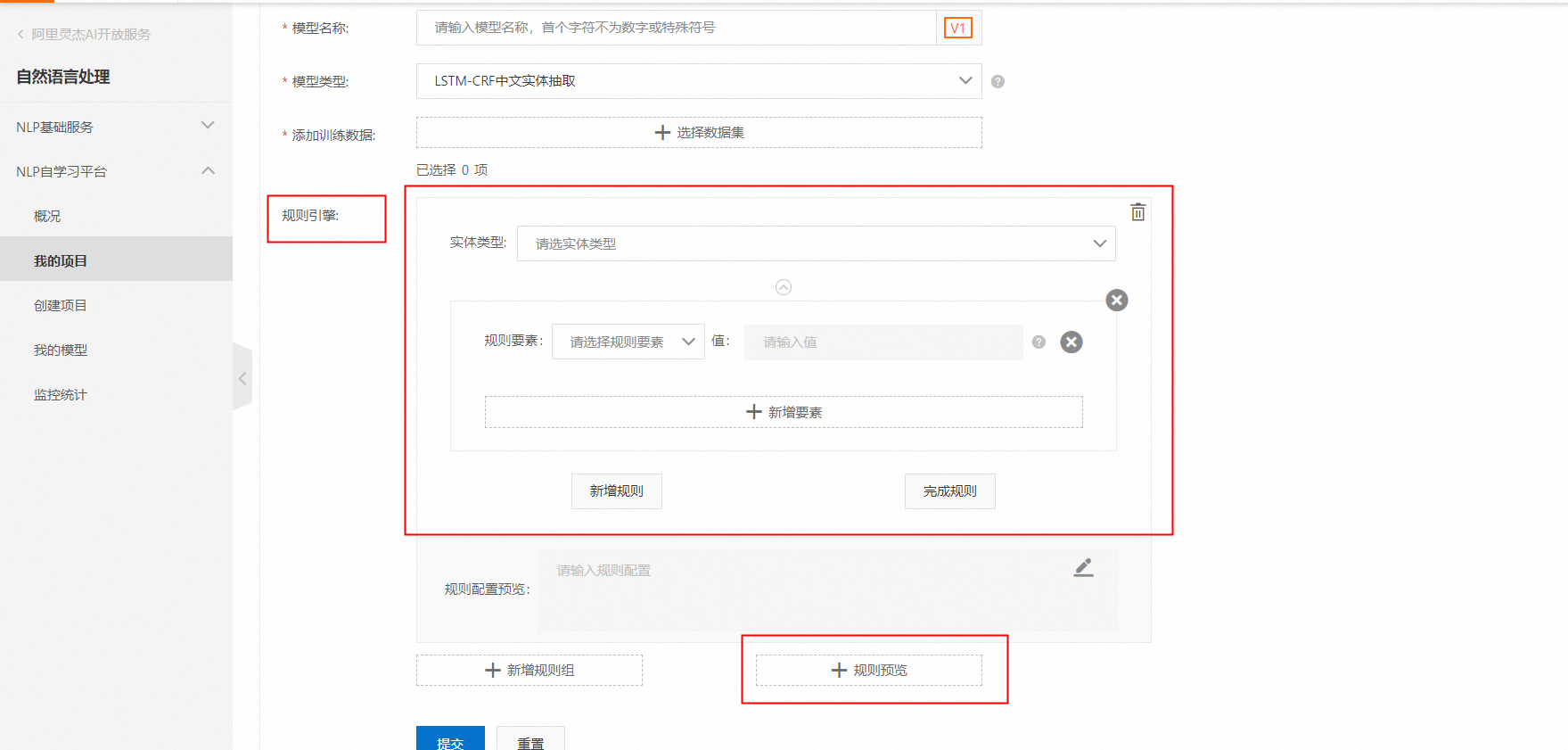
您可以通过规则配置来配置正则、词典、任意字符和模型抽出的实体的组合等“规则”,并且通过规则预览可以测试下您的规则是否生效。
规则配置示例
有如下裁判文书,需要抽取原告和被告的姓名,性别,出生年月。
原告:橙小二,女,住所地浙江省杭州市余杭区。\n\n 被告:王某某,男,2019 年10 月1 日出生,汉族。
可以使用规则引擎来配置正则表达式,抽取出这些字段。
先后点击:新增规则组->实体类型选原告->规则要素选择正则表达式->值填入:(?<=原告:)([^,]+)(?=,)
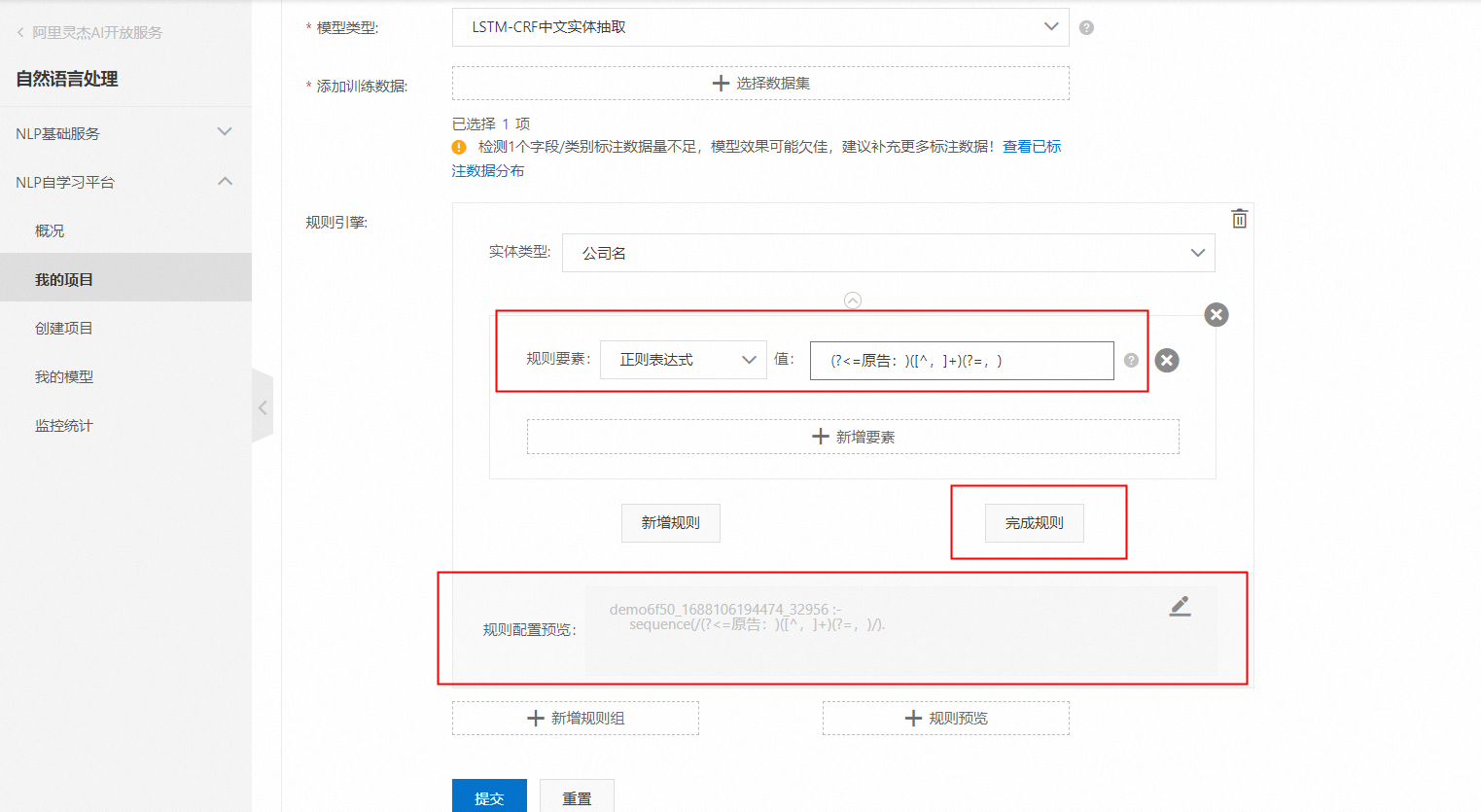
配置好几个规则后,点击规则预览,则可以检查刚刚配置的规则: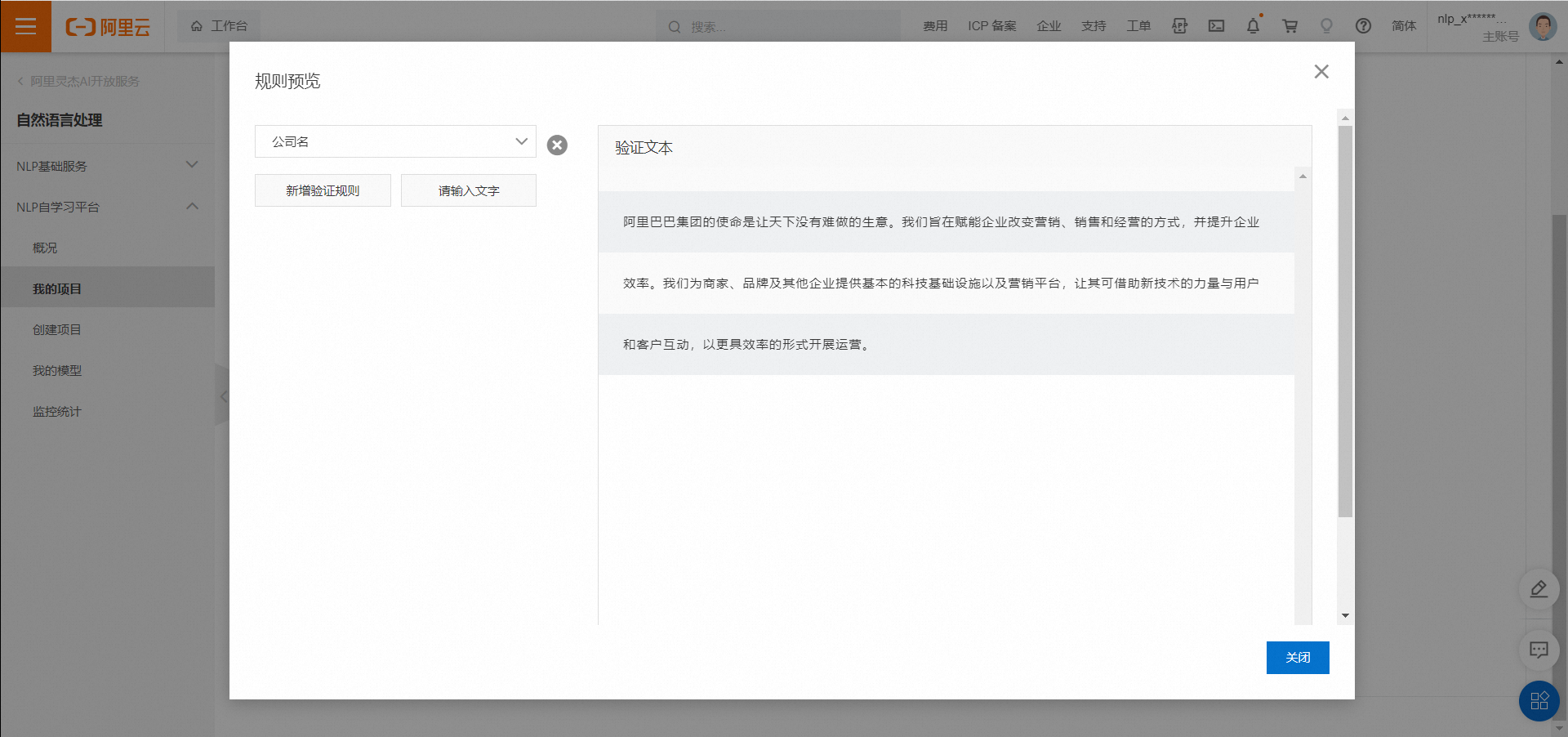
高级设置
我们在高级设置中还预设了通用字段的抽取,方便用户直接抽取这些类型的字段,而无需提供任何标注。当前支持的通用字段有手机号码。
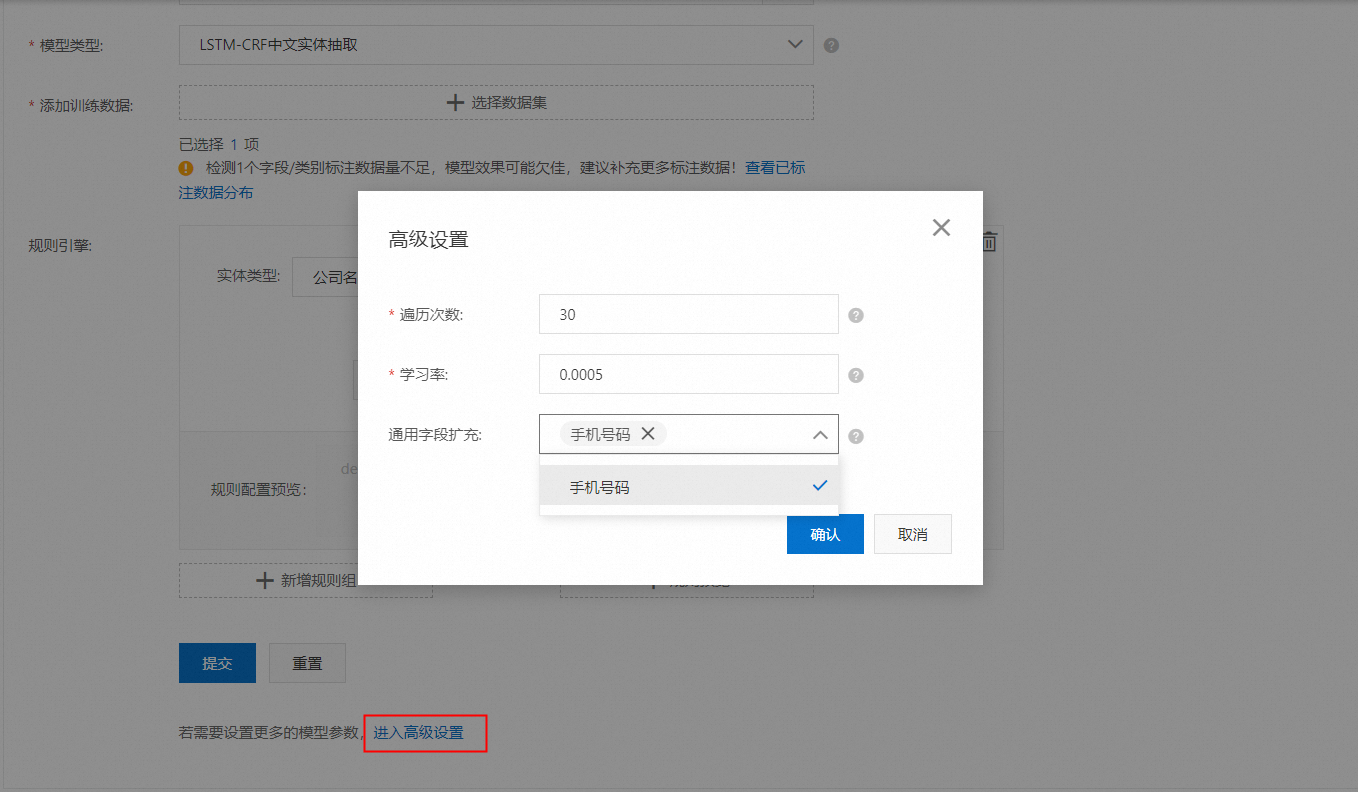
在这个高级设置中,除了通用字段扩充,还有遍历次数和学习率。通常使用默认值即可,在“结果优化”一章会有更具体的说明
该文章对您有帮助吗?