Spark和云原生结合提供计算与存储分离的高性价比大数据分析。
直达最佳实践
更多最佳实践
场景描述
Spark作为快速、通用的大规模数据处理平台,更多关注Spark Application的管理,底层实际资源调度和管理更多的是依靠外部平台的支持例如Mesos、YARN、Kubernetes等。借助阿里云的容器服务Kubernetes版(ACK)、弹性容器组实例(ECI)、文件存储 HDFS或者对象存储OSS提供灵活弹性计算资源弹性可扩展、计算与存储分离架构、成本可控的Spark on ECI解决方案实践。
解决架构
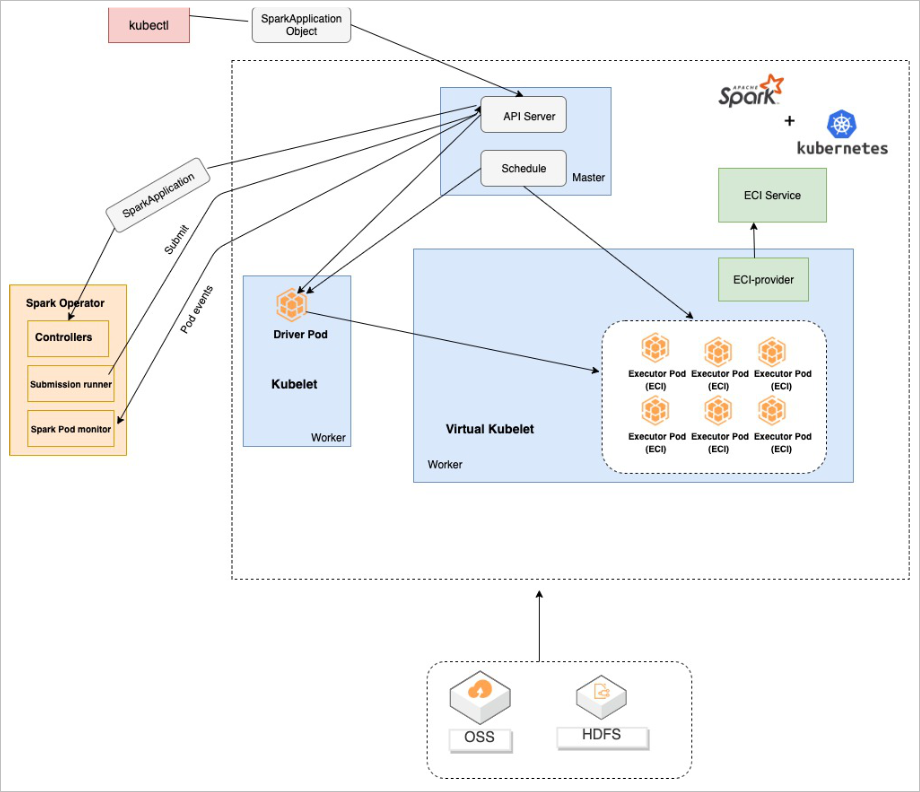
方案优势
- 计算引擎弹性扩缩容,兼顾资源弹性与计算资源成本优化。
- 计算与存储分离架构,结合阿里云原生云存储产品,海量数据湖优势。
- Kubernetes原生的调度性能优势,提升在大规模分析作业时的分析性能优势分。
- 集群资源隔离和按需分配。
解决问题
- 计算资源弹性能力不足,计算资源成本管控能力欠缺。
- 集群资源调度能力和隔离能力不足。
- 计算与存储无法分离,大数据量分析时出现数据存储资源瓶颈。
- Spark submit方式提交分析作业参数支持有限等缺点。