本文为您介绍阿里云共享GPU方案、共享GPU专业版的优势、共享GPU的基础版与专业版的功能对比及使用场景,帮助您了解和更好地使用共享GPU的能力。
视频介绍
背景介绍
阿里云容器服务 Kubernetes 版 ACK(Container Service for Kubernetes)在开源GPU共享调度之后,您可以在阿里云和自有数据中心的容器集群上,通过GPU共享调度框架,实现多个容器共享同一GPU设备,进而降低使用成本。然而,在实现经济节约的同时,还需要确保GPU上的容器可以稳定运行。通过隔离技术,可以限制同一GPU上多个容器的资源使用量,从而避免资源超标导致的相互影响。为此,业界探索了多种方案,如NVIDIA vGPU、MPS和vCUDA,以实现更精细的GPU使用管理。
基于以上需求,阿里云容器服务团队提供了共享GPU方案,既能够实现一个GPU供多个任务使用,同时也能够实现一个GPU上对各个应用进行显存隔离以及GPU算力分割的目标。
功能及优势
阿里云提供的共享GPU方案通过自主研发的宿主机内核驱动,实现对NVIDIA GPU的底层nv驱动更有效的利用。共享GPU功能如下:
更加开放:适配开源标准的Kubernetes和NVIDIA Docker方案。
更加简单:优秀的用户体验。AI应用无需重编译,无需构建新的容器镜像进行CUDA库替换。
更加稳定:针对NVIDIA设备的底层操作更加稳定和收敛,而CUDA层的API变化多端,同时一些Cudnn非开放的API也不容易捕获。
完整隔离:同时支持GPU的显存和算力隔离。
阿里云提供的共享GPU方案是一套低成本、可靠、用户友好的规模化GPU调度和隔离方案,欢迎使用。
优势 | 说明 |
支持共享调度和显存隔离。 |
|
支持共享和隔离策略的灵活配置。 |
|
GPU资源全方位监控。 | 支持同时监控独占和共享GPU。 |
免费 | 在使用共享GPU调度前,需开通云原生AI套件。自2024年06月06日00:00:00起,云原生AI套件全面开放免费使用。 |
使用说明
目前共享GPU调度仅支持ACK托管集群Pro版。关于如何安装和使用共享GPU调度,请参考:
除此以外,还有一些进阶能力,您可以根据业务需求选择:
相关概念
共享GPU调度 vs 独占GPU调度
共享GPU调度指的是多个Pod共同使用一张GPU卡,如下图:
独占GPU调度指的是一个Pod完整占用一张卡或多张卡。如下图:
显存隔离
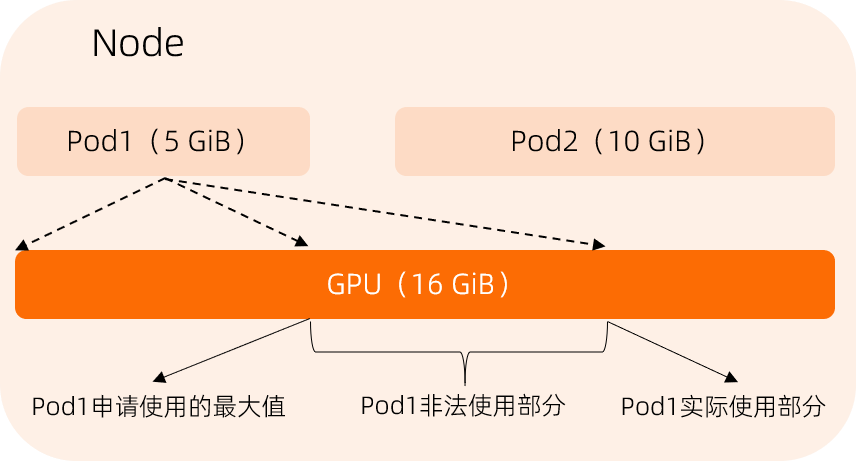
如果没有GPU隔离模块参与,那么共享GPU调度仅能够保证多个Pod运行在一张GPU卡上,并不能解决Pod之间相互影响的问题。以下是一个显存使用的例子。
假设Pod1需要申请5 GiB显存使用,Pod2需要申请10 GiB显存使用。在没有GPU隔离模块的参与的情况下,Pod1实际使用达到10 GiB,这会导致Pod2无法正常运行,相当于Pod1非法使用了5 GiB显存。有了GPU隔离模块后,当Pod1试图使用的GPU显存大于申请的值时,隔离模块将使Pod1失败退出。
节点选卡策略Binpack和Spread
在共享GPU调度中,如果节点存在多张GPU卡,从节点中挑选GPU卡分配给Pod时,有两种策略可以考虑:
Binpack:默认策略,调度系统先分配完节点的一张GPU卡后,再分配节点上另一张GPU卡,避免节点出现GPU资源碎片。
Spread:调度系统会尽量将Pod分散到这个节点的各个GPU上,避免一张GPU卡坏掉后,影响的业务过多。
以下示例表示,某个节点有2张GPU卡,每张卡有15 GiB显存,Pod1申请2 GiB显存,Pod2申请3 GiB显存。

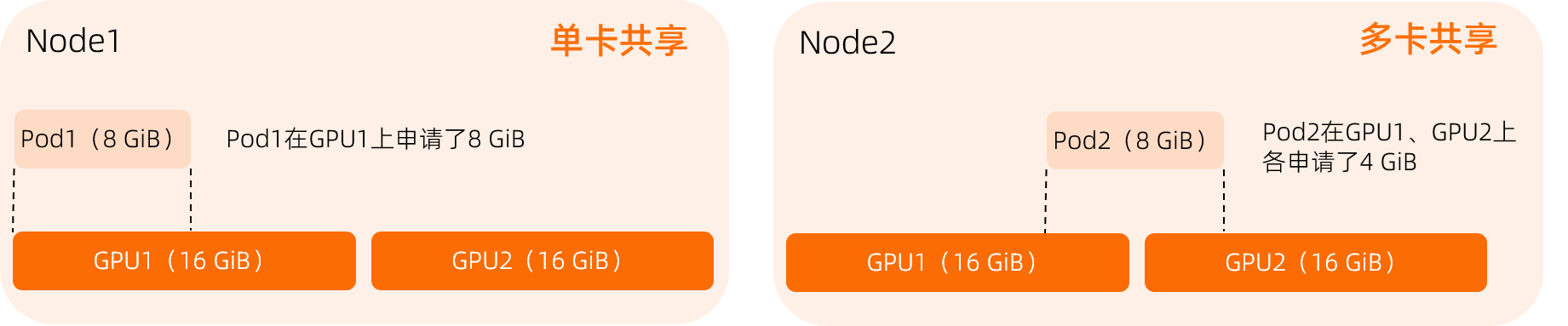
单卡共享 vs 多卡共享
单卡共享:一个Pod仅申请一张GPU卡,占用该GPU部分资源。
多卡共享:一个Pod申请多张GPU卡,每张GPU提供部分资源,且每张GPU提供的资源量相同。