
Flink作业支持智能调优和定时调优两种自动调优模式。本文为您介绍如何配置智能调优和定时调优,以及配置过程中的注意事项。
背景信息
通常,您需要花费大量的时间进行作业调优。例如,新上线一个作业时,需要考虑如何配置该作业的资源、并发个数、Task Manager个数及大小等。此外,作业运行过程中,还需要考虑如何调整作业资源,使作业处于最高资源利用率;作业出现反压或延时增大的情况时,需要考虑如何调整作业配置等。实时计算Flink版提供了自动调优功能,您可以根据以下信息,选择合适的调优模式。
调优模式 | 适用场景 | 使用优势 | 相关文档 |
智能调优 | 某作业使用资源30 CU,上线平稳运行一段时间后,发现在Source无延迟、无反压的情况下,作业的CPU和内存使用率有时会很低。 此时如果您不想人工调节资源,需要系统自动完成资源调节,可以使用智能调优模式。系统将在资源使用率比较低时,自动降低资源配置,在资源使用率提高到一定阈值时,再自动提高资源配置。 |
| 开启智能调优功能,请参见开启并配置智能调优。 |
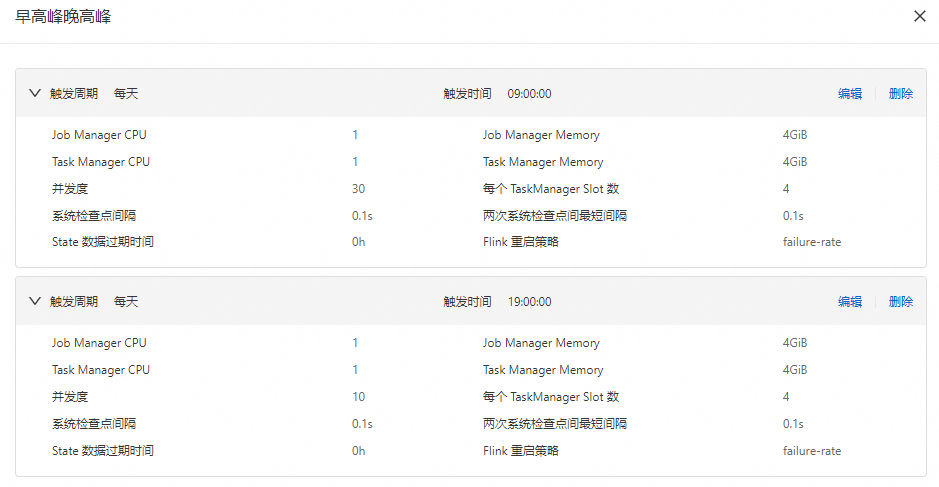
定时调优 | 定时调优计划描述了资源和时间点的对应关系,一个定时调优计划中可以包含多组资源和时间点的关系。 在使用定时调优计划时,您需要明确知道各个时间段的资源使用情况,根据业务时间区间特征,设置对应的资源。 例如,某业务全天早09:00~19:00是业务高峰,19:00到第二天09:00是业务低峰。此时您可以使用定时调优功能,在高峰时间段使用30 CU,在业务低峰时使用10 CU。 | 配置定时调优策略,请参见配置并应用定时调优计划。 |
使用限制
最多创建20个资源计划。
在开启unaligned checkpoint时,不支持调整并发。
智能调优不支持Session集群部署的作业。
YAML作业暂不支持配置自动调优。
调优模式之间互斥,需要先停止正在应用的模式,才可以应用另一种。
定时调优和智能调优模式互斥,如果您应用了任何一种调优模式,则无法应用另一种。如果您需要应用另一种调优模式,则需要先停止正在应用的调优模式。
定时调优中的定时计划互斥,如果您应用了某个定时计划,则无法应用其他定时调优计划。如果您需要应用其他定时调优计划,则需要先停止正在应用的定时调优计划。
注意事项
任何模式的调优使作业重启时,会导致作业短暂停止消费数据。
说明VVR 8.0.1及以上版本,Flink系统会先尝试使用动态参数更新重启作业,再尝试使用作业整体重启。动态参数更新下业务中断时间较之作业整体重启缩短30%-98%,具体依赖于作业状态和逻辑,目前仅支持并发的修改。详情请参见动态扩缩容与参数动态更新。
如果您使用了DataStream作业或SQL自定义的连接器,请确认作业代码中未配置作业并发度,否则智能调优和定时调优将无法调整作业资源,即自动调优配置无法生效。
智能调优无法解决流作业所有的性能瓶颈。
流作业性能问题是由上下游共同决定的,如果是Flink出现了瓶颈,可以通过Flink资源调优解决。但调优策略对作业的处理模式是基于一定的假设的。例如,流量平滑变化、不能有数据倾斜、每个算子的吞吐能力能够随并发度的升高而线性拓展。当业务逻辑严重偏离以上假设时,作业可能会存在异常。例如:
无法触发修改并发度的操作、作业不能达到正常状态和作业持续重启等。
自定义标量函数UDF、自定义聚合函数UDAF或自定义表值函数UDTF性能问题。
智能调优无法识别外部系统的问题。如果出现外部系统问题,您需要自行解决。
外部系统故障或访问变慢时,会导致作业并发度增大,加重外部系统的压力,导致外部系统雪崩。常见的外部系统问题如下:
数据总线DataHub分区不足或消息队列RocketMQ吞吐量不足。
Sink性能问题。
云数据库RDS死锁。
在进行资源调整时,系统会进行资源对比并确定资源调整方式。
如果要应用的资源计划和现在线上配置是CPU或Memory的变更,作业就会使用停止->启动的方式进行资源调整,可能会出现业务中断、数据回追延迟和资源不足导致启动失败等问题。如果仅是并发度的变更,则会直接通过动态扩缩容路径进行调整,减少断流时间。详情请参见动态扩缩容与参数动态更新。
开启并配置智能调优
调优策略
策略 | 适用场景 | 作用及优势 |
(推荐)自适应策略 | 适用于资源需求波动较大、对延迟高度敏感、多任务并发、存在数据倾斜或负载不均以及长时间运行的场景。 | 应用该策略后,系统会根据实时作业资源和指标信息动态修改资源配置,更加关注当前作业的延时和资源使用情况,并根据相关指标的变化更快速地优化资源适配。这样做可以使系统更加敏锐地响应作业需求,提高资源配置的效率和适应性。 |
平稳策略 | 适用于资源需求相对稳定、启停成本较高且对稳定性要求较高的周期性任务、定时任务以及长时间运行的场景。 | 通过应用该策略,系统会寻找适合整个运行周期的固定资源或定时计划,并根据整个周期作业的运行情况来调整作业资源,从而减少启停行为对作业的影响。这样做可以使作业的运行趋于稳定,减少不必要的变动和波动,最终达到收敛状态。 说明
|
操作步骤
进入智能调优开启和配置页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
在自动调优页签,单击智能调优模式。
打开自动调优开关。
开启后,在自动调优页签页面顶部会显示智能调优应用中。如果您需要关闭已开启的智能调优,则可以单击关闭智能调优或者关闭自动调优右侧的开关。
单击调优配置右侧的编辑后,选择调优策略并修改智能调优相关参数。
(推荐)自适应策略
参数
说明
最大CPU限制
作业自动调整资源可以扩容的最大CPU上限,默认值为64 Core。
最大内存限制
作业自动调整资源可以扩容的最大内存上限,默认值为256 GiB。
最大并发度
自动调优可以设置的最大并发度,默认值为1024。
说明对于消息队列类产品(例如Kafka,MQ,SLS等),自动调优并发的调整会受到分区数的影响,无法超过该上限。即如果您设置的并发度最大值超过其分区数,系统将自动调整并发度为分区数。
最小并发度
自动调优可以设置的最小并发度,默认值为1。
扩容策略
满足以下任何一个条件即可触发扩容。如果某些参数不适用于当前业务场景,可以通过单击右侧的禁用按钮将其关闭。
作业的延时是否超过某个阈值,并且该状态需要持续一定时间。
作业单个算子的平均Busy是否超过某个阈值,并且该状态需要持续一定时间。
作业单个TaskManager(TM)的内存使用率是否超过某个阈值。
作业是否发生OutOfMemory(OOM)异常。
作业TaskManager(TM)或JobManager(JM)的每秒垃圾回收(GC)耗时占比是否超过某个阈值,并且该状态需要持续一定时间。
说明您可以根据历史运行数据或默认值设置阈值。如果参考数据不可用,可以开始时先设定一个相对宽松的阈值,观察一段时间后再进行调整。阈值的单位为百分比,取值范围为0% ~ 100%。
持续时间用于过滤瞬时波动,避免因短暂异常而频繁触发扩容。合理设置持续时间有助于提高扩容的准确性。时间单位可以根据需求进行选择。
是否发生OOM异常,无需填写具体值,只需启用或禁用。
缩容策略
满足以下任何一个条件即可触发缩容。如果某些参数不适用于当前业务场景,可以通过单击右侧的禁用按钮将其关闭。阈值单位为百分比,您可以根据需要选择时间单位。
单个算子的平均Busy是否小于某个阈值(单位为百分比),并且该状态需要持续一定时间。
单个TaskManager(TM)的内存使用率是否小于某个阈值。
高级参数配置
某些规则尚处于测试阶段,暂时无法全面提供。如有相关需求,欢迎联系我们以获取支持。
平稳策略
参数
说明
调整间隔时间(分钟)
作业调优重启生效一次之后,下一次再进行调优的时间间隔。默认值是10分钟。
最大CPU限制
作业自动调整资源可以扩容的最大CPU上限,默认值为16 Core。
最大内存限制
作业自动调整资源可以扩容的最大内存上限,默认值为64 GiB。
最大可接受延迟
可以容忍的最大延迟阈值。默认值为1分钟。
更多参数配置
可以配置的参数如下:
mem.scale-down.interval:调低内存时的最小触发时间间隔。默认值为4小时。4小时内,检测到内存使用率低于设定的阈值,系统将会调整内存分配,或建议减少内存分配以优化资源利用率。
parallelism.scale.max:并发度向上调整时,最大并发限制。默认值为-1,表示最大并发没有限制。
说明对于消息队列类产品(例如Kafka,MQ,SLS等),自动调优并发的调整会受到分区数的影响,无法超过该上限。即如果您设置的并发度最大值超过其分区数,系统将自动调整并发度为分区数。
parallelism.scale.min:并发度向下调整时,最小并发限制。默认值为1,表示最小并发为1。
delay-detector.scale-up.threshold:可以容忍的最大延迟阈值。基于消费数据源头的延迟,来衡量作业处理吞吐的能力。默认值为1分钟。当数据处理能力不足延迟超过1分钟,将通过Scale Up方式来提高作业的吞吐能力,Scale Up方式包括增加并发或者拆分Chain,或建议Scale Up。
slot-usage-detector.scale-up.threshold:设定处理节点(不含 Source)的计算/IO资源使用率阈值。当节点处理数据的时间占比持续高于此值,系统将增加并发度。默认值为 0.8。slot-usage-detector.scale-down.threshold:设定处理节点(不含 Source)的计算/IO资源使用率阈值。当节点处理数据的时间占比持续低于此值,系统将减少并发度。默认值为 0.2。slot-usage-detector.scale-up.sample-interval:系统采样处理节点使用率的时间跨度。系统计算该时间段内的平均使用率,并与上述两个阈值比较,决定是否进行scale-up 或scale-down。默认值为 3 分钟。resources.memory-scale-up.max:调整单个Task Manager和Job Manager的内存时,能调整到的最大值。默认值为16 GiB。TM和JM进行智能调优或调大并发时,内存的上限为16 GiB。
单击保存。
保存资源调整计划
平稳策略在作业的运行趋于稳定后,系统会自动生成固定资源或定时计划方案供您选择,您可以手动查看、分析、保存或应用资源调整方案。推荐方案详情如下。
推荐方案 | 使用说明 | 备注 |
固定资源 | 输出单个不含时间维度的资源配置。 单击查看详情后,选中固定资源,单击保存后单击确定。 | 单击确定后,作业部署上的资源配置将被预估的资源配置代替,在作业下次启动时被应用。 |
定时计划(公测中) | 输出时间段和每个时间段的资源配置。 您可以将系统生成的定时计划保存后继续应用,具体操作请参见保存定时计划并应用。 | 智能调优中应用该定时计划后,调优模式将从智能调优自动更换为定时调优,达到平稳后将不会再调整资源。 |
配置并应用定时调优计划
操作步骤
新建定时计划并应用
进入开启并配置定时调优页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
在自动调优页签,单击定时调优模式。
单击新建定时计划。
在资源配置区域,填写资源配置信息。
(可选)单击新增资源配置时段后,配置生效时间和资源配置。
您可以在同一个定时计划中,配置多个时间段的资源调优计划。
重要同一定时计划中,新增资源配置时段的触发时间必须和已有资源配置的触发时间之间的间隔大于半小时,否则无法保存新的资源配置。
单击目标资源定时计划名称右侧操作列下的应用。
保存定时计划并应用
平稳策略在作业的运行趋于稳定后,系统会自动生成定时计划方案供您查看、分析、保存并应用。
进入自动调优页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
单击自动调优页签。
单击查看详情后,推荐方案选中定时计划。
配置定时计划。
动作
说明
备注
1、设置最大变更次数。
指定定时计划最多出现的变更次数。
下限为2次,上限为5次。
2、单击合并时间段。
根据您设定的最大变更次数进行合并。
合并时,根据具体情况考虑是否提前扩容或缩减资源,以满足相应的策略要求。
查看与修改合并后的资源配置。配置详情请参见配置作业资源。
单击页面左下角的保存。
填写定时计划名称,或勾选应用本计划,单击确定。
智能调优中应用该定时计划后,调优模式将从智能调优自动更换为定时调优,达到平稳后将不会再调整资源。
配置示例
全天09:00~19:00是业务高峰,在高峰时间段使用30 CU。19:00到第二天09:00是业务低峰,在业务低峰时使用10 CU。该场景的调优策略配置结果如下图所示。
相关文档
作业智能诊断服务能够帮您监控作业健康状况,全面保障您的业务稳定可靠运行,详情请参见作业智能诊断。
通过作业配置和Flink SQL优化两方面提升Flink SQL作业性能,详情请参见高性能Flink SQL优化技巧。