Spark SQL
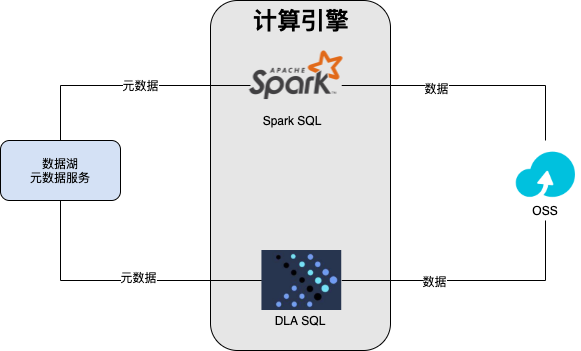
Spark与DLA SQL引擎以及数据湖构建服务共享元数据。
云原生数据湖分析(DLA)产品已退市,云原生数据仓库 AnalyticDB MySQL 版湖仓版支持DLA已有功能,并提供更多的功能和更好的性能。AnalyticDB for MySQL相关使用文档,请参见Spark SQL开发。
Spark访问数据湖元数据服务
Spark引擎可以支持多种元数据服务,既支持访问用户自建的Hive,也支持访问DLA统一管理的数据湖元数据。DLA统一管理的数据湖元数据管理服务,同时支持多种引擎访问,实现多种引擎的元数据信息共享。在数据湖元信息发现、T+1全量同步一键建仓中创建的库表结构, 可以被Spark读取并使用,Spark SQL创建或者修改的元数据也可以被其他引擎访问到。下图是Spark SQL和DLA SQL与元数据服务之间的关系。
登录DLA控制台,单击左侧导航栏的SQL执行,您可以看到所有数据湖中的数据库和表结构,对表进行在线分析查询,以及管理子用户对库表的权限,如下图所示。
纯SQL作业
DLA Spark支持直接在控制台写Spark SQL。无需用户打包jar包或者写python代码,更有利于数据开发人员使用Spark进行数据分析。
您需要先登录DLA控制台,在Serverless Spark > 作业管理菜单中创建SparkSQL类型的作业。创建SparkSQL类型的作业后,系统默认会使用DLA元数据服务。如果您想关闭DLA元数据服务,可以使用以下两种方式:
使用
in-memory catalog,将不会使用DLA元数据服务。set spark.sql.catalogImplementation = in-memory;设置
hive metastore version为1.2.1或其他版本。set spark.sql.catalogImplementation = hive; set spark.sql.hive.metastore.version = 1.2.1;
SparkSQL作业的文本框中,支持直接写SQL语句,每条SQL语句以分号隔开。
SQL语句支持下列类型命令:
SET命令
用于指定Spark的设置,一般置于整个SQL语句的最前面。
每条Set命令指定一个Spark参数的值,每条SET命令用分号隔开。
SET命令的Key和Value均不要加单引号或者双引号。
ADD JAR命令
用于增加Spark SQL运行时,依赖的jar包,比如UDF的jar包,各类数据源连接器的Jar包等。Jar包目前支持OSS格式路径,一般置于整个SQL语句的最前面。
每条add jar命令指定一个oss jar包路径,路径字符串不要加单引号和双引号, 每条ADD JAR命令用分号隔开。
Spark SQL语法所支持的DDL或DML语句
例如查询语句
select。例如插入语句
insert。例如查看数据库
SHOW DATABASE。
SparkSQL语句的使用限制,请参考后续章节使用限制和注意事项。
不在SQL语句最前面的
SET命令和ADD JAR命令,将会在SQL语句运行时生效。例如,两个SELECT语句中间的SET命令将会在上一条SELECT语句执行完后,SET命令才会生效。
代码中使用Spark SQL
您也可以在程序中执行SQL,操作元数据信息,以及读写表内容。下面以PySpark为例进行介绍,其他语言使用方式类似。首先,建立以下Python文件,保存为example.py,将文件上传至OSS。
from pyspark.sql import SparkSession
if __name__ == "__main__":
# init pyspark context
spark = SparkSession \
.builder \
.appName("Python SQL Test") \
.getOrCreate()
# create a database
spark.sql(
"create database if not exists dlatest comment 'c' location 'oss://{your bucket name}/{path}/' WITH DBPROPERTIES(k1='v1', k2='v2')")
# create table
spark.sql(
"create table dlatest.tp(col1 INT) PARTITIONED BY (p1 STRING, p2 STRING) location 'oss://{your bucket name}/{path}/' STORED AS parquet TBLPROPERTIES ('parquet.compress'='SNAPPY')")
# show structure
print(spark.sql("show create table dlatest.tp").collect()[0])
# insert data
spark.sql("INSERT into dlatest.tp partition(p1='a',p2='a') values(1)")
# show data
spark.sql("select * from dlatest.tp").show()通过以下的JSON将作业通过DLA控制台提交Spark作业。
{
"name": "DLA SQL Test",
"file": "oss://path/to/example.py",
"conf": {
"spark.driver.resourceSpec": "small",
"spark.sql.hive.metastore.version": "dla",
"spark.sql.catalogImplementation": "hive",
"spark.dla.connectors": "oss",
"spark.executor.instances": 1,
"spark.dla.job.log.oss.uri": "oss://path/to/spark-logs",
"spark.executor.resourceSpec": "small"
}
}执行成功后, 可以在DLA控制台的SQL执行页面中找到名为dlatest的数据库,以及其下的tp表。
DLA元数据服务对命名大小写不敏感,在引用库名和表名时忽略大小写。
使用DLA元数据服务的限制和注意事项
1. 当前在Spark中仅支持External类型数据库和表的创建和读写操作。
当前Spark连接数据湖元数据服务,只支持外表(External Table)的读写和创建操作。
这意味着在建立数据库时, 需要显式指定LOCATION信息,类似如下的SQL语句。
CREATE DATABASE db1 LOCATION 'oss://test/db1/';同样的,建表语句必须显式指定表的存储LOCATION信息, 类似如下SQL语句。
CREATE TABLE table1(col1 INT) LOCATION 'oss://test/db1/table1/';需要注意以下几个事项:
当用户在Spark中DROP一个表或者表的某个
PARTITION时,并不会删除OSS上的文件。当用户创建一个表时,指定的表的
LOCATION必须是库的LOCATION的子文件夹。当用户为添加表的
PARTITION时,指定的PARTITION LOCATION必须是表的LOCATION的子文件夹。当用户
RENAME PARTITION` 时,并不会改变其在OSS上的路径结构。
2. 当前Spark中仅支持以OSS为存储的外表。
在当前阶段,数据湖分析SQL执行支持多种不同的存储,包括RDS、表格存储等等。当前在Spark中使用元数据服务支持读写以OSS为存储的外表。
使用Spark直接创建数据库和数据表,LOCATION必须指定一个合法的OSS地址。
对于其他存储的支持,后续会陆续更新。
3. 当前禁止创建DEFAULT为名字的数据库。
由于不允许使用DEFAULT为名字的数据库,需要注意以下两个事项:
禁止在Spark中创建和操作名为
DEFAULT的数据库。在Spark中执行SQL时, 操作表之前需要使用
USE DatabaseNameSQL语句来切换到目标数据。或者显式指定某个表属于哪个数据库, 例如SELECT * FROM db1.table1。
4. 当前在Spark中执行 ALTER 语句有部分限制。
用户可以通过类似ALTER DATABASE ... 等语句修改库和表的元数据信息,当前在Spark中使用这一类语句有如下的限制。
当前对数据库,仅支持修改
COMMENT信息,其它如LOCATION、PROPERTIES禁止修改。当前仅支持修改表的
COLUMN和PROPERTIES信息,如添加列、修改注解等等。请注意这里的COLUMN必须是非PARTITION列。
5. 当前在 SQL执行 中操作Spark表的一些限制。
当用户在Spark程序中创建了数据库db1和表table1后,如果在控制台的SQL执行中操作它们,需要显式检测其是否存在。如尝试删除此数据库时必须使用如下语句。
DROP DATABASE IF EXISTS db1;6. 当前在Spark SQL中不支持GRANT类赋权语句。
同开源社区一致,当前用户无法通过Spark引擎执行一个GRANT语句来修改子账户赋权。
- 本页导读 (1)