熟悉Spark的开发者都了解SparkPi,它相当于Spark引擎的”Hello World!“。本文介绍如何在DLA控制台跑通SparkPi。
准备事项
操作步骤
- 登录云原生数据湖分析管理控制台。
- 在概览页面的左上角,选择虚拟集群所在地域。
- 单击左侧导航栏的。
- 在作业编辑页面,单击创建作业模板,填写以下作业信息:
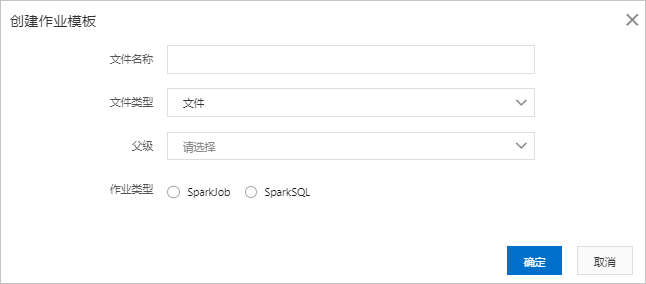
- 新创建的作业中包含了SparkPi作业的默认配置,在作业编辑页面,单击执行即可。
说明 关于作业提交的详细说明,请参见创建和执行Spark作业。