本文介绍通过阿里云Prometheus对GPU资源进行监控,查看GPU各项指标。
前提条件
您已完成以下操作:
已安装阿里云Prometheus监控。具体操作,请参见阿里云Prometheus监控。
费用说明
在ACK集群中使用ack-gpu-exporter组件时,默认情况下它产生的阿里云Prometheus监控指标被视为基础指标,并且是免费的。然而,如果您需要调整监控数据的存储时长,即保留监控数据的时间超过阿里云为基础监控服务设定的默认保留期限,这可能会产生额外的费用。关于阿里云Prometheus的自定义收费策略,请参见计费概述。
使用阿里云Prometheus进行GPU监控
登录容器服务管理控制台。
在集群列表页面,单击目标集群名称或者目标集群右侧操作列下的详情。
在集群管理页左侧导航栏,选择。
在Prometheus监控大盘列表页面,单击GPU APP和GPU Node页签,您分别可以看到GPU APP和GPU Node两个监控大盘。
GPU APP用于监控Pod的GPU使用情况。
GPU Node用于监控集群节点的GPU使用情况。
使用以下YAML文件在GPU节点上部署一个服务,测试监控效果。
apiVersion: apps/v1 kind: Deployment metadata: name: bert-intent-detection spec: replicas: 1 selector: matchLabels: app: bert-intent-detection template: metadata: labels: app: bert-intent-detection spec: containers: - name: bert-container image: registry.cn-beijing.aliyuncs.com/ai-samples/bert-intent-detection:1.0.1 ports: - containerPort: 80 resources: limits: nvidia.com/gpu: 1 --- apiVersion: v1 kind: Service metadata: labels: run: bert-intent-detection name: bert-intent-detection-svc spec: ports: - port: 8500 targetPort: 80 selector: app: bert-intent-detection type: LoadBalancer在Prometheus监控大盘列表页面,单击GPU APP页签。
在GPU APP监控页面,您可以看到GPU显存、使用率、电量、稳定性几项指标,以及部署在GPU节点上的应用。
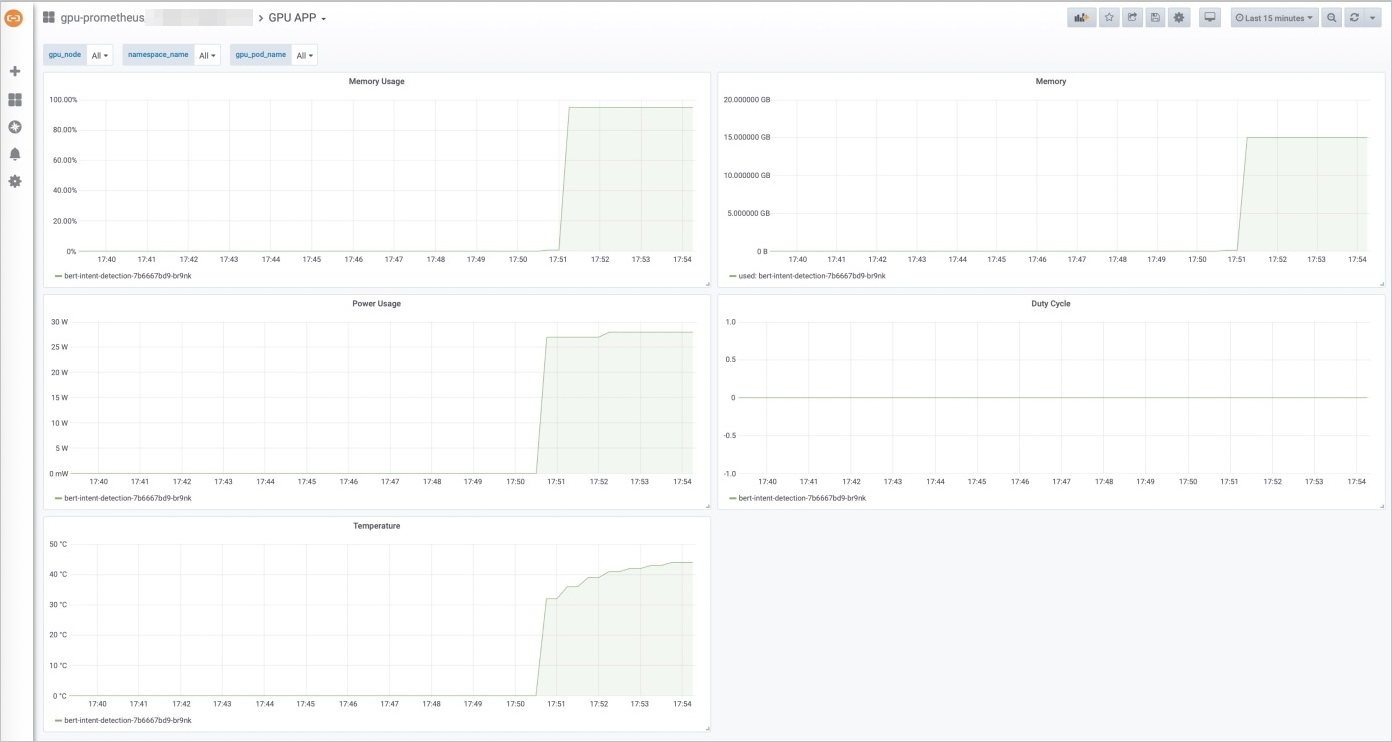
压测部署在GPU节点上的应用,查看监控状态的变化。
执行以下命令查看推理服务并获取IP地址。
kubectl get svc bert-intent-detection-svc预期输出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE bert-intent-detection-svc LoadBalancer 172.23.5.253 123.56.XX.XX 8500:32451/TCP 14m执行以下命令进行压测。
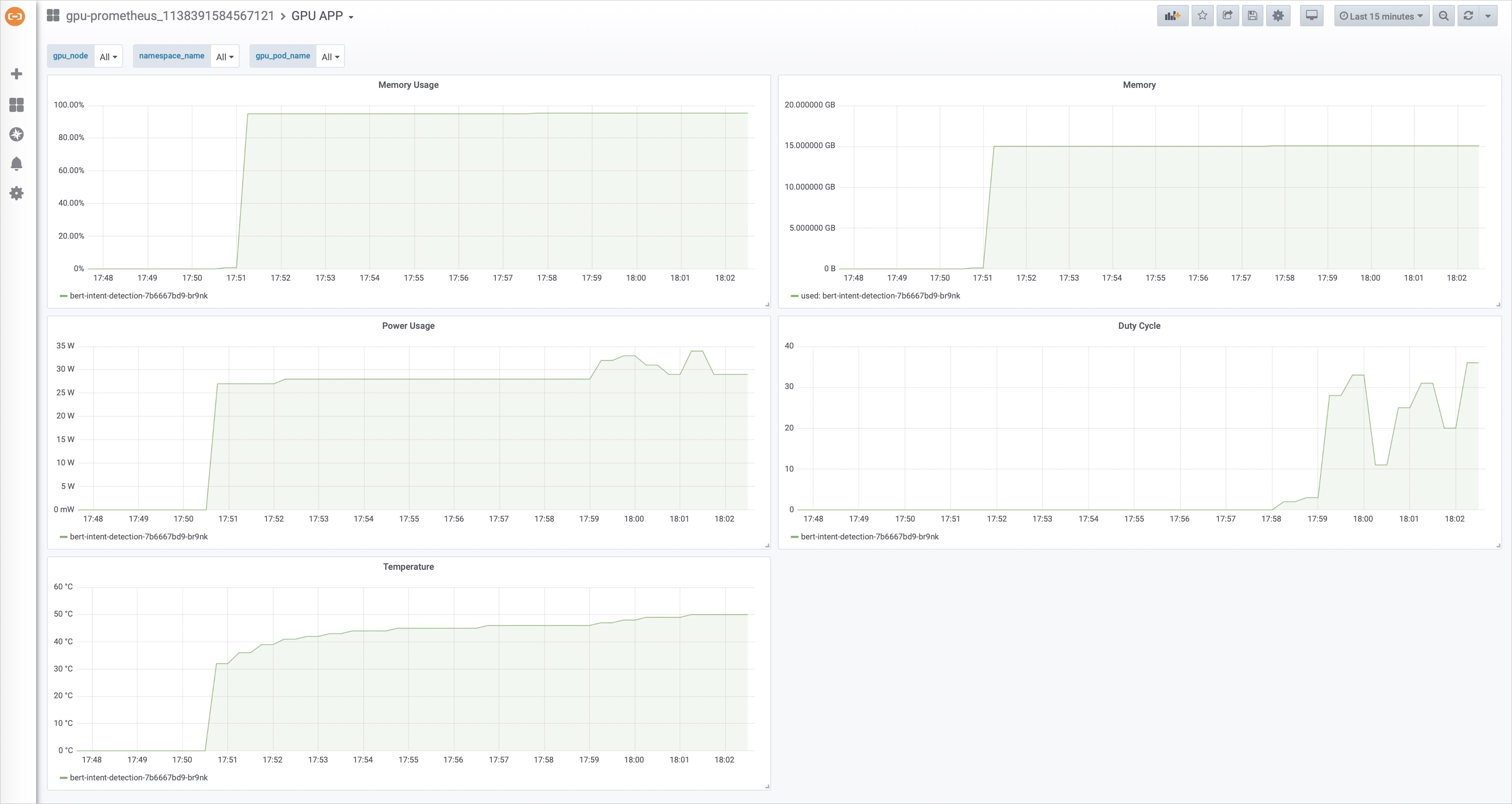
hey -z 10m -c 100 "http://123.56.XX.XX:8500/predict?query=music"下图可以看出压测时,GPU利用率有了明显的变化。
反馈
- 本页导读 (1)
文档反馈