
分布式事务
本次最佳实践通过分析分布式事务遇到的一些问题和业界提供的解决方案,及自己在项目开发中使用阿里GTS产品解决分布式事务的方案提供给广大客户参考。
全局事务服务简介
随着互联网的快速发展,软件系统由原来的单体应用转变为分布式应用,分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间远程协作才能完成事务操作,这种分布式系统环境下的事务机制称之为分布式事务。
全局事务服务(Global Transaction Service,简称 GTS)是一款接入简单的分布式事务中间件,用于解决分布式环境下的事务一致性问题。在单机数据库下很容易维持事务的ACID(Atomicity、Consistency、Isolation、Durability)特性,但在分布式系统中并不容易,GTS可以保证分布式系统中的分布式事务的ACID特性。 GTS支持DRDS、RDS、MySQL等多种数据源,可以配合EDAS和Dubbo等微服务框架使用,兼容MQ实现事务消息。通过各种组合,可以轻松实现分布式数据库事务、多库事务、消息事务、服务链路级事务等多种业务需求。
分布式事务来源
做系统拆分的时候几乎都会遇到分布式事务的问题,一个仿真的案例如下: 项目初期,由于用户体量不大,订单模块和钱包模块共库共应用(大war包时代),模块调用可以简化为本地事务操作,这样做只要不是程序本身的BUG,基本可以避免数据不一致。
项目初期,由于用户体量不大,订单模块和钱包模块共库共应用(大war包时代),模块调用可以简化为本地事务操作,这样做只要不是程序本身的BUG,基本可以避免数据不一致。
后期因为用户体量越发增大,基于容错、性能、功能共享等考虑,把原来的应用拆分为订单微服务和钱包微服务,两个服务之间通过非本地事务(这里可以是HTTP或者消息队列等)进行数据同步,这个时候就很有可能由于异常场景出现数据不一致的情况。
调用达到强一致性
以订单微服务请求钱包微服务进行扣款并更新订单状态这个调用过程为例,假设采用HTTP同步调用,项目如果由经验不足的开发者开发这个逻辑,可能会出现下面的伪代码:
处理订单微服务请求钱包微服务进行扣款并更新订单状态方法() {
[开启事务]
1、查询订单
2、HTTP调用钱包微服务扣款
3、更新订单状态为扣款成功
[提交事务]
}
这是一个从肉眼上看起来没有什么问题的解决方法,HTTP调用直接嵌入到事务代码块内部,猜想最初开发者的想法是:HTTP调用失败抛出异常会导致事务回滚,用户重试即可;HTTP调用成功,事务正常提交,业务正常完成。这种做法看似可取,但是带来了极大的隐患,根本原因是:事务中嵌入了RPC调用。
假设三种比较常见的情况:
上述方法中,第2步HTTP调用钱包微服务扣款由于钱包微服务本身的各种原因导致扣款接口响应极慢,会导致处理方法事务(数据库连接)长时间挂起,持有的数据库连接无法释放,会导致数据库连接池的连接耗尽,很容易导致订单微服务其他依赖数据库的接口无法响应。
钱包微服务是单节点部署(并不是所有的公司微服务都做得很完善),升级期间应用停机,上面方法中第2步接口调用直接失败,这样会导致短时间内所有的事务都回滚,相当于订单微服务的扣款入口是不可用的。
网络是不可靠的,HTTP调用或者接受响应的时候如果出现网络闪断有可能出现了服务间状态不能互相明确的情况,例如订单微服务调用钱包微服务成功,接受响应的时候出现网络问题,会出现扣款成功但是订单状态没有更新的可能(订单微服务事务回滚)。
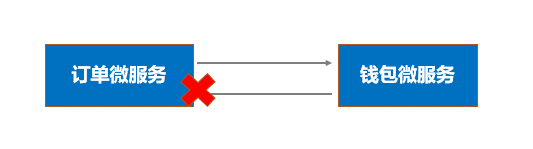

尽管现在有Hystrix等框架可以基于线程池隔离调用或者基于熔断器快速失败,但是这是收效甚微的。因此,个人认为事务中直接RPC调用达到强一致性是完全不可取的,如果使用了这种方式实现"分布式事务"建议整改,否则只能每天祈求下游服务或者网络不出现任何问题。
异步消息推送
使用消息队列进行服务之间的调用也是常见的方式之一,但是使用消息队列交互本质是异步的,无法感知下游消息消费方是否正常处理消息。用前一节的例子,假设采用消息队列异步调用,项目如果由经验不足的开发者开发这个逻辑,可能会出现下面的伪代码:
[订单微服务请求钱包微服务进行扣款并更新订单状态]
处理订单微服务请求钱包微服务进行扣款并更新订单状态方法(){
[开启事务]
1、查询订单
2、推送钱包微服务扣款消息(推送消息)
3、更新订单状态为扣款成功
[提交事务]
}
如果抽象一点表示如下:
方法(){
DataSource dataSource = xx;
Connection con = dataSource.getConnection();
con.setAutoCommit(false);
try{
1、SQL操作;
2、推送消息;
3、SQL操作;
con.commit();
}catch(Exception e){
con.rollback();
}finally{
释放其他资源;
release(con);
}
}
这样做,在正常情况下,也就是能够正常调用消息队列中间件推送消息成功的情况下,事务是能够正确提交的。但是存在两个明显的问题:
消息队列中间件出现了异常,无法正常调用,常见的情况是网络原因或者消息队列中间件不可用,会导致异常从而使得事务回滚。这种情况看起来似乎合情合理,但是仔细想:为什么消息队列中间件调用异常会导致业务事务回滚,如果中间件不恢复,这个接口调用是否相当于不可用。
如果消息队列中间件正常,消息正常推送,但是第3步更新订单状态为扣款成功时由于SQL存在语法错误导致事务回滚,这样就会出现了下游微服务被调用成功,本地事务却回滚的问题,导致了上下游系统数据不一致。
所以,事务中进行异步消息推送是一种并不可靠的实现。
业界主流解决方案
业界目前主流的分布式事务解决方案主要有:多阶段提交方案(2PC、3PC)、补偿事务(TCC)和消息事务(主要是RocketMQ,基本思想也是多阶段提交方案,其他消息队列中间件并没有实现分布式事务)。这些方案主要原理如下:
多阶段提交方案
常见的有二阶段和三阶段提交事务,需要额外的资源管理器来协调事务,数据一致性强,但是实现方案比较复杂,对性能的牺牲比较大(主要是需要对资源锁定,等待所有事务提交才能解锁),不适用于高并发的场景,目前比较知名的有阿里开源的FESCAR。
FESCAR中有三大基本组件:
Transaction Coordinator(TC):维护全局和分支事务的状态,驱动全局事务提交与回滚。
Transaction Manager(TM):定义全局事务的范围:开始、提交或回滚全局事务。
Resource Manager(RM):管理分支事务处理的资源,与TC通信以注册分支事务并报告分支事务的状态,并驱动分支事务提交或回滚。
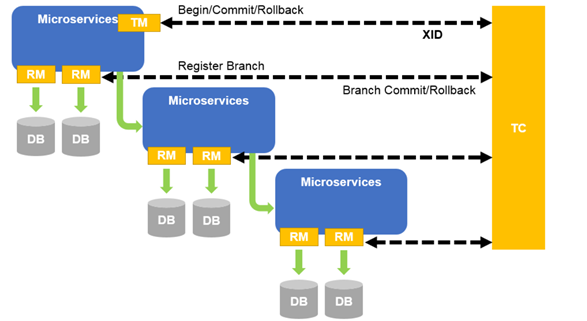
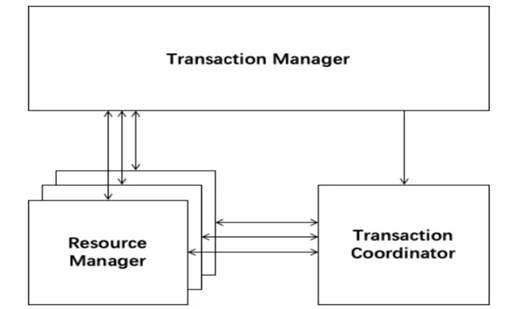 FESCAR 管理分布式事务的典型生命周期:
FESCAR 管理分布式事务的典型生命周期:TM要求TC开始新的全局事务,TC生成表示全局事务的XID。
XID通过微服务的调用链传播。
RM在TC中将本地事务注册为XID的相应全局事务的分支。
TM要求TC提交或回滚XID的相应全局事务。
TC驱动XID的相应全局事务下的所有分支事务,完成分支提交或回滚。
 演进历史:
演进历史:TXC:Taobao Transaction Constructor,阿里巴巴中间件团队自2014年起启动该项目,以满足应用程序架构从单一服务变为微服务所导致的分布式事务问题。
GTS:Global Transaction Service,2016年TXC作为阿里中间件的产品,更名为GTS 发布。
FESCAR:2019年开始基于TXC/GTS开源FESCAR。
补偿事务
一般也叫TCC,因为每个事务操作都需要提供三个操作尝试(Try)、确认(Confirm)和补偿/撤销(Cancel),数据一致性的强度比多阶段提交方案低,但是实现的复杂度会有所降低,比较明显的缺陷是每个业务事务需要实现三组操作,有可能出现过多的补偿方案的代码;另外有很多场景TCC是不合适的。
TCC模式:
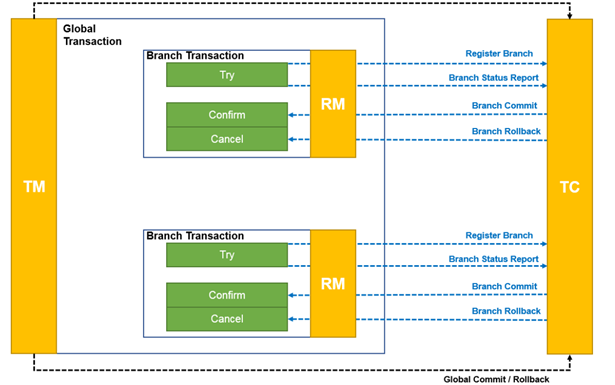 TCC 模式 RM 驱动分支事务的行为分为以下两个阶段:
TCC 模式 RM 驱动分支事务的行为分为以下两个阶段:执行阶段:
向TC注册分支。
执行业务定义的Try方法。
向TC上报Try方法执行情况:成功或失败。
完成阶段:
全局提交,收到TC的分支提交请求,执行业务定义的Confirm方法。
全局回滚,收到TC的分支回滚请求,执行业务定义的Cancel方法。
消息事务
这里只谈RocketMQ的实现,一个事务的执行流程包括:发送预消息、执行本地事务、确认消息发送成功。它的消息中间件存储了下游无法消费成功的消息,并且不断重试推送下游消费消息,而生产者(上游)需要提供一个check接口,用于检查成功发送预消息但是未确认最终消息发送状态的事务的状态。
 FESCAR 管理分布式事务的典型生命周期:
FESCAR 管理分布式事务的典型生命周期: 演进历史:
演进历史: TCC 模式 RM 驱动分支事务的行为分为以下两个阶段:
TCC 模式 RM 驱动分支事务的行为分为以下两个阶段:项目实践中使用的方案
有些公司环境的技术栈中没有使用RabbitMQ,而是主要使用RocketMQ,则需要针对RocketMQ做消息事务的适配。目前业务系统中消息异步交互存在三种场景:
消息推送实时性高,可以接受丢失。
消息推送实时性低,不能丢失。
消息推送实时性高,不能丢失。
本次实践使用了本地消息日志表的解决方案: 主要思路如下:
主要思路如下:
需要发送到消费方消息的保存和业务处理绑定在同一个本地事务中,需要额外建立一张本地消息日志表。
本地事务提交之后,可以在事务外对本地消息表进行查询并且进行消息推送,或者采用定时调度轮询本地消息表进行消息推送。
下游服务消费消息成功可以回调一个确认到上游服务,这样就可以从上游服务的本地消息表删除对应的消息记录。
伪代码如下:
[消息推送实时性高,可以接受丢失-这种情况下可以不需要写入本地消息表 - start]
处理方法(){
[本地事务开始]
1、处理业务操作
[本地事务提交]
2、组装推送消息并且进行推送
}
[消息推送实时性高,可以接受丢失-这种情况下可以不需要写入本地消息表 - end]
[消息推送实时性低,不能丢失 - start]
处理方法(){
[本地事务开始]
1、处理业务操作
2、组装推送消息并且写入到本地消息表
[本地事务提交]
}
消息推送调度模块(){
3、查询本地消息表待推送数据进行推送
}
[消息推送实时性低,不能丢失 - end]
[消息推送实时性高,不能丢失 - start]
处理方法(){
[本地事务开始]
1、处理业务操作
2、组装推送消息并且写入到本地消息表
[本地事务提交]
3、消息推送
}
消息推送调度模块(){
4、查询本地消息表待推送数据进行推送
}
[消息推送实时性高,不能丢失 - end]
对于"消息推送实时性高,可以接受丢失"这种情况,实际上不用依赖本地消息表,只要在业务操作事务提交之后组装和推送消息即可。这种情况会存在是因为消息队列中间件不可用或者本地应用宕机导致消息丢失的问题(本质是因为数据是内存态,非持久化),可靠性不高,但是绝大多数情况下没有问题。如果使用spring-tx的声明式事务@TxcTransaction,可以使用事务同步器实现嵌入于业务操作事务代码块中的REST操作延后到事务提交后执行,这样子REST调用的代码物理位置就可以放置在事务代码块内,例如:
@TxcTransaction
public String transferAccount(String userId1, String userId2, int money) throws ParameterException {
logger.info("GTS Transaction Begins: " + TxcContext.getCurrentXid());
//判断传入参数是否为空
if (StringUtil.isEmpty(userId1) || StringUtil.isEmpty(userId2)) {
parameterException.addErrorField("userId", "用户编号信息不能为空!");
}
if (String.valueOf(money).equals("") || money < 0) {
parameterException.addErrorField("money", "金额信息为空或金额不正确");
}
//校验用户编号信息格式是否正确
String regex = "[U]{1}[0-9]{6}";
boolean userId1Flag = userId1.matches(regex);
if (userId1Flag == false) {
parameterException.addErrorField("userId1", "转出用户编号格式不正确!");
}
boolean userId2Flag = userId2.matches(regex);
if (userId2Flag == false) {
parameterException.addErrorField("userId2", "转入用户编号格式不正确!");
}
if (parameterException.isErrorField()) {
throw parameterException;
}
//1.处理业务逻辑
judgeUserStatus(userId1);
//从数据源A的帐户扣款
Entry entry = null;
try {
entry = SphU.entry("Transfer Account", EntryType.IN);
logger.info("转账过程,扣减账户余额限流!");
userFeginClient.updateBalance(userId1, money);
} catch (BlockException e) {
e.printStackTrace();
} finally {
if (entry != null) {
entry.exit();
}
}
//2.发MQ消息
try {
txcMQProducer.start();
logger.info("MQ Producer is started.");
} catch (Throwable e) {
throw new RuntimeException("Failed to start MQ Producer", e);
}
Message message = new Message();
message.setTopic(TOPIC);
message.setBody(String.valueOf(money).getBytes());
String messageId = null;
try {
SendResult r = txcMQProducer.send(message);
messageId = r.getMessageId();
logger.info("Send Message ID[" + messageId + "]");
} catch (Throwable e) {
throw new RuntimeException("Failed to send MQ message", e);
}
judgeUserStatus(userId2);
//从数据源B的帐户存款
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
if (userId2.substring(1,2).equals("1")) {
tradeDao.depositMoneyA(userId2, money, sdf.format(new Date()));
} else {
tradeDao.depositMoneyB(userId2, money, sdf.format(new Date()));
}
//查询余额
String respMsg = null;
if (userId1.substring(1,2).equals("1")) {
respMsg = judgeQueryBalance(userId1, messageId);
} else {
respMsg = judgeQueryBalance(userId2, messageId);
}
return respMsg;
}
对于使用到本地消息表的场景,需要警惕以下几个问题:
注意本地消息日志表尽量不要长时间积压数据,推送成功的数据需要及时删除。
本地消息表的数据在查询并且推送的时候,需要设计最大重试次数上限,达到上限仍然推送失败的记录需要进行预警和人为干预。
如果入库的消息体比较大,查询可能消耗的IO比较大,需要考虑拆分单独的一张消息内容表用于存放消息体内容,而经常更变的列应该单独拆分到另外一张表。
本地消息日志表的设计如下:
CREATE TABLE `txc_undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`xid` varchar(100) NOT NULL COMMENT '全局事务ID',
`branch_id` bigint(20) NOT NULL COMMENT '分支事务ID',
`rollback_info` longblob NOT NULL COMMENT 'LOG',
`status` int(11) NOT NULL COMMENT '状态',
`server` varchar(32) NOT NULL COMMENT '服务器',
PRIMARY KEY (`id`),
KEY `idx_unionkey` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='事务日志表';
总结
解决分布式事务的最佳实践就是:
在单机数据库下很容易维持事务的ACID(Atomicity、Consistency、Isolation和Durability)特性,在分布式系统中规避使用强一致性的分布式事务实现,基本观念就是放弃ACID投奔BASE。
分布式事务本身是一个技术难题,是没有一种完美的方案应对所有场景的,通过上面对比了几种分布式事务解决方案的优缺点,具体还是要根据业务场景去抉择。
推荐使用阿里全局事务服务GTS, GTS可以与RDS、MySQL、PostgreSQL等数据源,SpringCloud、Dubbo、HSF及其他RPC框架,MQ消息队列等中间件产品配合使用,轻松实现分布式数据库事务、多库事务、消息事务、服务链路级事务,保证分布式系统中分布式事务最终一致特性。