
本文列举了一些开源Elasticsearch(ES)相关的常见问题,例如,如何配置索引线程池大小,如何重新分配索引分片,如何批量删除索引等。
常见问题概览
如何配置索引线程池大小?
在YML参数配置中,指定thread_pool.write.queue_size参数的大小即可。具体操作步骤,请参见配置YML参数。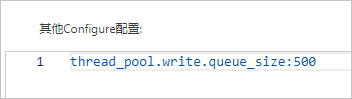
对于6.x以下版本的Elasticsearch集群,需要使用thread_pool.index.queue_size参数。
出现内存溢出OOM(OutOfMemory)的错误,如何处理?
通过以下命令清理缓存,然后观察具体原因,根据原因升配集群或调整业务。
curl -u elastic:<password> -XPOST "localhost:9200/<index_name>/_cache/clear?pretty"变量名 | 说明 |
| 阿里云Elasticsearch实例的密码,为您在创建Elasticsearch实例时设置的密码,或初始化Kibana时指定的密码。 |
| 索引名称。 |
如何手动对shard进行操作?
使用reroute API,或通过Cerebro进行操作。具体操作步骤,请参见Cluster reroute API和Cerebro。
Elasticsearch的缓存清除策略有哪些?
Elasticsearch支持以下三种缓存清除策略:
清除全部缓存
curl localhost:9200/_cache/clear?pretty清除单一索引缓存
curl localhost:9200/<index_name>/_cache/clear?pretty清除多索引缓存
curl localhost:9200/<index_name1>,<index_name2>,<index_name3>/_cache/clear?pretty
如何重新分配索引分片(reroute)?
当出现分片丢失、分片错误等分片问题时,您可以执行以下命令进行reroute操作。
curl -XPOST 'localhost:9200/_cluster/reroute' -d '{
"commands" : [ {
"move" :
{
"index" : "test", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
},
{
"allocate" : {
"index" : "test", "shard" : 1, "node" : "node3"
}
}
]
}'索引查询时,提示statusCode: 500的错误,如何处理?
建议您通过第三方插件进行查询(例如Cerebro):
查询正常:说明该错误大概率是由于索引名称不规范引起的。规范的索引名称只包含英文、下划线和数字,您可以通过修改索引名称来修复此问题。
查询不正常:说明索引或集群本身存在问题。请确保集群中存在该索引,且集群处于正常状态。
如何修改自动创建索引auto_create_index参数?
执行以下命令修改。
PUT /_cluster/settings
{
"persistent" : {
"action": {
"auto_create_index": "false"
}
}
}auto_create_index参数的默认值为false,表示不允许自动创建索引。一般建议您不要调整该值,否则会引起索引太多、索引Mapping和Setting不符合预期等问题。
OSS快照大概需要多久?
在集群的分片数、内存、磁盘和CPU等正常的情况下,80 GB的索引数据进行OSS快照,大约需要30分钟。
创建索引时,如何设置分片数?
建议您将单个分片存储索引数据的大小控制在30 GB以内,不要超过50 GB,否则会极大降低查询性能。根据上述建议,最终分片数量 = 数据总量/30 GB。
适当提升分片数量可以提升建立索引的速度。分片数过多或过少,都会降低查询速度,具体说明如下:
分片数过多会导致需要打开的文件比较多。由于分片是存储在不同机器上的,因此分片数越多,各个节点之间的交互也就越多,导致查询效率降低。
分片数过少会导致单个分片索引过大,降低整体的查询效率。
自建Elasticsearch迁移数据,使用elasticsearch-repository-oss插件遇到如下问题,如何解决?
问题:ERROR: This plugin was built with an older plugin structure. Contact the plugin author to remove the intermediate "elasticsearch" directory within the plugin zip。
解决方案:将elasticsearch改名为elasticsearch-repository-oss, 然后复制到plugins目录下。
如何调整Kibana可视化展示数据的时区?
您可以在Kibana中,通过转换时区来调整服务器时间,如下图(以6.7.0版本为例)。 选择时区如下图所示。
选择时区如下图所示。
Elasticsearch的Term查询适用于哪种类型的数据?
Term为单词级别的查询,这些查询通常用于结构化的数据,例如number、date、keyword等,而不是text。
全⽂文本查询之前要先对文本内容进行分词,而单词级别的查询直接在相应字段的反向索引中精确查找,单词级别的查询一般用于数值、日期等类型的字段上。
使用ES的别名(aliases)功能需要注意哪些问题?
需要将别名里索引的分片控制在1024个以内。
在查询过程中,出现报错too_many_buckets_exception,如何处理?
报错:"type": "too_many_buckets_exception", "reason": "Trying to create too many buckets. Must be less than or equal to: [10000] but was [10001]
问题分析与解决方案:请参见控制聚合中创建的桶数。除了调整业务聚合的size大小,您还可以参见Increasing max_buckets for specific Visualizations来处理。
如何批量删除索引?
默认情况下,Elasticsearch不允许批量删除索引,需要通过以下命令手动开启。开启后,您可以通过通配符进行批量删除操作。
PUT /_cluster/settings
{
"persistent": {
"action.destructive_requires_name": false
}
}script.painless.regex.enabled参数能否修改?
此参数默认值是false,不建议修改。如果要在painless脚本中使用正则表达式,需要在elasticsearch.yml中设置script.painless.regex.enabled参数为true。由于正则表达式会消耗大量资源,官方不建议使用,因此没有打开此参数。
如何修改Elasticsearch的mapping、主分片和副本分片数量?
已经创建的索引修改mapping,建议通过reindex重建索引。
说明mapping中支持的字段类型,请参见Data field type。
已经创建的索引无法修改主分片,建议通过reindex重建索引修改。
说明建议您在创建索引前规划好分片数,减少后期调整。
已经创建的索引修改副本数,可以参考以下命令修改:
PUT test/_settings { "number_of_replicas": 0 }
ES如何设置存储某个字段?
除_source字段,默认情况下,ES不会单独存储字段值。如果需要独立存储某些字段,可以在索引的映射中将字段的store属性设置为true。
ES的_source字段包含原始JSON文档,提供了从原始文档检索任何字段的能力。通常不推荐开启字段存储,以免增加磁盘空间的使用。
以存储my_field字段为例:
PUT / my_index {
"mappings": {
"properties": {
"my_field": {
"type": "text",
"store": true
}
}
}
}ES如何设置某个字段是否可以参与聚合?
字段是否可以聚合通常取决于字段的类型和是否有相关的字段数据(doc_values或fielddata)可用。
数字字段、日期字段和keyword类型字段,默认使用doc_values,默认情况下可以聚合。
说明doc_values是专为排序、聚合和脚本操作优化的列存储格式。
text类型字段,默认情况下不支持聚合。如果您需要对text字段进行聚合,必须在映射中启用fielddata。
说明开启fielddata会显著增加内存使用,因为它会把所有的文本数据加载到内存中。
PUT /my_index{ "mappings": { "properties": { "my_text_field": { "type": "text", "fielddata": true } } } }如果您不希望某个字段参与聚合,可以根据您的应用逻辑选择以下任一方式:
通过设置enabled属性为false来排除整个对象字段。
选择不将非聚合字段包含在文档中。
配置ES时遇到报错Unknown char_filter type [stop] for ** ,如何处理?
在配置ES时遇到报错Unknown char_filter type [stop] for ** ,表明您尝试在char_filter部分使用stop类型,但实际上stop是一个Token Filter而非Character Filter。
解决方法如下:
更正配置位置:如果您意图使用停用词过滤器,请将stop配置移至analyzer配置的filter部分,而非
char_filter。停用词过滤器用于从Token流中移除指定的停用词列表中的词语。示例:
"settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "standard", "filter": [ // 正确位置:在filter数组内 "lowercase", "stop" // 使用stop Token Filter ] } }, "filter": { // 定义stop Token Filter的具体配置(如有必要) "stop": { "type": "stop", "stopwords": "_english_" // 或自定义停用词列表 } } } }检查类型名称:确认其他配置如
tokenizer或char_filter中是否正确的指定类型名称,避免类似的类型误用。请根据您的实际需求调整配置,确保
char_filter、tokenizer和filter各部分都使用了正确的组件类型。