基于DataWorks的大数据一站式开发及数据治理
基于DataWorks做大数据一站式开发,包含数据实时采集到kafka通过实时计算对数据进行ETL写入 HDFS,使用Hive进行数据分析。通过DataWorks进行数据治理,数据地图查看数据信息和血缘关系, 数据质量监控异常和报警。
直达最佳实践
更多最佳实践
解决问题
日志采集、处理及分析
日志使用Flink实时写入HDFS
日志数据实时ETL
日志HIVE分析
基于DataWorks一站式开发
数据治理
方案优势
大数据一站式开发,完善的数据治理能力。
性能优越:高吞吐,高扩展性。
安全稳定:Exactly-Once,故障自动恢复,资源隔离。
简单易用:SQL语言,在线开发,全面支持UDX。
功能强大:支持SQL进行实时及离线数据清洗、数据分析、数据同步、异构数据源计算等DataLake相关功能,以及各种流式及静态数据源关联查询。
安全:原生的多租户系统,以项目进行隔离,所有计算任务在安全沙箱中运行。
部署架构图
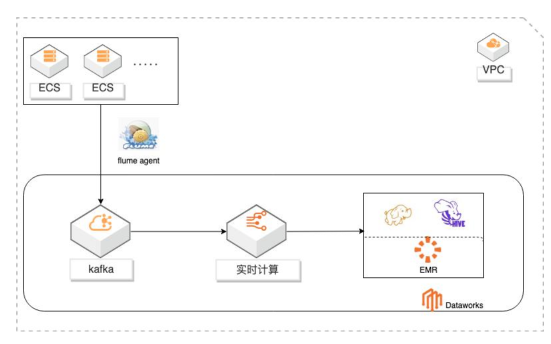
相关产品
文件存储HDFS
阿里云文件存储HDFS(Apsara File Storage for HDFS)提供标准的HDFS访问协议,用户无需对现有大数据分析应用做任何修改,即可使用具备无限容量及性能扩展、单一命名空间、高可靠和高可用等特性的分布式文件系统。
更多关于文件存储HDFS的介绍,参见文件存储HDFS产品详情页。
实时计算
实时计算(AlibabaCloudRealtimeCompute,PoweredbyVerverica)是阿里云提供的基于ApacheFlink构建的企业级大数据计算平台。在PB级别的数据集上可以支持亚秒级别的处理延时,赋能用户标准实时数据处理流程和行业解决方案;支持DatastreamAPI作业开发,提供了批流统一的FlinkSQL,简化BI场景下的开发;可与用户已使用的大数据组件无缝对接,更多增值特性助力企业实时化转型。
更多关于实时计算的介绍,参见实时计算产品详情页。
E-MapReduce
阿里云E-MapReduce (EMR) 是构建在阿里云云服务器ECS上的开源Hadoop、Spark、HBase、Hive、Flink生态大数据PaaS产品。提供用户在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。
更多关于E-MapReduce的介绍,参见E-MapReduce产品详情页。
DataWorks
DataWorks基于MaxCompute/EMR/MC-Hologres等大数据计算引擎,为客户提供专业高效、安全可靠的一站式大数据开发与治理平台,自带阿里巴巴数据中台与数据治理最佳实践,赋能各行业数字化转型。每天阿里巴巴集团内部有数万名数据/算法工程师正在使用DataWorks,承担集团99%数据业务构建。
更多关于DataWorks的介绍,参见DataWorks产品详情页。
- 本页导读