Delta Lake 快速开始二
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
本文介绍如何创建数据库、表批读写、表流读写、表删除、更新、合并以及版本控制等功能。
前提条件
通过主账号登录阿里云 Databricks控制台。
已创建集群,具体请参见创建集群。
已使用OSS管理控制台创建非系统目录存储空间,详情请参见控制台创建存储空间。
首次使用DDI产品创建的Bucket为系统目录Bucket,不建议存放数据,您需要再创建一个Bucket来读写数据。
DDI访问OSS路径结构:oss://BucketName/Object
BucketName为您的存储空间名称。
Object为上传到OSS上的文件的访问路径。
例:读取在存储空间名称为databricks-demo-hangzhou文件路径为demo/The_Sorrows_of_Young_Werther.txt的文件
// 从oss地址读取文本文档
val dataRDD = sc.textFile("oss://databricks-demo-hangzhou/demo/The_Sorrows_of_Young_Werther.txt")创建Notebook、导入数据、进行数据分析
创建数据库
不指定路径创建数据库,创建的数据库会存储在当前集群hive路径中
%pyspark # 创建数据库目录,你也可以选择自定义目录 database="db_test" spark.sql("DROP DATABASE IF EXISTS {} CASCADE".format(database)) spark.sql("CREATE DATABASE {}".format(database)) spark.sql("USE {}".format(database))指定路径创建数据库,可以使用OSS路径创建
%pyspark database="db_dome" #指定路径创建库和表;本掩饰路径为dome路径,您可以使用真实的路径 location='oss://dome-test/case6/'; spark.sql("DROP DATABASE IF EXISTS {} CASCADE".format(database)) spark.sql("CREATE DATABASE {} location 'oss://dome-test/case6/' ".format(database)) spark.sql("USE {}".format(database))
说明您可以在Databricks数据洞察控制台中的元数据管理中查看创建的数据库和数据表
创建delta表/delta分区表/parquet格式表/元存储表
%pyspark from pyspark.sql.functions import expr from pyspark.sql.functions import from_unixtime, to_date # 定义路径 inputPath = "/dome-test/events_data.json" deltaPath = "/dome-test/delta/events" partitionDeltaPath = "/dome-test/delta/events_partition" parquetPath = "/dome-test/parquet/events" jsonPath = "/dome-test/json/events" events = spark.read \ .option("inferSchema", "true") \ .json(inputPath) \ .withColumn("date", to_date('date', 'yyyy-MM-dd')) events.show() events.printSchema() # 创建delta表/delta分区表/parquet格式表/元存储表 events.write.format("delta").mode("overwrite").save(deltaPath) events.write.format("delta").mode("overwrite").partitionBy("date").save(partitionDeltaPath) events.write.format("parquet").mode("overwrite").save(parquetPath) events.write.format("delta").saveAsTable("events")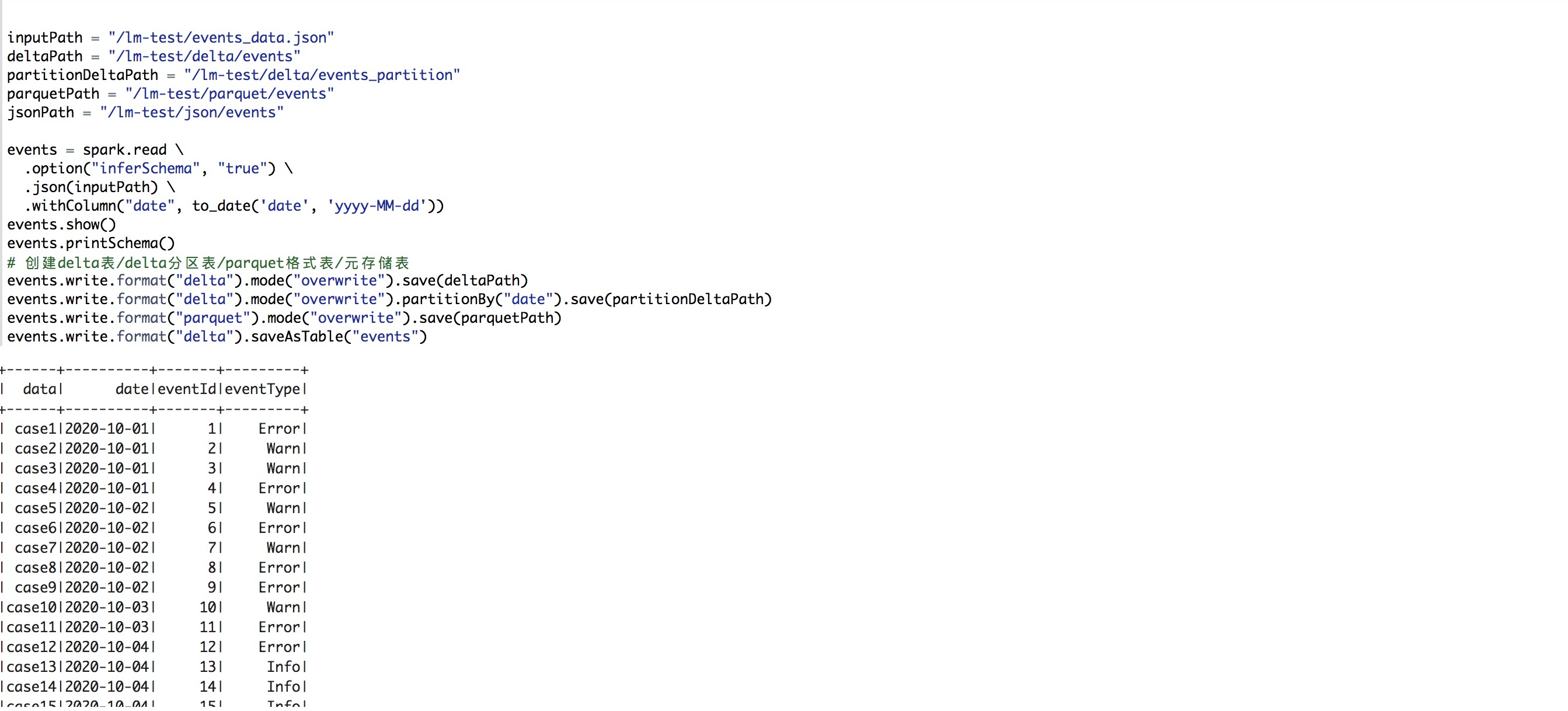
将parquet文件转换为delta
%sql --可以将parquet文件转换为delta SELECT * FROM parquet.`/dome-test/parquet/events`; CONVERT TO DELTA parquet.`/dome-test/parquet/events`; SELECT * FROM delta.`/dome-test/parquet/events`;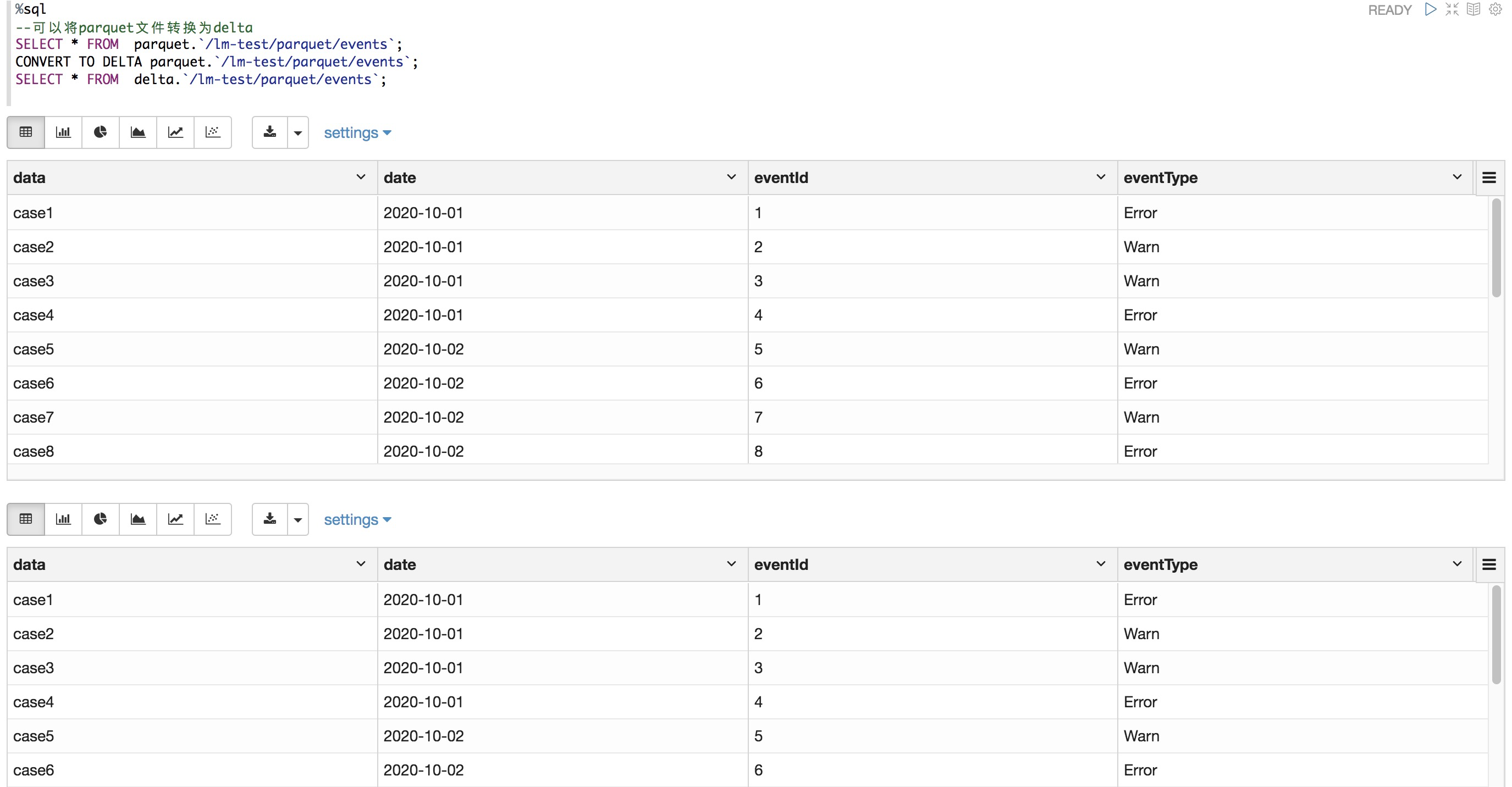
将delta文件还原为parquet文件
清空delta数据
%sql -- 可以将delta表还原为parquet表,需要先vacuum操作清空delta数据文件,然后删除_delta_log目录 SELECT * FROM delta.`/dome-test/parquet/events`; set spark.databricks.delta.retentionDurationCheck.enabled = false; vacuum delta.`/dome-test/parquet/events` retain 0 hours前往OSS路径中找到_delta_log目录并删除
查询转换之后的delta表数据
%sql -- 此操作前要删除表对应的_delta_log目录 SELECT * FROM delta.`/dome-test/parquet/events`;
查询表
%sql select * from events;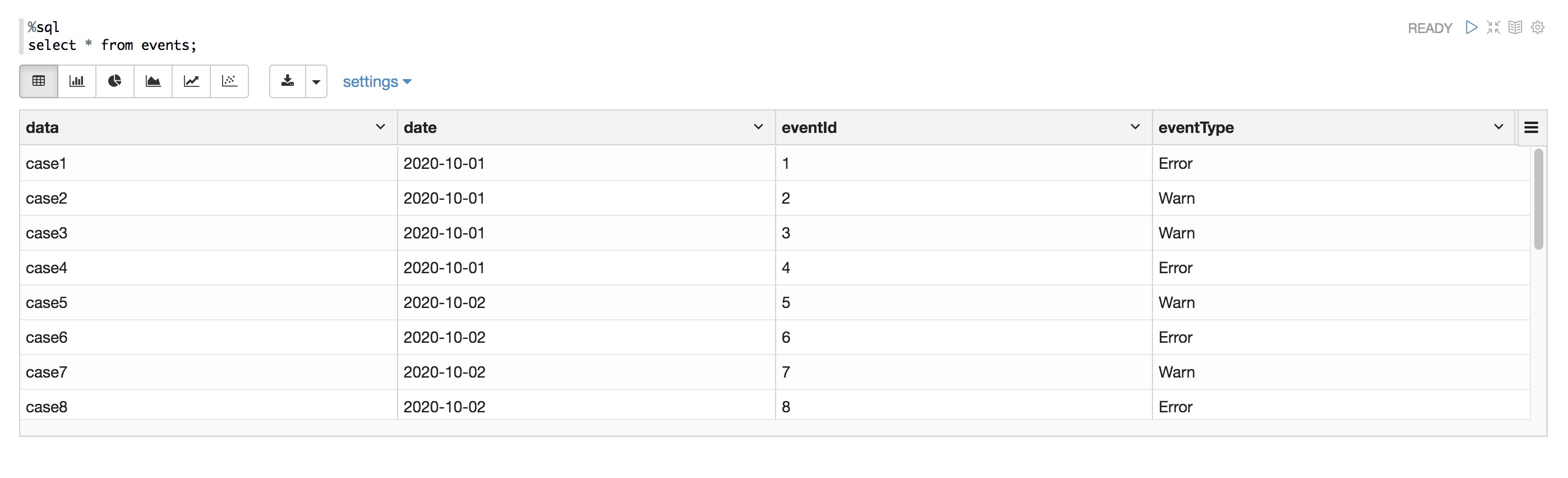
通过元存储创建表并显示表中内容
%pyspark # 通过路径在元存储中创建表 spark.sql("CREATE TABLE IF NOT EXISTS events_partition USING DELTA LOCATION '/dome-test/delta/events_partition'") # 从元存储和路径中读取表 df1 = spark.table("events") df2 = spark.read.format("delta").load("/dome-test/delta/events_partition") df1.show() df2.show()查询表的旧快照
%sql DESCRIBE HISTORY events; -- 您需要将以下日期时间修改为具体日期 SELECT * FROM events TIMESTAMP AS OF '2020-12-09 19:15:30'; SELECT * FROM events VERSION AS OF 0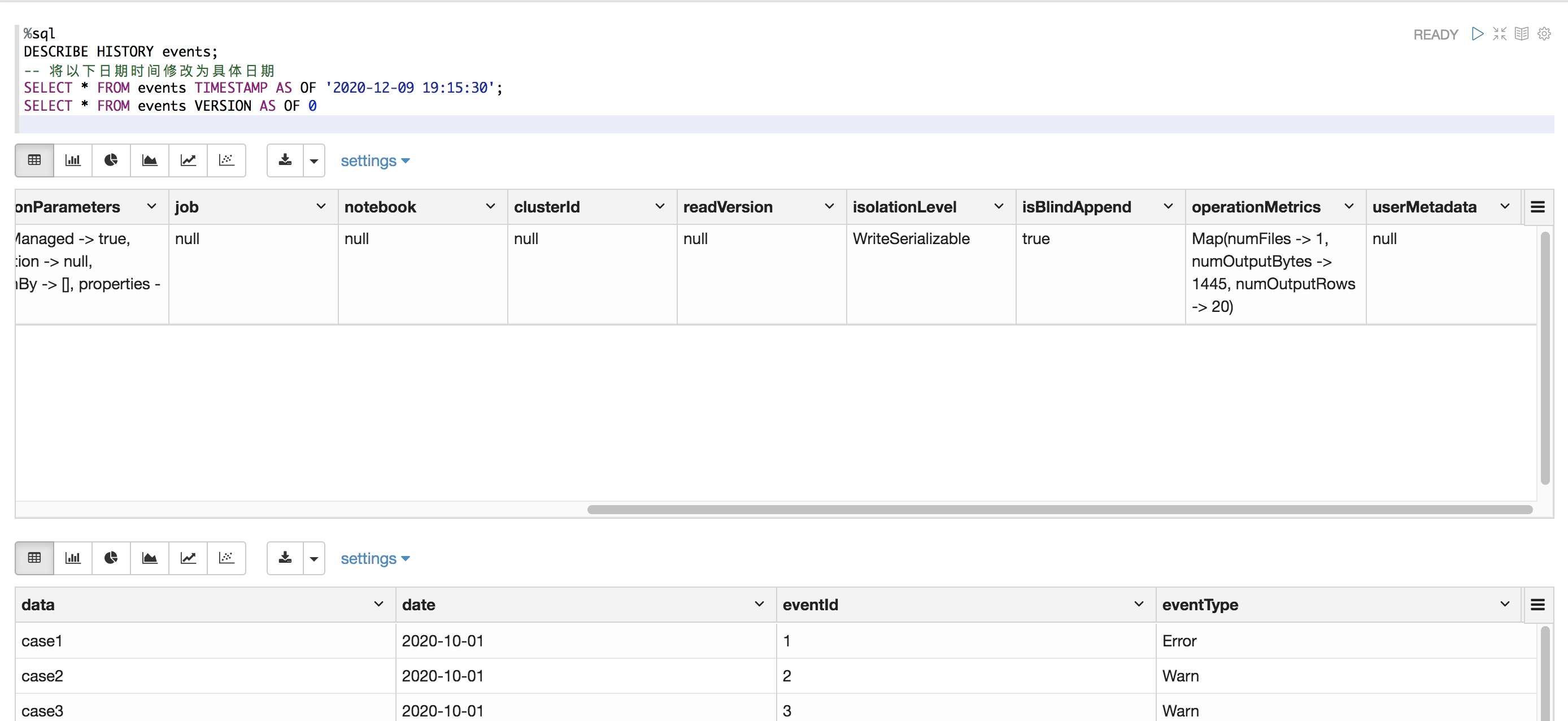
更新表中数据,然后查询表更改历史时间戳和版本信息
%sql -- 更新表中数据,然后查询表更改历史时间戳和版本信息 UPDATE events SET data = 'update-case1' where eventId = 1; UPDATE delta.`/dome-test/delta/events` SET data = 'update-case1' where eventId = 1; DESCRIBE HISTORY delta.`/dome-test/delta/events`;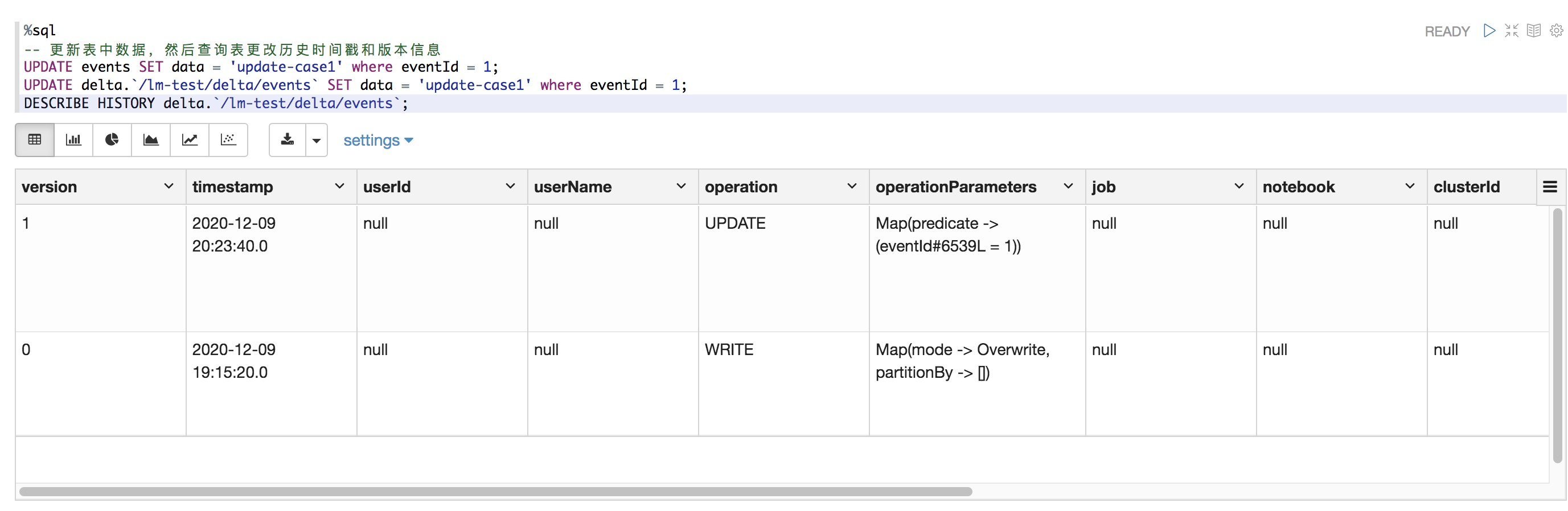
通过不同时间戳表达式读取历史版本
%pyspark # 可以读取历史版本数据,time travel,以下时间为对应表的历史时间 d1 = spark.read.format("delta").option("timestampAsOf", "2020-12-09 20:23:40").load("/dome-test/delta/events") d11 = spark.read.format("delta").load("/dome-test/delta/events@20201209202340000") d2 = spark.read.format("delta").option("versionAsOf", 0).load("/dome-test/delta/events") d22 = spark.read.format("delta").load("/dome-test/delta/events@v0") # 读取最新版本数据或者其它版本数据 latest_version = spark.sql("SELECT * FROM (DESCRIBE HISTORY delta.`/dome-test/delta/events`)").collect() df = spark.read.format("delta").option("versionAsOf", latest_version[0][0]).load("/dome-test/delta/events") d1.show() d11.show() d2.show() d22.show() df.show()
向表中追加数据
%pyspark # 往表中追加数据 df = spark.createDataFrame([("case21", '2020-10-12', 21, 'INFO'),("case22", '2020-10-13', 22, 'INFO')], ['data', 'date', 'eventId', 'eventType']) df1 = df.select('data', to_date('date', 'yyyy-MM-dd').alias('date'), 'eventId', 'eventType') df1.write.format("delta").mode("append").saveAsTable("events") spark.table("events").show(30)
替换部分数据
%pyspark df = spark.createDataFrame([("case21", '2020-10-12', 21, 'INFO'),("case22", '2020-10-13', 22, 'INFO')], ['data', 'date', 'eventId', 'eventType']) df1 = df.select('data', to_date('date', 'yyyy-MM-dd').alias('date'), 'eventId', 'eventType') # 可以替换分区部分数据(replaceWhere中字段必须是分区字段);此处替换大于等于10-4的数据,并将10-12、10-13号的数据填入 df1.write.format("delta").mode("overwrite").option("replaceWhere", "date >= '2020-10-4'").saveAsTable("events_partition") spark.table("events_partition").show(50)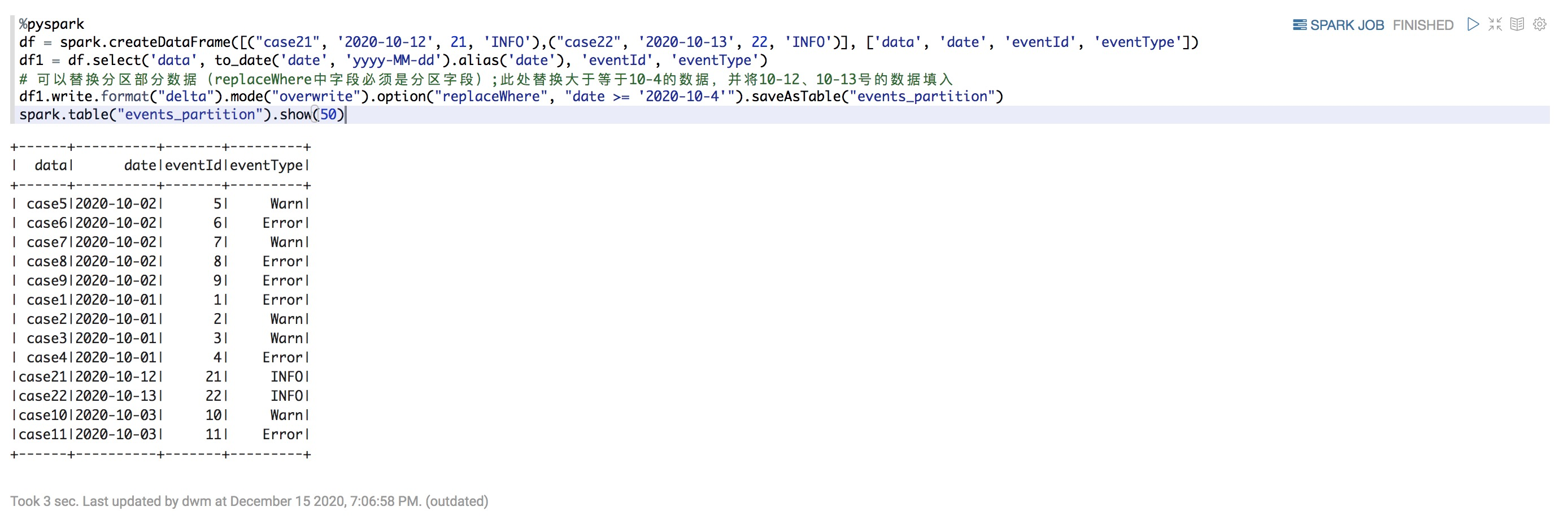
添加列和修改列
%sql ALTER TABLE events ADD COLUMNS (name string COMMENT '名称' FIRST); ALTER TABLE events CHANGE COLUMN name COMMENT '姓名';重写表
修改表中字段的类型或名称需要重写表,需要加上overwriteSchema选项
%pyspark # 修改表中字段的类型或者名称需要重写表,需要加上overwriteSchema选项 spark.read.table("events").withColumnRenamed("name", "fullname") \ .write.format("delta").mode("overwrite") \ .option("overwriteSchema", "true") \ .saveAsTable("events")%pyspark from pyspark.sql.functions import col spark.read.table("events").withColumn("fullname2", col("fullname").cast("int")) \ .write.format("delta").mode("overwrite") \ .option("overwriteSchema", "true") \ .saveAsTable("events")展示历史版本表
%sql describe detail events; describe history events;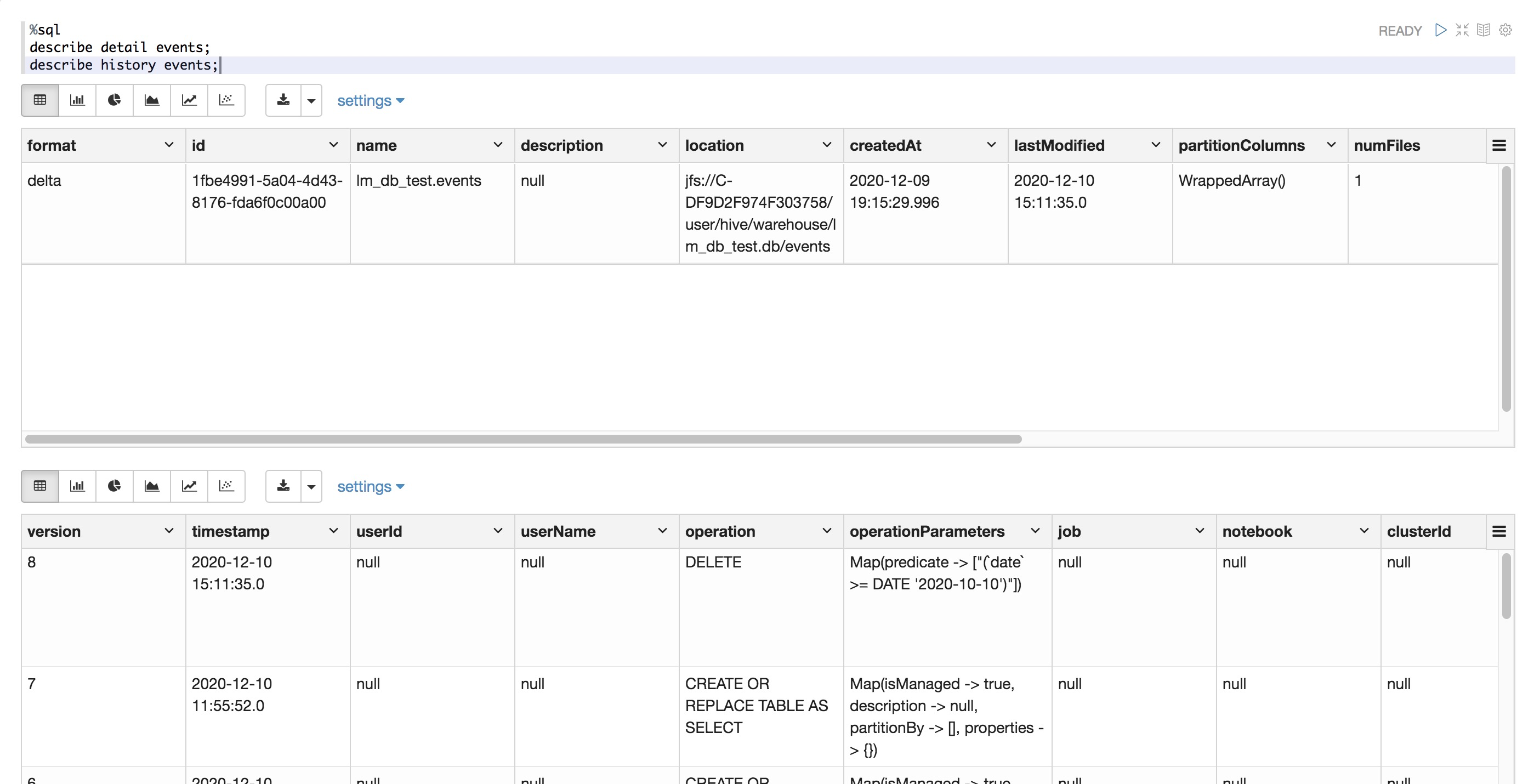
查询版本为2的表
%sql select * from events@v2;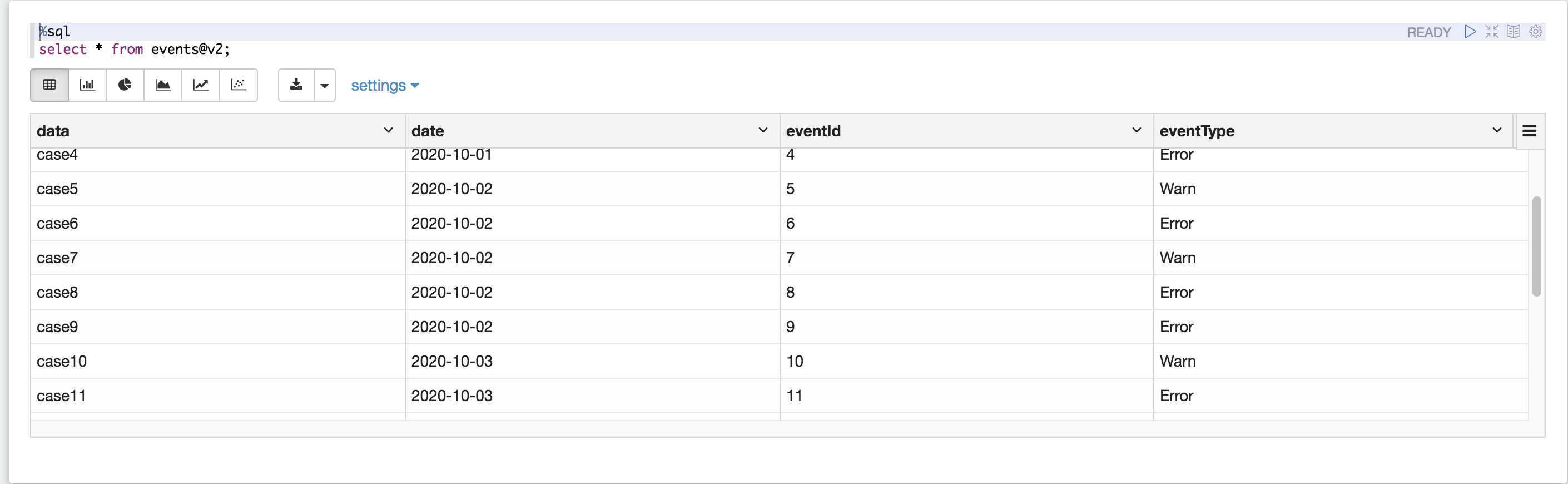
查询日期大于等于10月10号的数据
%sql delete from events where date >= '2020-10-10';从结构化的输入流中读取数据,经过处理后结构化流输出到delta文件
%pyspark # 从结构化的输入流中读取数据,经过处理后结构化流输出到delta文件 spark.readStream.format("delta").table("events").groupBy("date").count() \ .writeStream.format("delta").outputMode("complete").option("checkpointLocation", "/dome-test/delta/eventsByDate/_checkpoints/streaming-agg").start("/dome-test/delta/eventsByDate")查询上述文件输出结果
%pyspark # 上述流文件输出完成之后,可以查询生成结果 events = spark.read.option("inferSchema", "true").format("delta").load("/dome-test/delta/eventsByDate") events.show()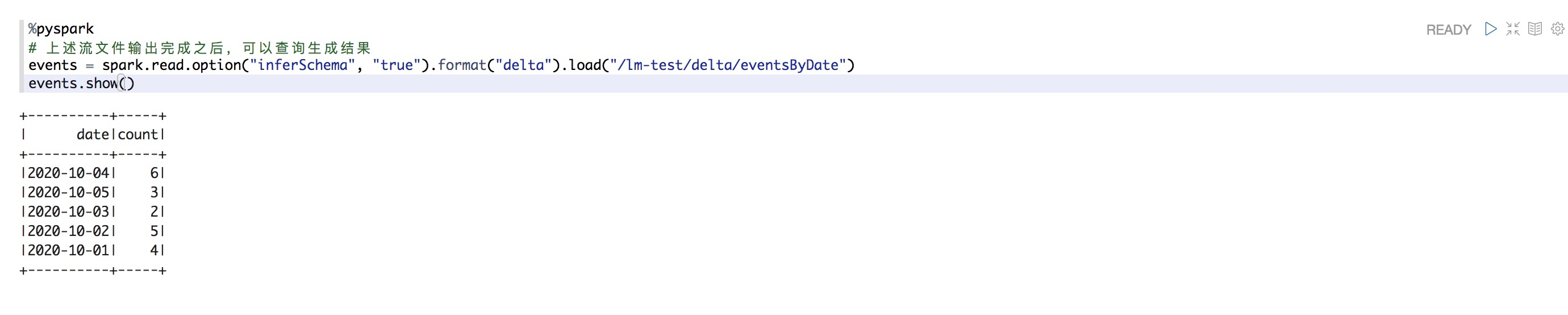
更新表
%pyspark from delta.tables import * from pyspark.sql.functions import * deltaTable = DeltaTable.forPath(spark, "/dome-test/delta/events/") deltaTable.delete("date > '2020-10-03'") deltaTable.toDF().show() deltaTable.update("eventType = 'Error'", { "eventType": "'error'" }) deltaTable.toDF().show()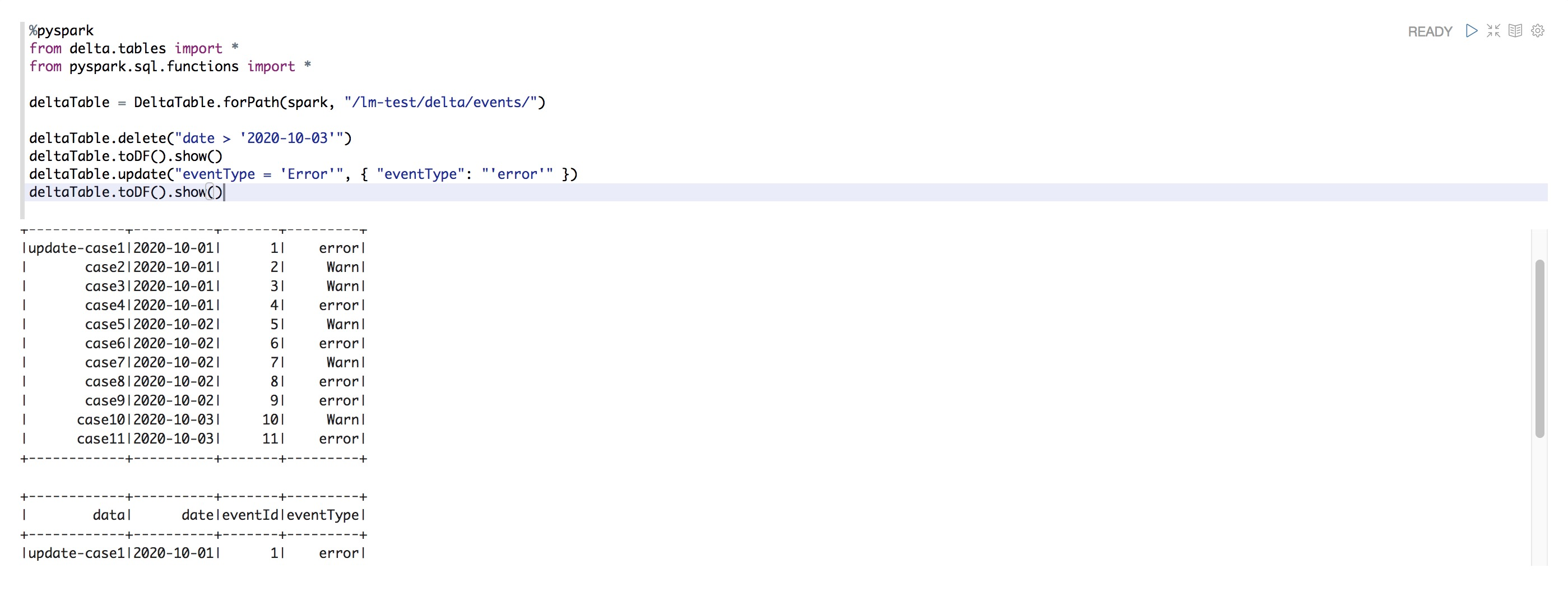
合并表
%pyspark from delta.tables import * deltaTable = DeltaTable.forPath(spark, "/dome-test/delta/events/") df = spark.createDataFrame([("update-case2", '2020-10-12', 2, 'INFO'),("case25", '2020-10-13', 25, 'INFO')], ['data', 'date', 'eventId', 'eventType']) updatesDF = df.select('data', to_date('date', 'yyyy-MM-dd').alias('date'), 'eventId', 'eventType') # 合并表,eventId相等则更新数据,不相等就插入数据 deltaTable.alias("events").merge( updatesDF.alias("updates"), "events.eventId = updates.eventId") \ .whenMatchedUpdate(set = { "data" : "updates.data" } ) \ .whenNotMatchedInsert(values = { "date": "updates.date", "eventId": "updates.eventId", "data": "updates.data", "eventType": "updates.eventType" } ).execute() deltaTable.toDF().show()
- 本页导读 (0)